 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLand Classification in Satellite Images by Injecting Traditional Features to CNN Models
Jul 21, 2022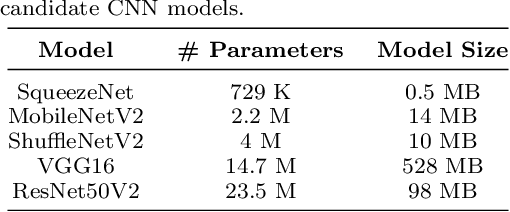



Deep learning methods have been successfully applied to remote sensing problems for several years. Among these methods, CNN based models have high accuracy in solving the land classification problem using satellite or aerial images. Although these models have high accuracy, this generally comes with large memory size requirements. On the other hand, it is desirable to have small-sized models for applications, such as the ones implemented on unmanned aerial vehicles, with low memory space. Unfortunately, small-sized CNN models do not provide high accuracy as with their large-sized versions. In this study, we propose a novel method to improve the accuracy of CNN models, especially the ones with small size, by injecting traditional features to them. To test the effectiveness of the proposed method, we applied it to the CNN models SqueezeNet, MobileNetV2, ShuffleNetV2, VGG16, and ResNet50V2 having size 0.5 MB to 528 MB. We used the sample mean, gray level co-occurrence matrix features, Hu moments, local binary patterns, histogram of oriented gradients, and color invariants as traditional features for injection. We tested the proposed method on the EuroSAT dataset to perform land classification. Our experimental results show that the proposed method significantly improves the land classification accuracy especially when applied to small-sized CNN models.
Aim in Climate Change and City Pollution
Dec 30, 2021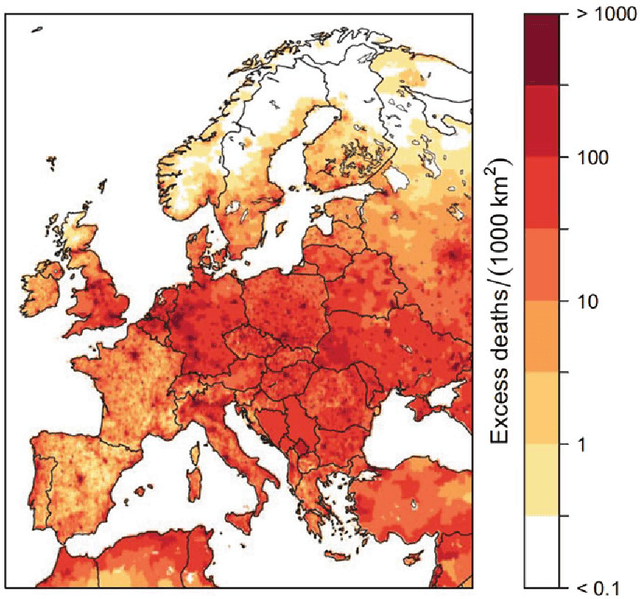
The sustainability of urban environments is an increasingly relevant problem. Air pollution plays a key role in the degradation of the environment as well as the health of the citizens exposed to it. In this chapter we provide a review of the methods available to model air pollution, focusing on the application of machine-learning methods. In fact, machine-learning methods have proved to importantly increase the accuracy of traditional air-pollution approaches while limiting the development cost of the models. Machine-learning tools have opened new approaches to study air pollution, such as flow-dynamics modelling or remote-sensing methodologies.
Interpretable deep-learning models to help achieve the Sustainable Development Goals
Aug 24, 2021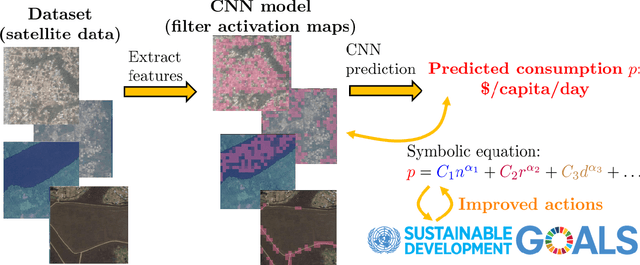
We discuss our insights into interpretable artificial-intelligence (AI) models, and how they are essential in the context of developing ethical AI systems, as well as data-driven solutions compliant with the Sustainable Development Goals (SDGs). We highlight the potential of extracting truly-interpretable models from deep-learning methods, for instance via symbolic models obtained through inductive biases, to ensure a sustainable development of AI.
