 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Text Corpora Predict Openness, Interests, Knowledge and Level of Education
Mar 29, 2024
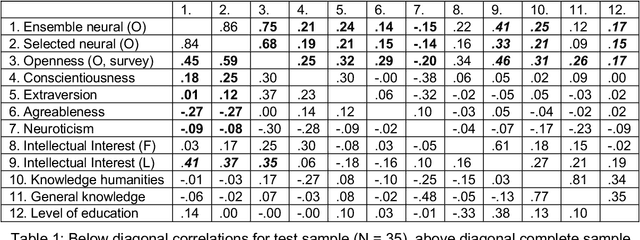


Here we examine whether the personality dimension of openness to experience can be predicted from the individual google search history. By web scraping, individual text corpora (ICs) were generated from 214 participants with a mean number of 5 million word tokens. We trained word2vec models and used the similarities of each IC to label words, which were derived from a lexical approach of personality. These IC-label-word similarities were utilized as predictive features in neural models. For training and validation, we relied on 179 participants and held out a test sample of 35 participants. A grid search with varying number of predictive features, hidden units and boost factor was performed. As model selection criterion, we used R2 in the validation samples penalized by the absolute R2 difference between training and validation. The selected neural model explained 35% of the openness variance in the test sample, while an ensemble model with the same architecture often provided slightly more stable predictions for intellectual interests, knowledge in humanities and level of education. Finally, a learning curve analysis suggested that around 500 training participants are required for generalizable predictions. We discuss ICs as a complement or replacement of survey-based psychodiagnostics.
Computational analyses of the topics, sentiments, literariness, creativity and beauty of texts in a large Corpus of English Literature
Jan 12, 2022
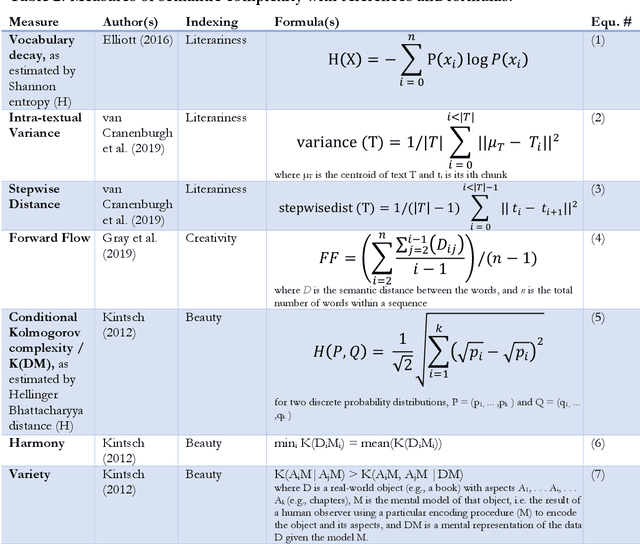
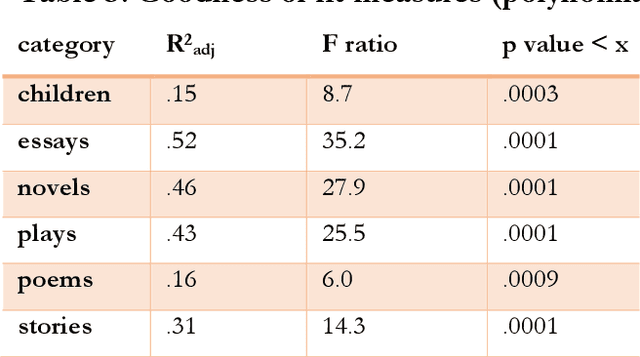
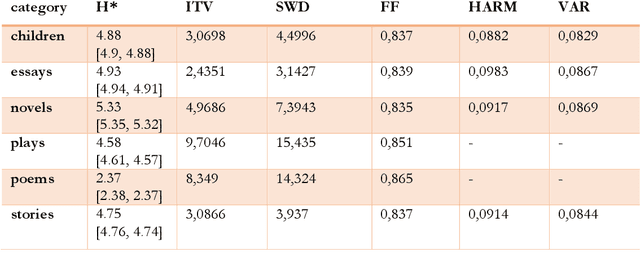
