 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Construction of a Cantonese Emotion Lexicon
Oct 15, 2024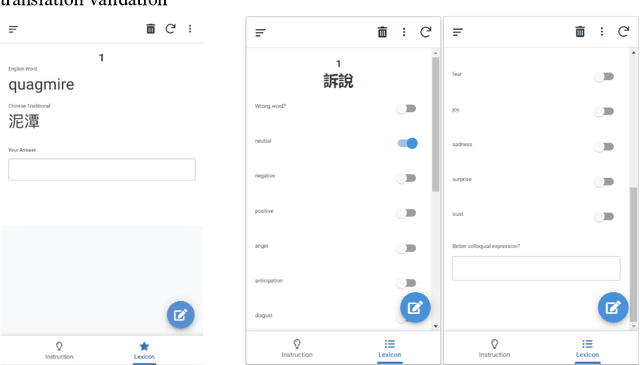
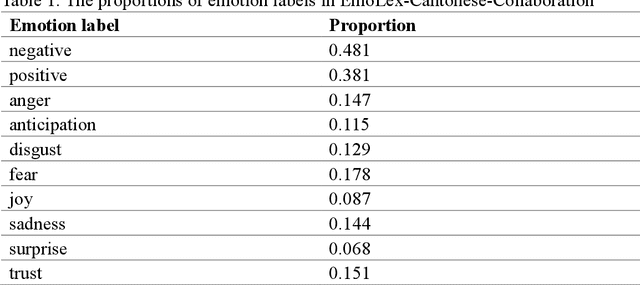
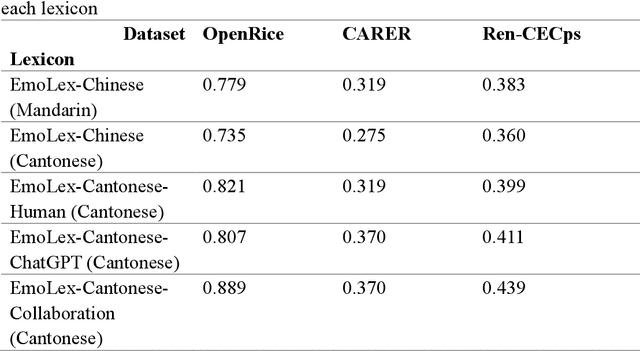
Large Language Models (LLMs) have demonstrated remarkable capabilities in language understanding and generation. Advanced utilization of the knowledge embedded in LLMs for automated annotation has consistently been explored. This study proposed to develop an emotion lexicon for Cantonese, a low-resource language, through collaborative efforts between LLM and human annotators. By integrating emotion labels provided by LLM and human annotators, the study leveraged existing linguistic resources including lexicons in other languages and local forums to construct a Cantonese emotion lexicon enriched with colloquial expressions. The consistency of the proposed emotion lexicon in emotion extraction was assessed through modification and utilization of three distinct emotion text datasets. This study not only validates the efficacy of the constructed lexicon but also emphasizes that collaborative annotation between human and artificial intelligence can significantly enhance the quality of emotion labels, highlighting the potential of such partnerships in facilitating natural language processing tasks for low-resource languages.