Recurrent U-net for automatic pelvic floor muscle segmentation on 3D ultrasound
Jul 29, 2021


The prevalance of pelvic floor problems is high within the female population. Transperineal ultrasound (TPUS) is the main imaging modality used to investigate these problems. Automating the analysis of TPUS data will help in growing our understanding of pelvic floor related problems. In this study we present a U-net like neural network with some convolutional long short term memory (CLSTM) layers to automate the 3D segmentation of the levator ani muscle (LAM) in TPUS volumes. The CLSTM layers are added to preserve the inter-slice 3D information. We reach human level performance on this segmentation task. Therefore, we conclude that we successfully automated the segmentation of the LAM on 3D TPUS data. This paves the way towards automatic in-vivo analysis of the LAM mechanics in the context of large study populations.
Towards Autonomous Pipeline Inspection with Hierarchical Reinforcement Learning
Jul 08, 2021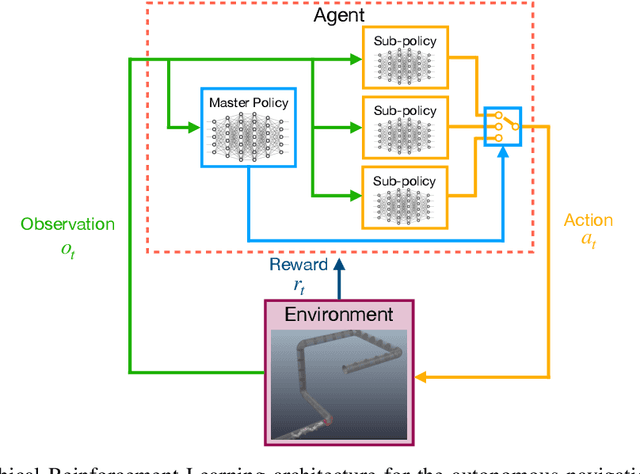
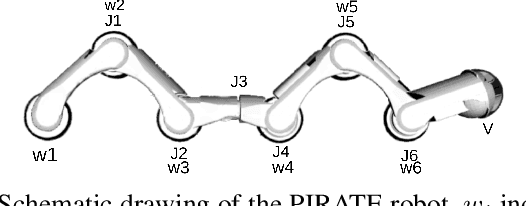
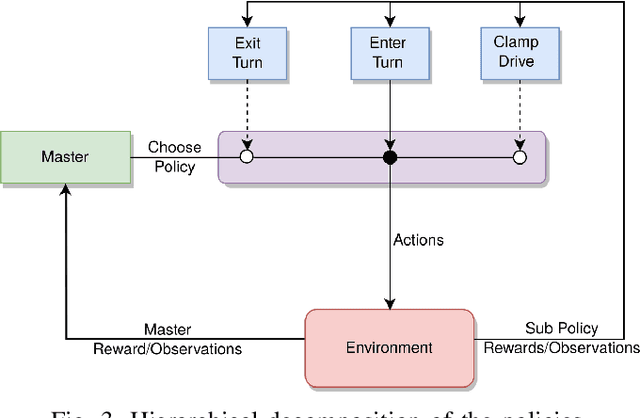
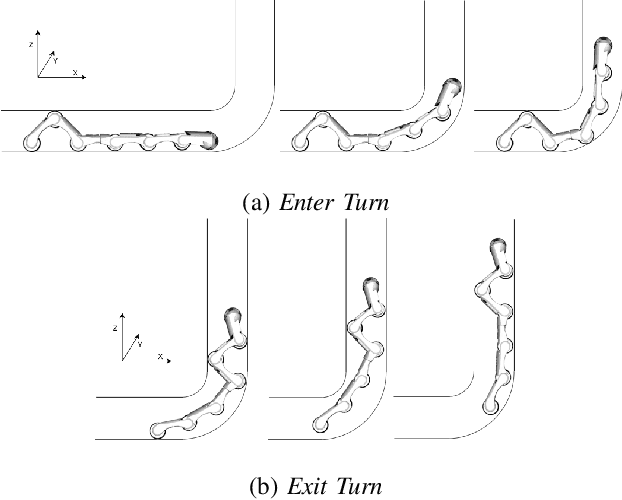
Inspection and maintenance are two crucial aspects of industrial pipeline plants. While robotics has made tremendous progress in the mechanic design of in-pipe inspection robots, the autonomous control of such robots is still a big open challenge due to the high number of actuators and the complex manoeuvres required. To address this problem, we investigate the usage of Deep Reinforcement Learning for achieving autonomous navigation of in-pipe robots in pipeline networks with complex topologies. Moreover, we introduce a hierarchical policy decomposition based on Hierarchical Reinforcement Learning to learn robust high-level navigation skills. We show that the hierarchical structure introduced in the policy is fundamental for solving the navigation task through pipes and necessary for achieving navigation performances superior to human-level control.
