 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Through Conditional Quantile Matching
Feb 02, 2026We introduce a transfer learning framework for regression that leverages heterogeneous source domains to improve predictive performance in a data-scarce target domain. Our approach learns a conditional generative model separately for each source domain and calibrates the generated responses to the target domain via conditional quantile matching. This distributional alignment step corrects general discrepancies between source and target domains without imposing restrictive assumptions such as covariate or label shift. The resulting framework provides a principled and flexible approach to high-quality data augmentation for downstream learning tasks in the target domain. From a theoretical perspective, we show that an empirical risk minimizer (ERM) trained on the augmented dataset achieves a tighter excess risk bound than the target-only ERM under mild conditions. In particular, we establish new convergence rates for the quantile matching estimator that governs the transfer bias-variance tradeoff. From a practical perspective, extensive simulations and real data applications demonstrate that the proposed method consistently improves prediction accuracy over target-only learning and competing transfer learning methods.
Multiply Robust Estimation for Local Distribution Shifts with Multiple Domains
Feb 21, 2024Distribution shifts are ubiquitous in real-world machine learning applications, posing a challenge to the generalization of models trained on one data distribution to another. We focus on scenarios where data distributions vary across multiple segments of the entire population and only make local assumptions about the differences between training and test (deployment) distributions within each segment. We propose a two-stage multiply robust estimation method to improve model performance on each individual segment for tabular data analysis. The method involves fitting a linear combination of the based models, learned using clusters of training data from multiple segments, followed by a refinement step for each segment. Our method is designed to be implemented with commonly used off-the-shelf machine learning models. We establish theoretical guarantees on the generalization bound of the method on the test risk. With extensive experiments on synthetic and real datasets, we demonstrate that the proposed method substantially improves over existing alternatives in prediction accuracy and robustness on both regression and classification tasks. We also assess its effectiveness on a user city prediction dataset from a large technology company.
TIES: Temporal Interaction Embeddings For Enhancing Social Media Integrity At Facebook
Feb 18, 2020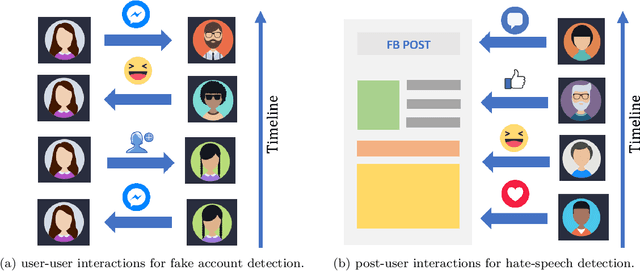
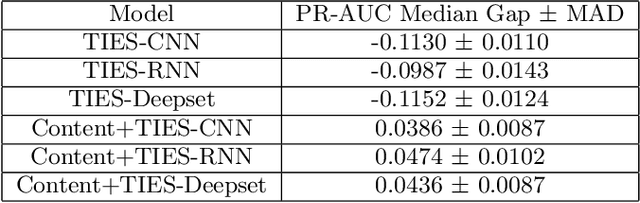

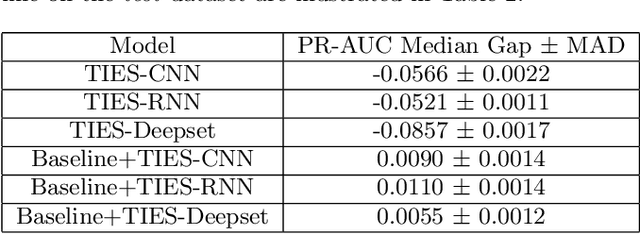
Since its inception, Facebook has become an integral part of the online social community. People rely on Facebook to make connections with others and build communities. As a result, it is paramount to protect the integrity of such a rapidly growing network in a fast and scalable manner. In this paper, we present our efforts to protect various social media entities at Facebook from people who try to abuse our platform. We present a novel Temporal Interaction EmbeddingS (TIES) model that is designed to capture rogue social interactions and flag them for further suitable actions. TIES is a supervised, deep learning, production ready model at Facebook-scale networks. Prior works on integrity problems are mostly focused on capturing either only static or certain dynamic features of social entities. In contrast, TIES can capture both these variant behaviors in a unified model owing to the recent strides made in the domains of graph embedding and deep sequential pattern learning. To show the real-world impact of TIES, we present a few applications especially for preventing spread of misinformation, fake account detection, and reducing ads payment risks in order to enhance the platform's integrity.