The Gutenberg Literary English Corpus (GLEC, Jacobs, 2018a) provides a rich source of textual data for research in digital humanities, computational linguistics or neurocognitive poetics. In this study we address differences among the different literature categories in GLEC, as well as differences between authors. We report the results of three studies providing i) topic and sentiment analyses for six text categories of GLEC (i.e., children and youth, essays, novels, plays, poems, stories) and its >100 authors, ii) novel measures of semantic complexity as indices of the literariness, creativity and book beauty of the works in GLEC (e.g., Jane Austen's six novels), and iii) two experiments on text classification and authorship recognition using novel features of semantic complexity. The data on two novel measures estimating a text's literariness, intratextual variance and stepwise distance (van Cranenburgh et al., 2019) revealed that plays are the most literary texts in GLEC, followed by poems and novels. Computation of a novel index of text creativity (Gray et al., 2016) revealed poems and plays as the most creative categories with the most creative authors all being poets (Milton, Pope, Keats, Byron, or Wordsworth). We also computed a novel index of perceived beauty of verbal art (Kintsch, 2012) for the works in GLEC and predict that Emma is the theoretically most beautiful of Austen's novels. Finally, we demonstrate that these novel measures of semantic complexity are important features for text classification and authorship recognition with overall predictive accuracies in the range of .75 to .97. Our data pave the way for future computational and empirical studies of literature or experiments in reading psychology and offer multiple baselines and benchmarks for analysing and validating other book corpora.