Remote sensing, AI and innovative prediction methods for adapting cities to the impacts of the climate change
Jul 06, 2021
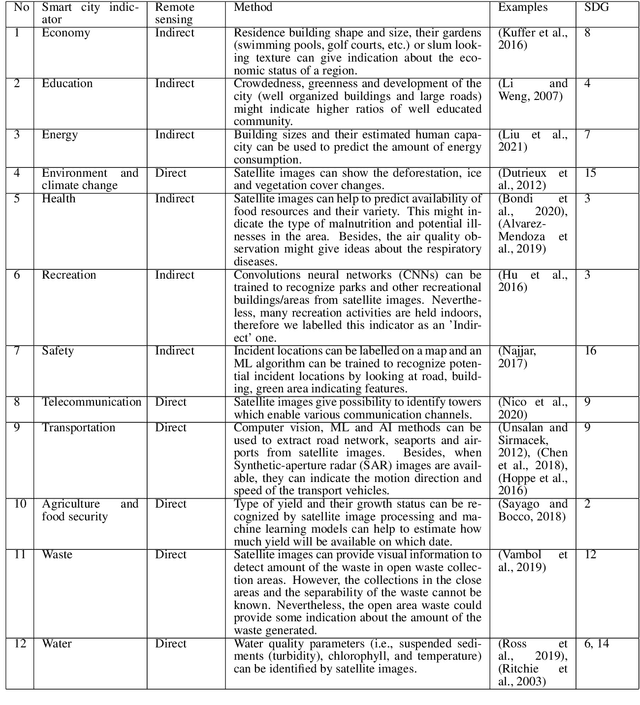


Urban areas are not only one of the biggest contributors to climate change, but also they are one of the most vulnerable areas with high populations who would together experience the negative impacts. In this paper, I address some of the opportunities brought by satellite remote sensing imaging and artificial intelligence (AI) in order to measure climate adaptation of cities automatically. I propose an AI-based framework which might be useful for extracting indicators from remote sensing images and might help with predictive estimation of future states of these climate adaptation related indicators. When such models become more robust and used in real-life applications, they might help decision makers and early responders to choose the best actions to sustain the wellbeing of society, natural resources and biodiversity. I underline that this is an open field and an ongoing research for many scientists, therefore I offer an in depth discussion on the challenges and limitations of AI-based methods and the predictive estimation models in general.
Low-Dimensional State and Action Representation Learning with MDP Homomorphism Metrics
Jul 04, 2021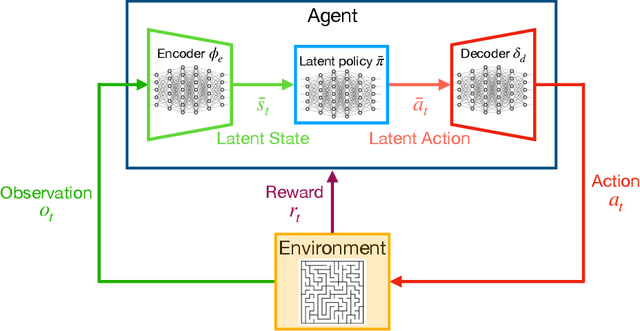

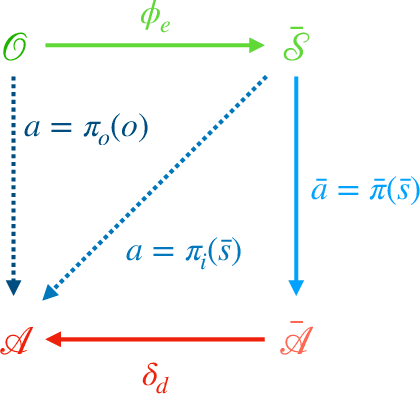
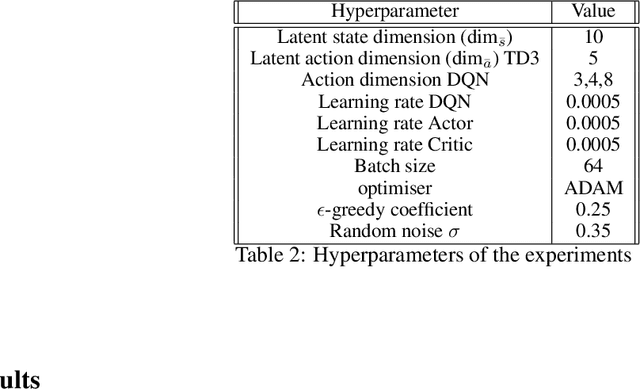
Deep Reinforcement Learning has shown its ability in solving complicated problems directly from high-dimensional observations. However, in end-to-end settings, Reinforcement Learning algorithms are not sample-efficient and requires long training times and quantities of data. In this work, we proposed a framework for sample-efficient Reinforcement Learning that take advantage of state and action representations to transform a high-dimensional problem into a low-dimensional one. Moreover, we seek to find the optimal policy mapping latent states to latent actions. Because now the policy is learned on abstract representations, we enforce, using auxiliary loss functions, the lifting of such policy to the original problem domain. Results show that the novel framework can efficiently learn low-dimensional and interpretable state and action representations and the optimal latent policy.
