 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenML: An R Package to Connect to the Machine Learning Platform OpenML
May 04, 2017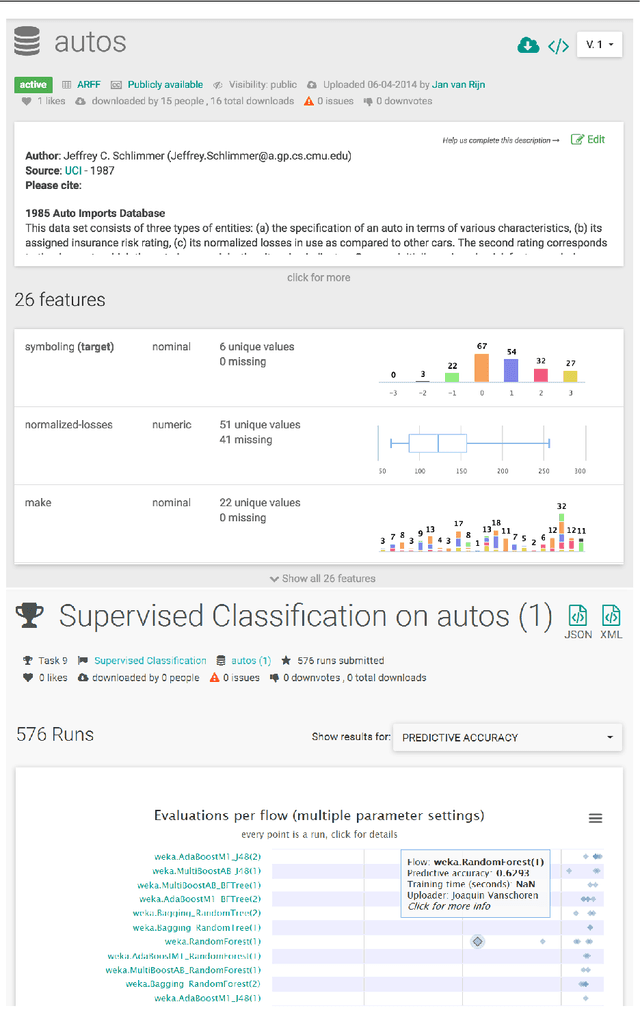
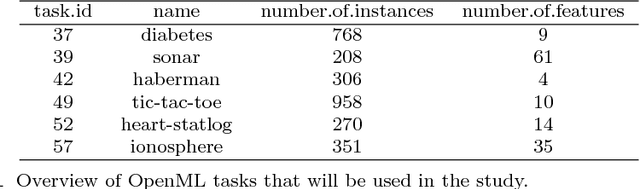
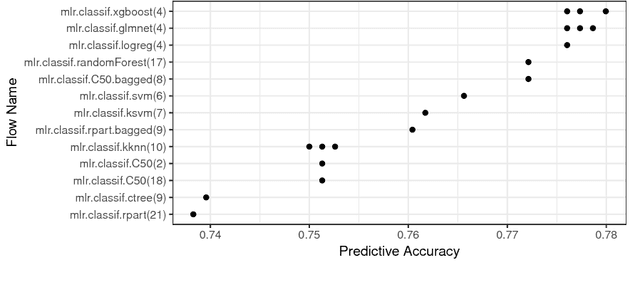
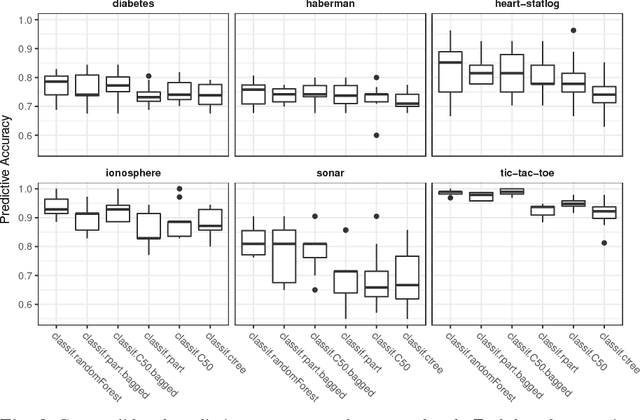
OpenML is an online machine learning platform where researchers can easily share data, machine learning tasks and experiments as well as organize them online to work and collaborate more efficiently. In this paper, we present an R package to interface with the OpenML platform and illustrate its usage in combination with the machine learning R package mlr. We show how the OpenML package allows R users to easily search, download and upload data sets and machine learning tasks. Furthermore, we also show how to upload results of experiments, share them with others and download results from other users. Beyond ensuring reproducibility of results, the OpenML platform automates much of the drudge work, speeds up research, facilitates collaboration and increases the users' visibility online.