Electoral Programs of German Parties 2021: A Computational Analysis Of Their Comprehensibility and Likeability Based On SentiArt
Sep 26, 2021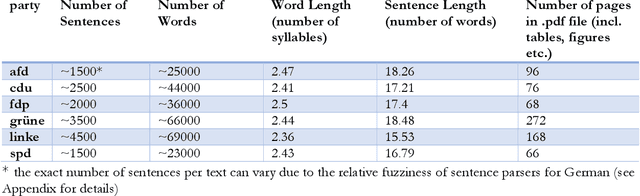
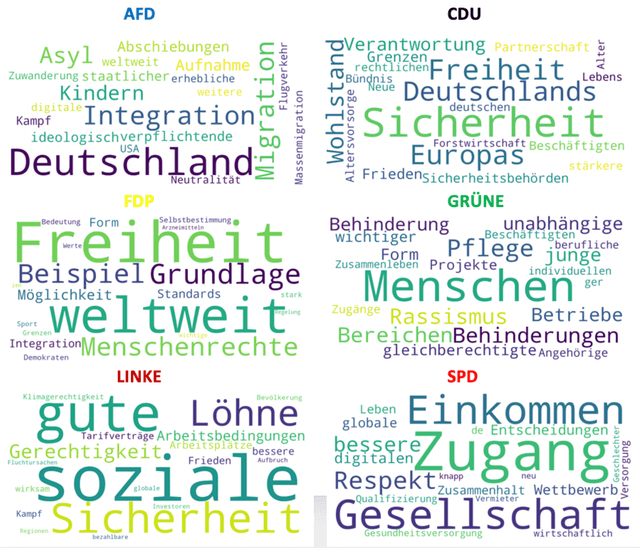
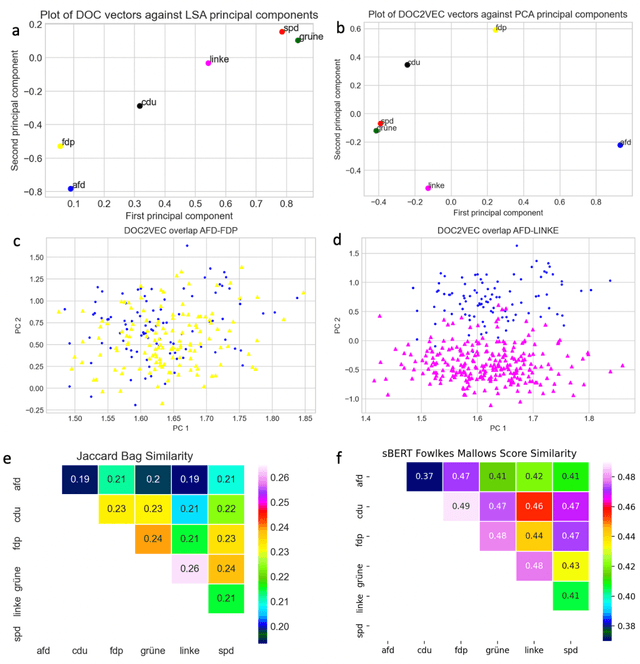
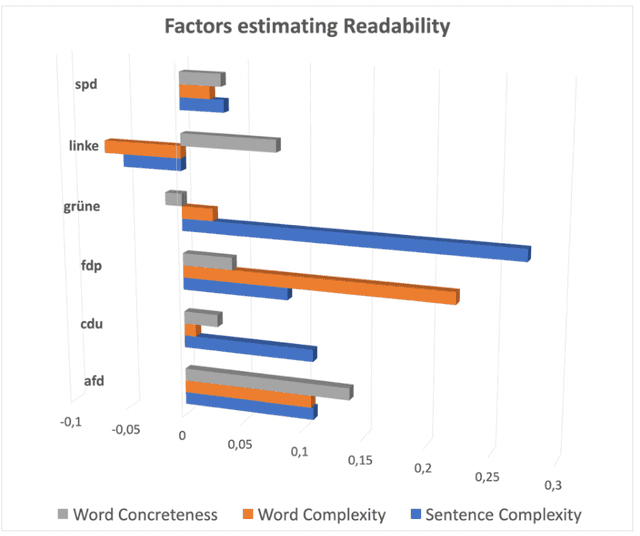
The electoral programs of six German parties issued before the parliamentary elections of 2021 are analyzed using state-of-the-art computational tools for quantitative narrative, topic and sentiment analysis. We compare different methods for computing the textual similarity of the programs, Jaccard Bag similarity, Latent Semantic Analysis, doc2vec, and sBERT, the representational and computational complexity increasing from the 1st to the 4th method. A new similarity measure for entire documents derived from the Fowlkes Mallows Score is applied to kmeans clustering of sBERT transformed sentences. Using novel indices of the readability and emotion potential of texts computed via SentiArt (Jacobs, 2019), our data shed light on the similarities and differences of the programs regarding their length, main ideas, comprehensibility, likeability, and semantic complexity. Among others, they reveal that the programs of the SPD and CDU have the best chances to be comprehensible and likeable -all other things being equal-, and they raise the important issue of which similarity measure is optimal for comparing texts such as electoral programs which necessarily share a lot of words. While such analyses can not replace qualitative analyses or a deep reading of the texts, they offer predictions that can be verified in empirical studies and may serve as a motivation for changing aspects of future electoral programs potentially making them more comprehensible and/or likeable.