Low Dimensional State Representation Learning with Robotics Priors in Continuous Action Spaces
Jul 04, 2021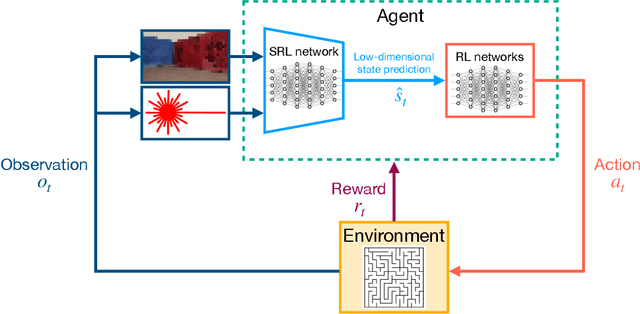

Autonomous robots require high degrees of cognitive and motoric intelligence to come into our everyday life. In non-structured environments and in the presence of uncertainties, such degrees of intelligence are not easy to obtain. Reinforcement learning algorithms have proven to be capable of solving complicated robotics tasks in an end-to-end fashion without any need for hand-crafted features or policies. Especially in the context of robotics, in which the cost of real-world data is usually extremely high, reinforcement learning solutions achieving high sample efficiency are needed. In this paper, we propose a framework combining the learning of a low-dimensional state representation, from high-dimensional observations coming from the robot's raw sensory readings, with the learning of the optimal policy, given the learned state representation. We evaluate our framework in the context of mobile robot navigation in the case of continuous state and action spaces. Moreover, we study the problem of transferring what learned in the simulated virtual environment to the real robot without further retraining using real-world data in the presence of visual and depth distractors, such as lighting changes and moving obstacles.
Low Dimensional State Representation Learning with Reward-shaped Priors
Jul 29, 2020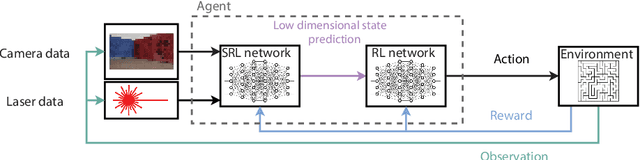

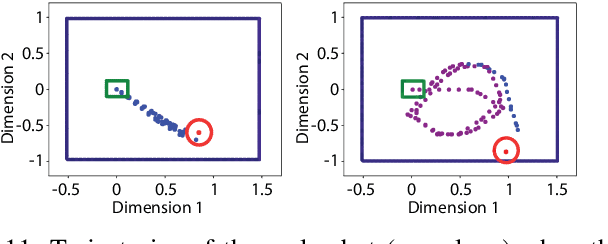
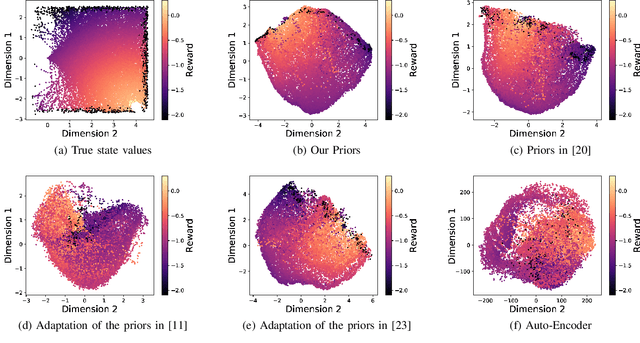
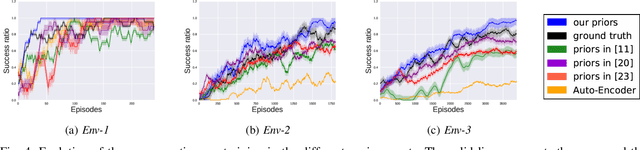