An update on statistical boosting in biomedicine
Feb 27, 2017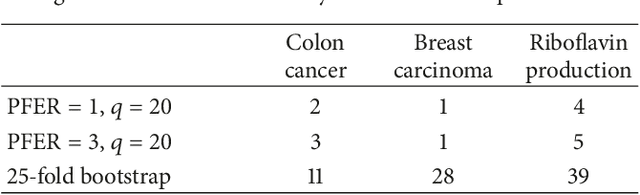
Statistical boosting algorithms have triggered a lot of research during the last decade. They combine a powerful machine-learning approach with classical statistical modelling, offering various practical advantages like automated variable selection and implicit regularization of effect estimates. They are extremely flexible, as the underlying base-learners (regression functions defining the type of effect for the explanatory variables) can be combined with any kind of loss function (target function to be optimized, defining the type of regression setting). In this review article, we highlight the most recent methodological developments on statistical boosting regarding variable selection, functional regression and advanced time-to-event modelling. Additionally, we provide a short overview on relevant applications of statistical boosting in biomedicine.
Stability selection for component-wise gradient boosting in multiple dimensions
Nov 30, 2016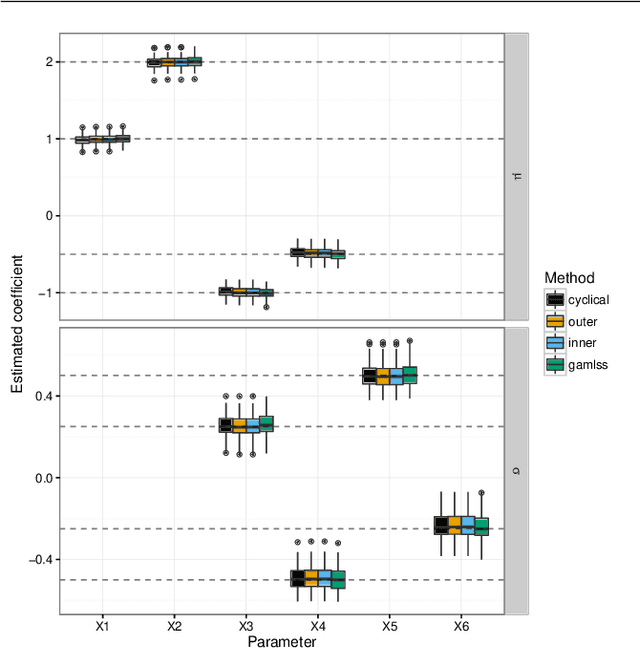
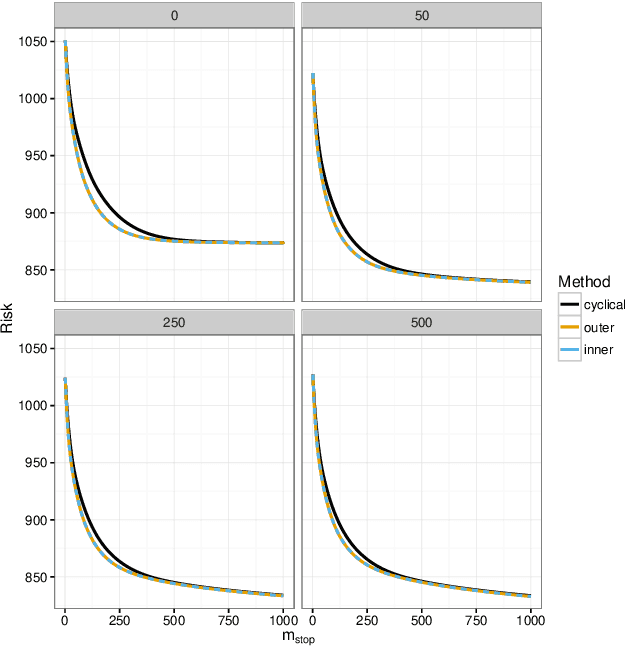

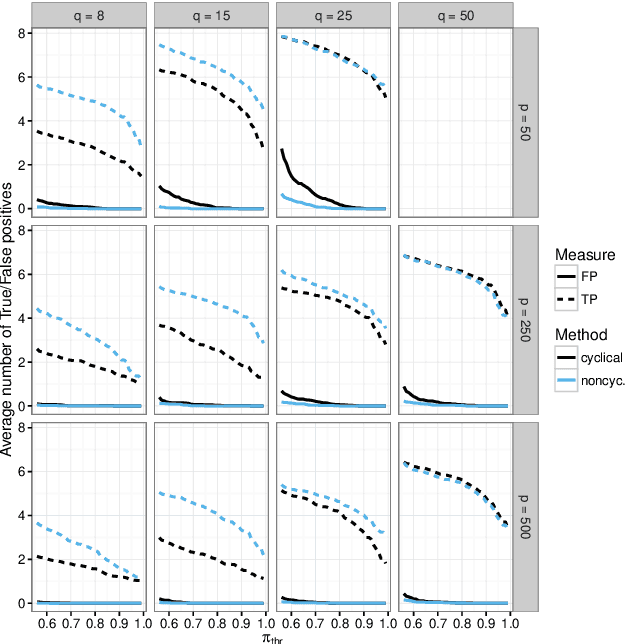
We present a new algorithm for boosting generalized additive models for location, scale and shape (GAMLSS) that allows to incorporate stability selection, an increasingly popular way to obtain stable sets of covariates while controlling the per-family error rate (PFER). The model is fitted repeatedly to subsampled data and variables with high selection frequencies are extracted. To apply stability selection to boosted GAMLSS, we develop a new "noncyclical" fitting algorithm that incorporates an additional selection step of the best-fitting distribution parameter in each iteration. This new algorithms has the additional advantage that optimizing the tuning parameters of boosting is reduced from a multi-dimensional to a one-dimensional problem with vastly decreased complexity. The performance of the novel algorithm is evaluated in an extensive simulation study. We apply this new algorithm to a study to estimate abundance of common eider in Massachusetts, USA, featuring excess zeros, overdispersion, non-linearity and spatio-temporal structures. Eider abundance is estimated via boosted GAMLSS, allowing both mean and overdispersion to be regressed on covariates. Stability selection is used to obtain a sparse set of stable predictors.