Is Einstein more agreeable and less neurotic than Hitler? A computational exploration of the emotional and personality profiles of historical persons
Jun 14, 2021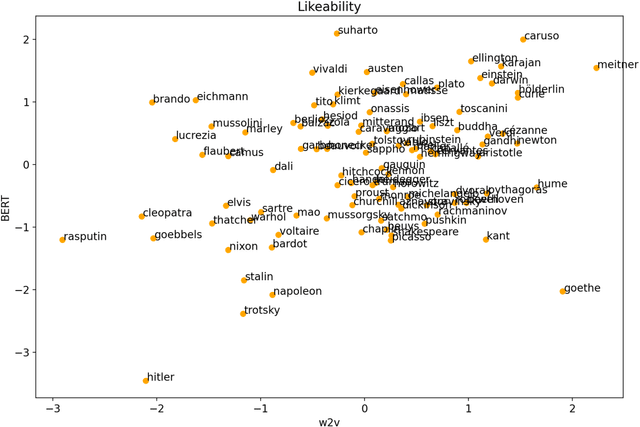
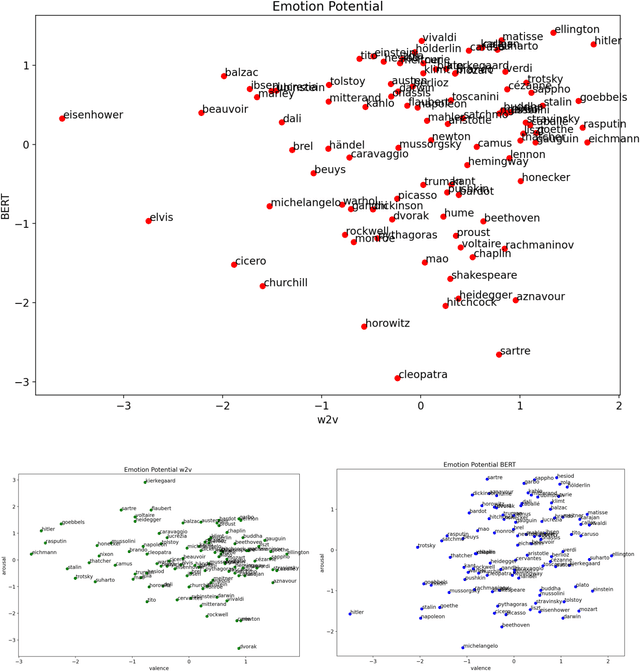
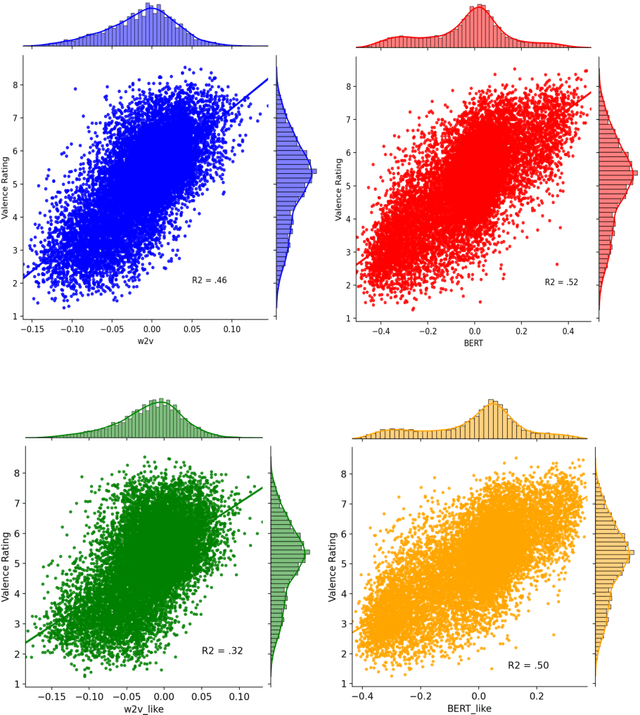
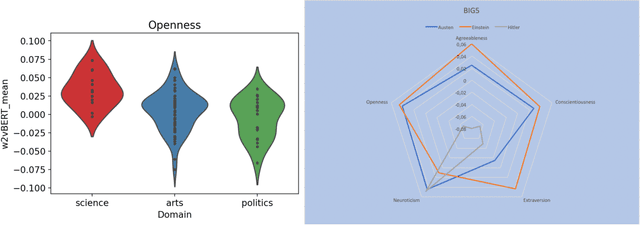
Recent progress in distributed semantic models (DSM) offers new ways to estimate personality traits of both fictive and real people. In this exploratory study we applied an extended version of the algorithm developed in Jacobs (2019) to compute the likeability scores, emotional figure profiles and BIG5 personality traits for 100 historical persons from the arts, politics or science domains whose names are rather unique (e.g., Einstein, Kahlo, Picasso). We compared the results produced by static (word2vec) and dynamic (BERT) language model representations in four studies. The results show both the potential and limitations of such DSM-based computations of personality profiles and point ways to further develop this approach to become a useful tool in data science, psychology or computational and neurocognitive poetics (Jacobs, 2015).
