 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing expressivity transfer in textless speech-to-speech translation
Oct 11, 2023



Textless speech-to-speech translation systems are rapidly advancing, thanks to the integration of self-supervised learning techniques. However, existing state-of-the-art systems fall short when it comes to capturing and transferring expressivity accurately across different languages. Expressivity plays a vital role in conveying emotions, nuances, and cultural subtleties, thereby enhancing communication across diverse languages. To address this issue this study presents a novel method that operates at the discrete speech unit level and leverages multilingual emotion embeddings to capture language-agnostic information. Specifically, we demonstrate how these embeddings can be used to effectively predict the pitch and duration of speech units in the target language. Through objective and subjective experiments conducted on a French-to-English translation task, our findings highlight the superior expressivity transfer achieved by our approach compared to current state-of-the-art systems.
The VoicePrivacy 2020 Challenge: Results and findings
Sep 01, 2021
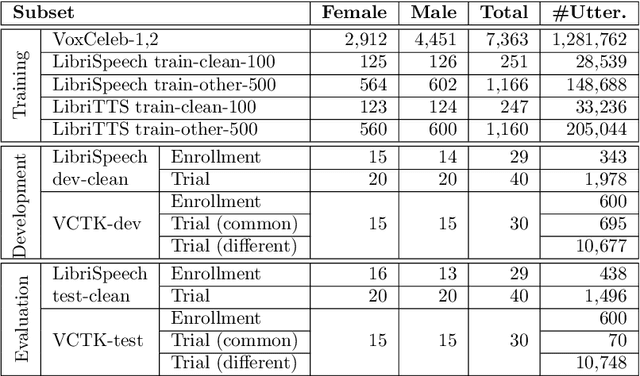
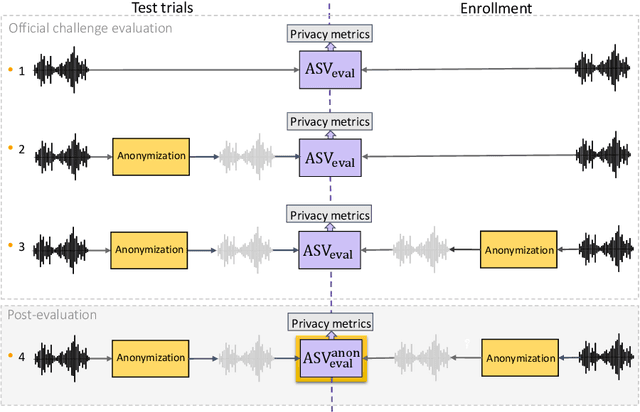
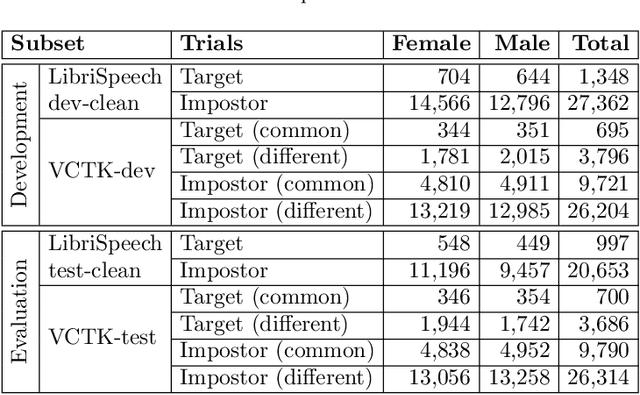
This paper presents the results and analyses stemming from the first VoicePrivacy 2020 Challenge which focuses on developing anonymization solutions for speech technology. We provide a systematic overview of the challenge design with an analysis of submitted systems and evaluation results. In particular, we describe the voice anonymization task and datasets used for system development and evaluation. Also, we present different attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and provide a summary description of the anonymization systems developed by the challenge participants. We report objective and subjective evaluation results for baseline and submitted systems. In addition, we present experimental results for alternative privacy metrics and attack models developed as a part of the post-evaluation analysis. Finally, we summarize our insights and observations that will influence the design of the next VoicePrivacy challenge edition and some directions for future voice anonymization research.