Controlling false discoveries in high-dimensional situations: Boosting with stability selection
Nov 05, 2014
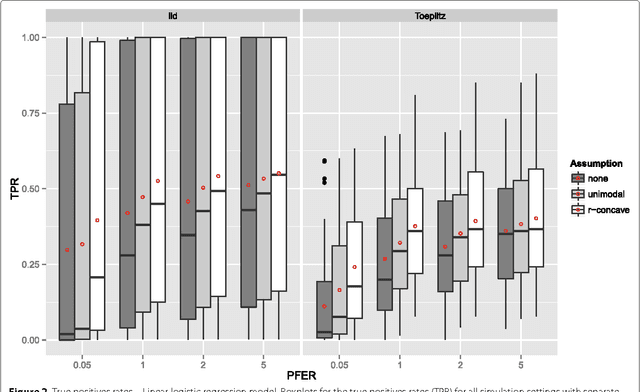
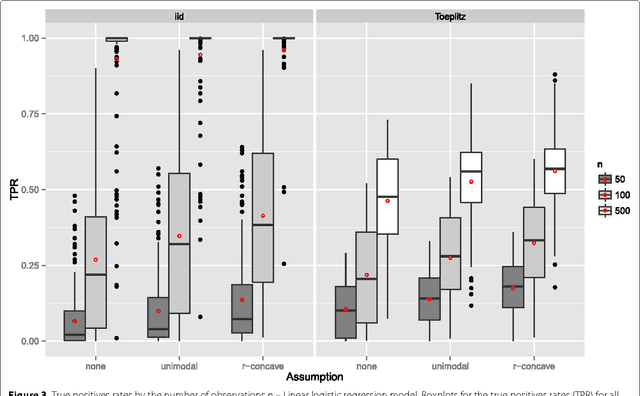
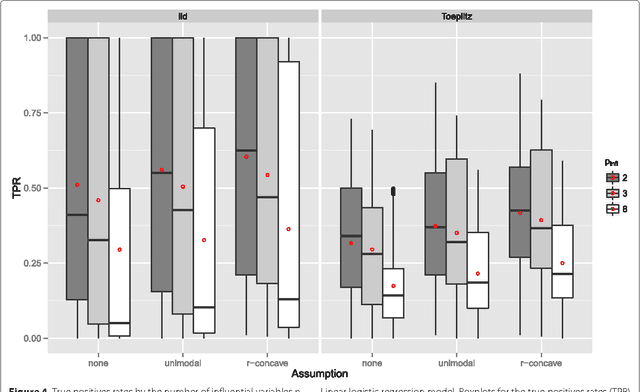
Modern biotechnologies often result in high-dimensional data sets with much more variables than observations (n $\ll$ p). These data sets pose new challenges to statistical analysis: Variable selection becomes one of the most important tasks in this setting. We assess the recently proposed flexible framework for variable selection called stability selection. By the use of resampling procedures, stability selection adds a finite sample error control to high-dimensional variable selection procedures such as Lasso or boosting. We consider the combination of boosting and stability selection and present results from a detailed simulation study that provides insights into the usefulness of this combination. Limitations are discussed and guidance on the specification and tuning of stability selection is given. The interpretation of the used error bounds is elaborated and insights for practical data analysis are given. The results will be used to detect differentially expressed phenotype measurements in patients with autism spectrum disorders. All methods are implemented in the freely available R package stabs.