Reinforcement Learning has been able to solve many complicated robotics tasks without any need for feature engineering in an end-to-end fashion. However, learning the optimal policy directly from the sensory inputs, i.e the observations, often requires processing and storage of a huge amount of data. In the context of robotics, the cost of data from real robotics hardware is usually very high, thus solutions that achieve high sample-efficiency are needed. We propose a method that aims at learning a mapping from the observations into a lower-dimensional state space. This mapping is learned with unsupervised learning using loss functions shaped to incorporate prior knowledge of the environment and the task. Using the samples from the state space, the optimal policy is quickly and efficiently learned. We test the method on several mobile robot navigation tasks in a simulation environment and also on a real robot.
On Reward Shaping for Mobile Robot Navigation: A Reinforcement Learning and SLAM Based Approach
Feb 10, 2020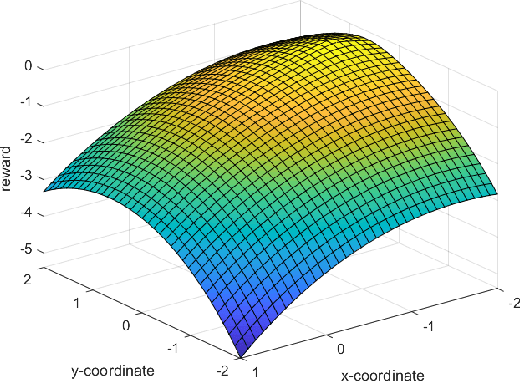
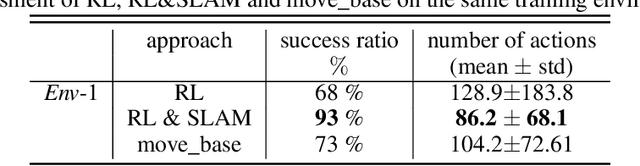
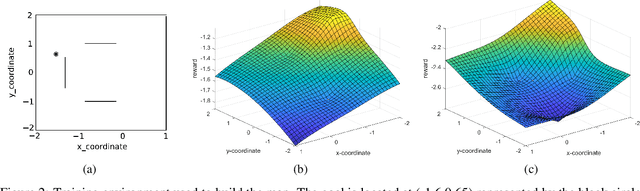

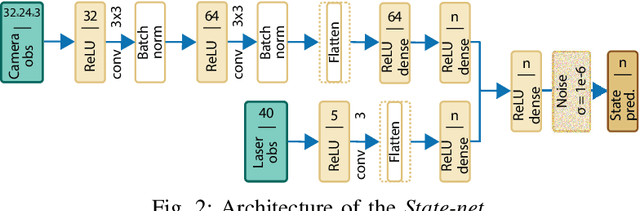
We present a map-less path planning algorithm based on Deep Reinforcement Learning (DRL) for mobile robots navigating in unknown environment that only relies on 40-dimensional raw laser data and odometry information. The planner is trained using a reward function shaped based on the online knowledge of the map of the training environment, obtained using grid-based Rao-Blackwellized particle filter, in an attempt to enhance the obstacle awareness of the agent. The agent is trained in a complex simulated environment and evaluated in two unseen ones. We show that the policy trained using the introduced reward function not only outperforms standard reward functions in terms of convergence speed, by a reduction of 36.9\% of the iteration steps, and reduction of the collision samples, but it also drastically improves the behaviour of the agent in unseen environments, respectively by 23\% in a simpler workspace and by 45\% in a more clustered one. Furthermore, the policy trained in the simulation environment can be directly and successfully transferred to the real robot. A video of our experiments can be found at: https://youtu.be/UEV7W6e6ZqI