Quasi Error-free Text Classification and Authorship Recognition in a large Corpus of English Literature based on a Novel Feature Set
Oct 21, 2020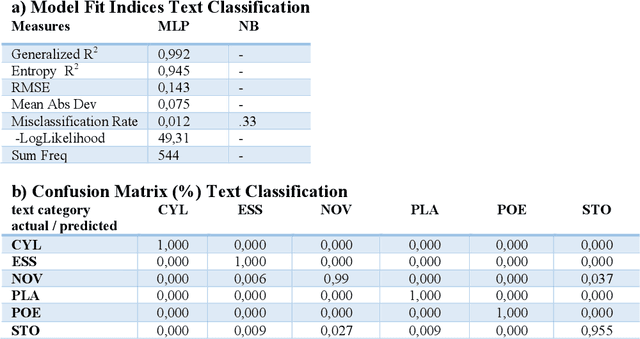
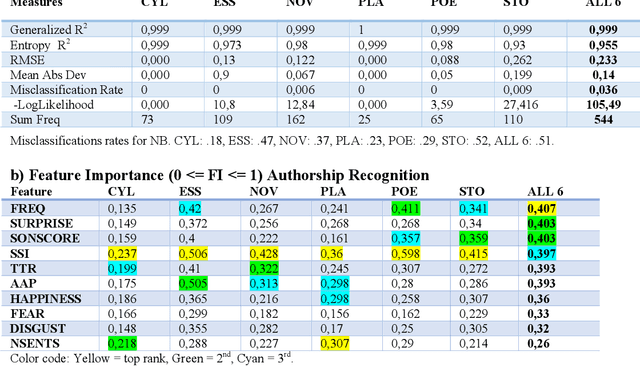
The Gutenberg Literary English Corpus (GLEC) provides a rich source of textual data for research in digital humanities, computational linguistics or neurocognitive poetics. However, so far only a small subcorpus, the Gutenberg English Poetry Corpus, has been submitted to quantitative text analyses providing predictions for scientific studies of literature. Here we show that in the entire GLEC quasi error-free text classification and authorship recognition is possible with a method using the same set of five style and five content features, computed via style and sentiment analysis, in both tasks. Our results identify two standard and two novel features (i.e., type-token ratio, frequency, sonority score, surprise) as most diagnostic in these tasks. By providing a simple tool applicable to both short poems and long novels generating quantitative predictions about features that co-determe the cognitive and affective processing of specific text categories or authors, our data pave the way for many future computational and empirical studies of literature or experiments in reading psychology.
Features of word similarity
Aug 24, 2018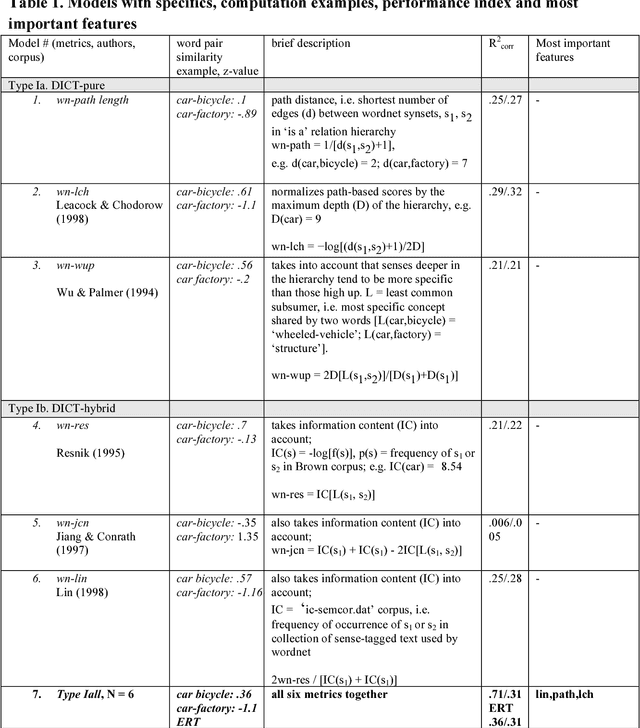
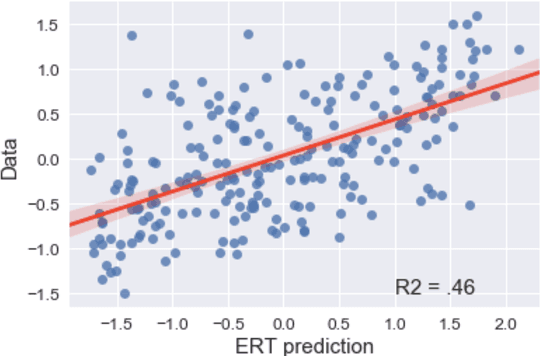
In this theoretical note we compare different types of computational models of word similarity and association in their ability to predict a set of about 900 rating data. Using regression and predictive modeling tools (neural net, decision tree) the performance of a total of 28 models using different combinations of both surface and semantic word features is evaluated. The results present evidence for the hypothesis that word similarity ratings are based on more than only semantic relatedness. The limited cross-validated performance of the models asks for the development of psychological process models of the word similarity rating task.
