 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-based Control of UAS Subject to Significant Disturbance
Apr 10, 2025This paper proposes a Reinforcement Learning (RL)-based control framework for position and attitude control of an Unmanned Aerial System (UAS) subjected to significant disturbance that can be associated with an uncertain trigger signal. The proposed method learns the relationship between the trigger signal and disturbance force, enabling the system to anticipate and counteract the impending disturbances before they occur. We train and evaluate three policies: a baseline policy trained without exposure to the disturbance, a reactive policy trained with the disturbance but without the trigger signal, and a predictive policy that incorporates the trigger signal as an observation and is exposed to the disturbance during training. Our simulation results show that the predictive policy outperforms the other policies by minimizing position deviations through a proactive correction maneuver. This work highlights the potential of integrating predictive cues into RL frameworks to improve UAS performance.
External-Wrench Estimation for Aerial Robots Exploiting a Learned Model
Apr 10, 2025This paper presents an external wrench estimator that uses a hybrid dynamics model consisting of a first-principles model and a neural network. This framework addresses one of the limitations of the state-of-the-art model-based wrench observers: the wrench estimation of these observers comprises the external wrench (e.g. collision, physical interaction, wind); in addition to residual wrench (e.g. model parameters uncertainty or unmodeled dynamics). This is a problem if these wrench estimations are to be used as wrench feedback to a force controller, for example. In the proposed framework, a neural network is combined with a first-principles model to estimate the residual dynamics arising from unmodeled dynamics and parameters uncertainties, then, the hybrid trained model is used to estimate the external wrench, leading to a wrench estimation that has smaller contributions from the residual dynamics, and affected more by the external wrench. This method is validated with numerical simulations of an aerial robot in different flying scenarios and different types of residual dynamics, and the statistical analysis of the results shows that the wrench estimation error has improved significantly compared to a model-based wrench observer using only a first-principles model.
Low Dimensional State Representation Learning with Robotics Priors in Continuous Action Spaces
Jul 04, 2021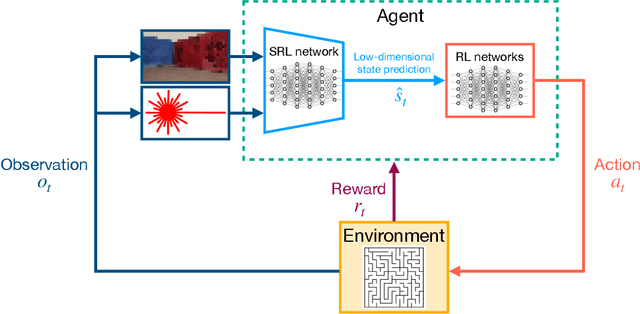

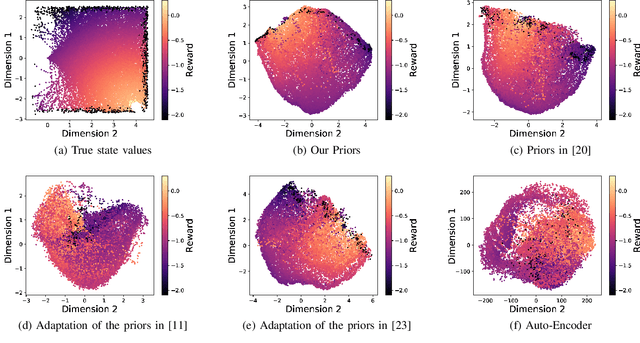
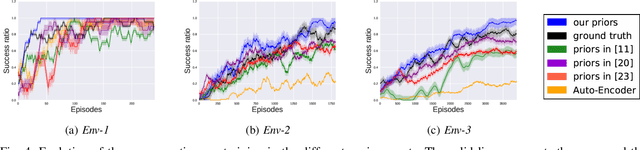
Autonomous robots require high degrees of cognitive and motoric intelligence to come into our everyday life. In non-structured environments and in the presence of uncertainties, such degrees of intelligence are not easy to obtain. Reinforcement learning algorithms have proven to be capable of solving complicated robotics tasks in an end-to-end fashion without any need for hand-crafted features or policies. Especially in the context of robotics, in which the cost of real-world data is usually extremely high, reinforcement learning solutions achieving high sample efficiency are needed. In this paper, we propose a framework combining the learning of a low-dimensional state representation, from high-dimensional observations coming from the robot's raw sensory readings, with the learning of the optimal policy, given the learned state representation. We evaluate our framework in the context of mobile robot navigation in the case of continuous state and action spaces. Moreover, we study the problem of transferring what learned in the simulated virtual environment to the real robot without further retraining using real-world data in the presence of visual and depth distractors, such as lighting changes and moving obstacles.
Low Dimensional State Representation Learning with Reward-shaped Priors
Jul 29, 2020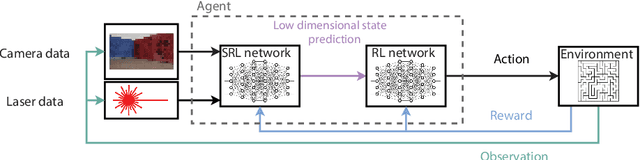

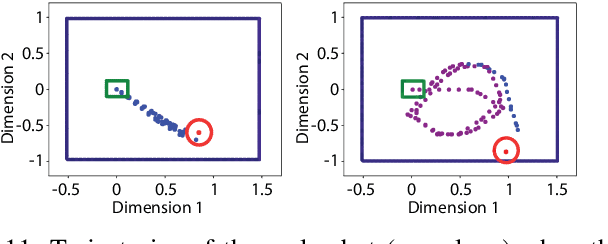
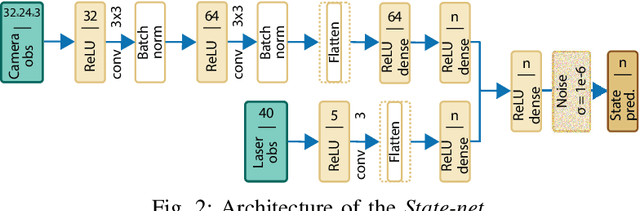
Reinforcement Learning has been able to solve many complicated robotics tasks without any need for feature engineering in an end-to-end fashion. However, learning the optimal policy directly from the sensory inputs, i.e the observations, often requires processing and storage of a huge amount of data. In the context of robotics, the cost of data from real robotics hardware is usually very high, thus solutions that achieve high sample-efficiency are needed. We propose a method that aims at learning a mapping from the observations into a lower-dimensional state space. This mapping is learned with unsupervised learning using loss functions shaped to incorporate prior knowledge of the environment and the task. Using the samples from the state space, the optimal policy is quickly and efficiently learned. We test the method on several mobile robot navigation tasks in a simulation environment and also on a real robot.