Arriving on time: estimating travel time distributions on large-scale road networks
Feb 26, 2013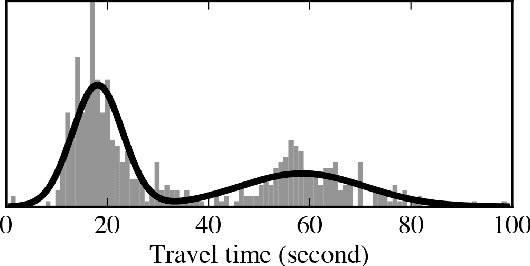
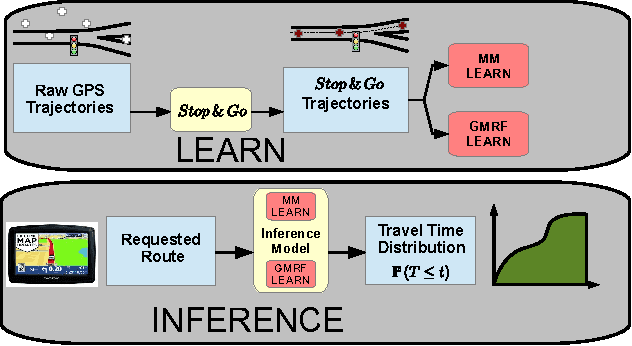
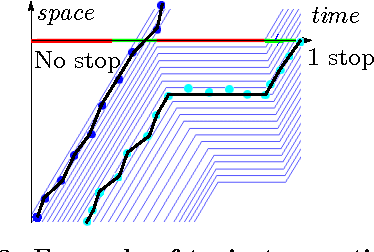
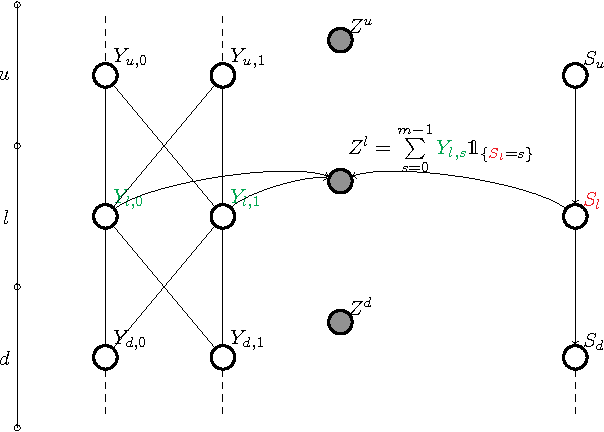
Most optimal routing problems focus on minimizing travel time or distance traveled. Oftentimes, a more useful objective is to maximize the probability of on-time arrival, which requires statistical distributions of travel times, rather than just mean values. We propose a method to estimate travel time distributions on large-scale road networks, using probe vehicle data collected from GPS. We present a framework that works with large input of data, and scales linearly with the size of the network. Leveraging the planar topology of the graph, the method computes efficiently the time correlations between neighboring streets. First, raw probe vehicle traces are compressed into pairs of travel times and number of stops for each traversed road segment using a `stop-and-go' algorithm developed for this work. The compressed data is then used as input for training a path travel time model, which couples a Markov model along with a Gaussian Markov random field. Finally, scalable inference algorithms are developed for obtaining path travel time distributions from the composite MM-GMRF model. We illustrate the accuracy and scalability of our model on a 505,000 road link network spanning the San Francisco Bay Area.