Explorations in an English Poetry Corpus: A Neurocognitive Poetics Perspective
Jan 06, 2018

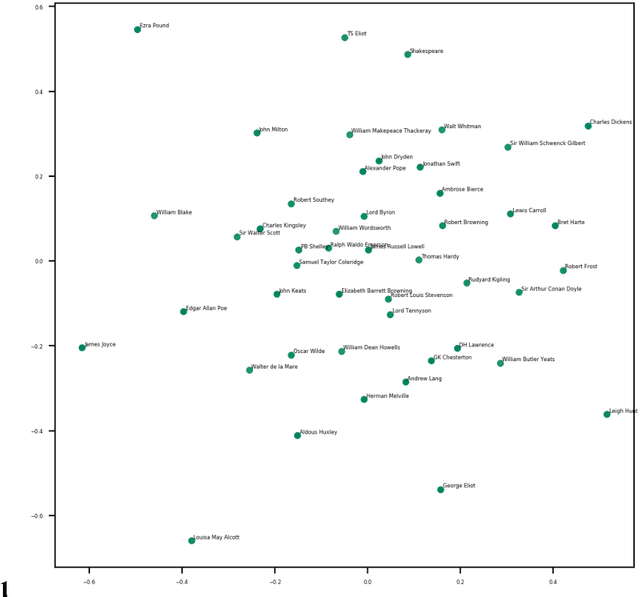
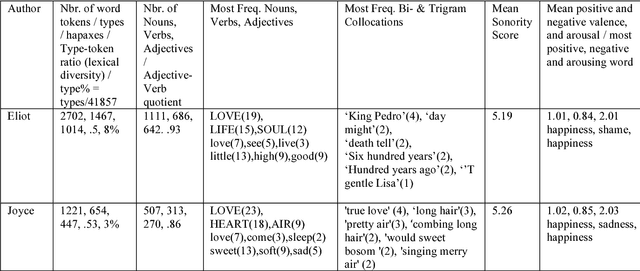
This paper describes a corpus of about 3000 English literary texts with about 250 million words extracted from the Gutenberg project that span a range of genres from both fiction and non-fiction written by more than 130 authors (e.g., Darwin, Dickens, Shakespeare). Quantitative Narrative Analysis (QNA) is used to explore a cleaned subcorpus, the Gutenberg English Poetry Corpus (GEPC) which comprises over 100 poetic texts with around 2 million words from about 50 authors (e.g., Keats, Joyce, Wordsworth). Some exemplary QNA studies show author similarities based on latent semantic analysis, significant topics for each author or various text-analytic metrics for George Eliot's poem 'How Lisa Loved the King' and James Joyce's 'Chamber Music', concerning e.g. lexical diversity or sentiment analysis. The GEPC is particularly suited for research in Digital Humanities, Natural Language Processing or Neurocognitive Poetics, e.g. as training and test corpus, or for stimulus development and control.