 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 18, 2024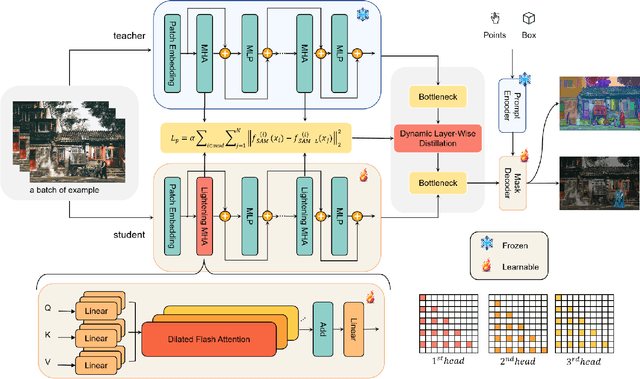
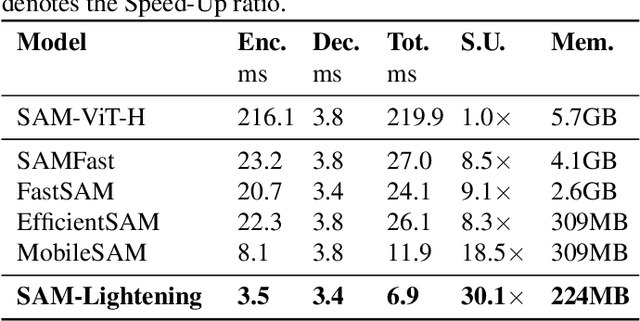

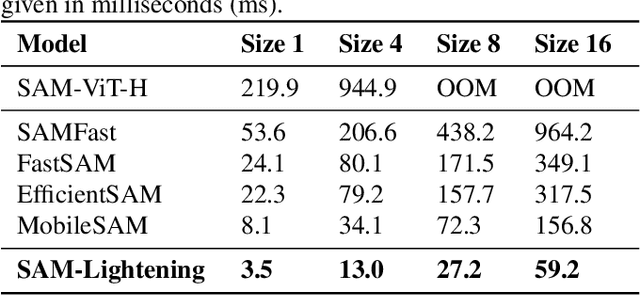
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
MedLocker: A Transferable Adversarial Watermarking for Preventing Unauthorized Analysis of Medical Image Dataset
Mar 20, 2023The collection of medical image datasets is a demanding and laborious process that requires significant resources. Furthermore, these medical datasets may contain personally identifiable information, necessitating measures to ensure that unauthorized access is prevented. Failure to do so could violate the intellectual property rights of the dataset owner and potentially compromise the privacy of patients. As a result, safeguarding medical datasets and preventing unauthorized usage by AI diagnostic models is a pressing challenge. To address this challenge, we propose a novel visible adversarial watermarking method for medical image copyright protection, called MedLocker. Our approach involves continuously optimizing the position and transparency of a watermark logo, which reduces the performance of the target model, leading to incorrect predictions. Importantly, we ensure that our method minimizes the impact on clinical visualization by constraining watermark positions using semantical masks (WSM), which are bounding boxes of lesion regions based on semantic segmentation. To ensure the transferability of the watermark across different models, we verify the cross-model transferability of the watermark generated on a single model. Additionally, we generate a unique watermark parameter list each time, which can be used as a certification to verify the authorization. We evaluate the performance of MedLocker on various mainstream backbones and validate the feasibility of adversarial watermarking for copyright protection on two widely-used diabetic retinopathy detection datasets. Our results demonstrate that MedLocker can effectively protect the copyright of medical datasets and prevent unauthorized users from analyzing medical images with AI diagnostic models.
Physically Adversarial Attacks and Defenses in Computer Vision: A Survey
Nov 03, 2022Although Deep Neural Networks (DNNs) have been widely applied in various real-world scenarios, they are vulnerable to adversarial examples. The current adversarial attacks in computer vision can be divided into digital attacks and physical attacks according to their different attack forms. Compared with digital attacks, which generate perturbations in the digital pixels, physical attacks are more practical in the real world. Owing to the serious security problem caused by physically adversarial examples, many works have been proposed to evaluate the physically adversarial robustness of DNNs in the past years. In this paper, we summarize a survey versus the current physically adversarial attacks and physically adversarial defenses in computer vision. To establish a taxonomy, we organize the current physical attacks from attack tasks, attack forms, and attack methods, respectively. Thus, readers can have a systematic knowledge about this topic from different aspects. For the physical defenses, we establish the taxonomy from pre-processing, in-processing, and post-processing for the DNN models to achieve a full coverage of the adversarial defenses. Based on the above survey, we finally discuss the challenges of this research field and further outlook the future direction.