 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Adversarial Examples Through Deep Neural Network's Response Surface and Uncertainty Regions
Paper and Code
Jun 30, 2021

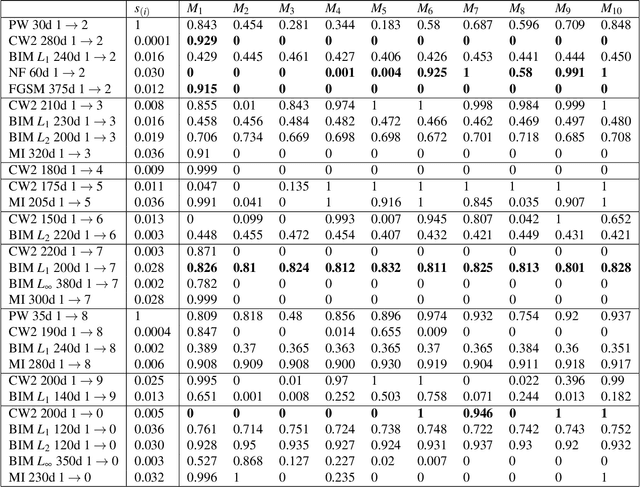
Deep neural network (DNN) is a popular model implemented in many systems to handle complex tasks such as image classification, object recognition, natural language processing etc. Consequently DNN structural vulnerabilities become part of the security vulnerabilities in those systems. In this paper we study the root cause of DNN adversarial examples. We examine the DNN response surface to understand its classification boundary. Our study reveals the structural problem of DNN classification boundary that leads to the adversarial examples. Existing attack algorithms can generate from a handful to a few hundred adversarial examples given one clean image. We show there are infinitely many adversarial images given one clean sample, all within a small neighborhood of the clean sample. We then define DNN uncertainty regions and show transferability of adversarial examples is not universal. We also argue that generalization error, the large sample theoretical guarantee established for DNN, cannot adequately capture the phenomenon of adversarial examples. We need new theory to measure DNN robustness.