 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Dimensional State Representation Learning with Robotics Priors in Continuous Action Spaces
Jul 04, 2021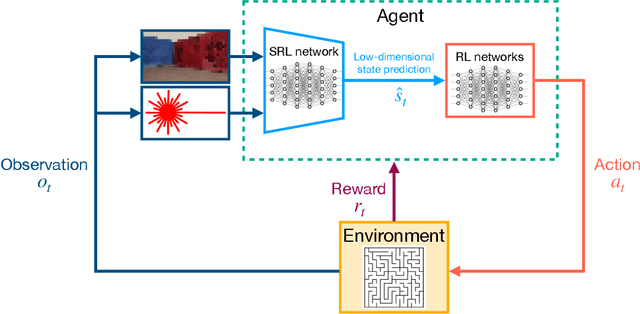

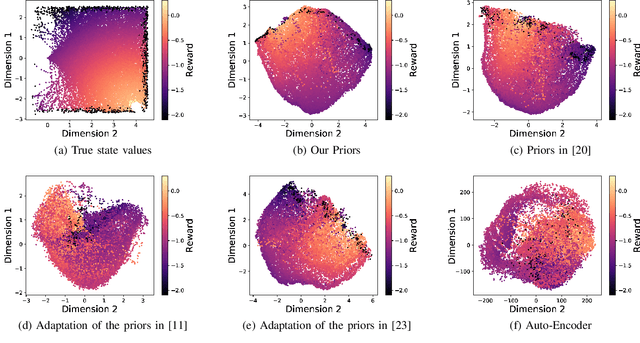
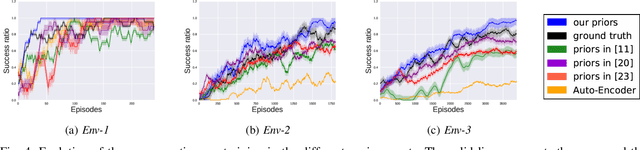
Autonomous robots require high degrees of cognitive and motoric intelligence to come into our everyday life. In non-structured environments and in the presence of uncertainties, such degrees of intelligence are not easy to obtain. Reinforcement learning algorithms have proven to be capable of solving complicated robotics tasks in an end-to-end fashion without any need for hand-crafted features or policies. Especially in the context of robotics, in which the cost of real-world data is usually extremely high, reinforcement learning solutions achieving high sample efficiency are needed. In this paper, we propose a framework combining the learning of a low-dimensional state representation, from high-dimensional observations coming from the robot's raw sensory readings, with the learning of the optimal policy, given the learned state representation. We evaluate our framework in the context of mobile robot navigation in the case of continuous state and action spaces. Moreover, we study the problem of transferring what learned in the simulated virtual environment to the real robot without further retraining using real-world data in the presence of visual and depth distractors, such as lighting changes and moving obstacles.