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 18, 2024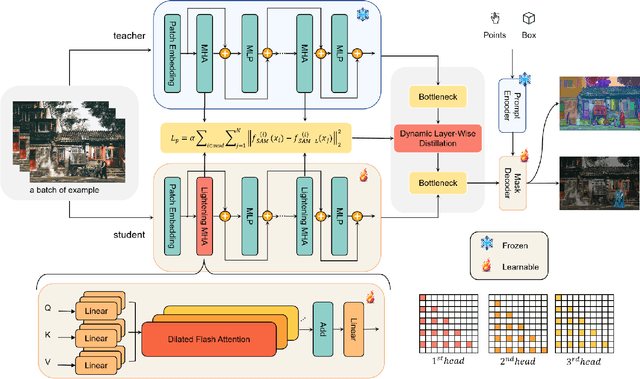
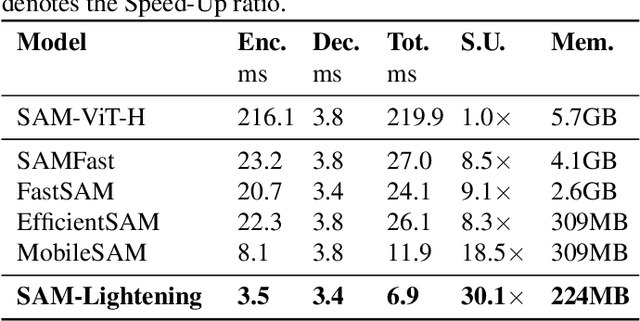

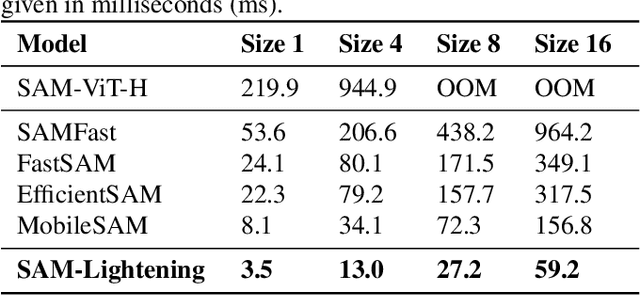
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
Transport Model for Feature Extraction
Oct 31, 2019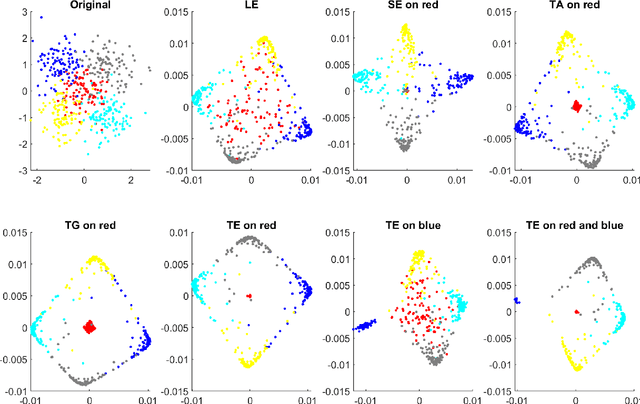

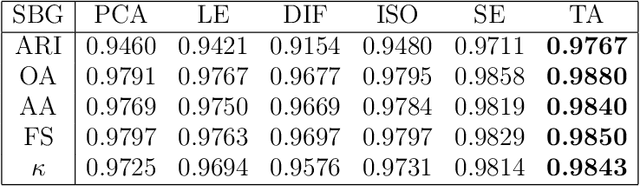
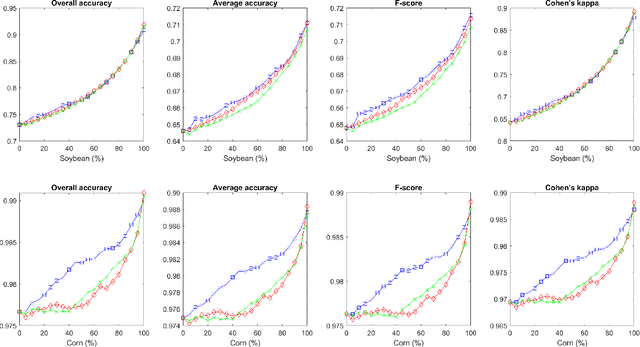
We present a new feature extraction method for complex and large datasets, based on the concept of transport operators on graphs. The proposed approach generalizes and extends the many existing data representation methodologies built upon diffusion processes, to a new domain where dynamical systems play a key role. The main advantage of this approach comes from the ability to exploit different relationships than those arising in the context of e.g., Graph Laplacians. Fundamental properties of the transport operators are proved. We demonstrate the flexibility of the method by introducing several diverse examples of transformations. We close the paper with a series of computational experiments and applications to the problem of classification of hyperspectral satellite imagery, to illustrate the practical implications of our algorithm and its ability to quantify new aspects of relationships within complicated datasets.