 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectoral Programs of German Parties 2021: A Computational Analysis Of Their Comprehensibility and Likeability Based On SentiArt
Paper and Code
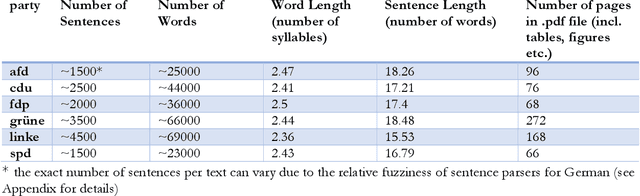
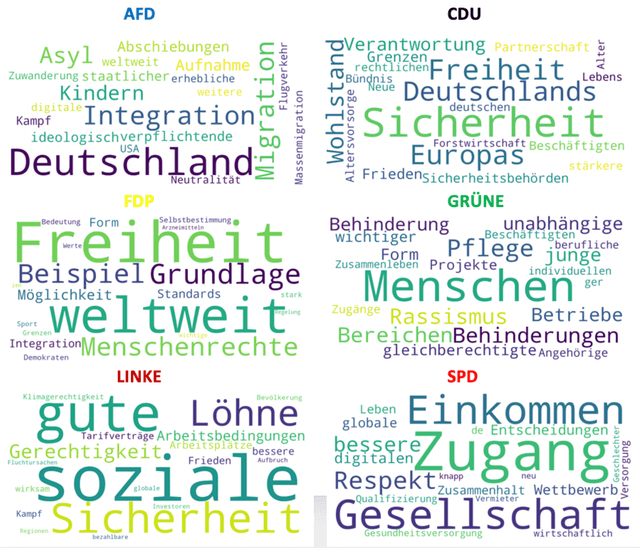
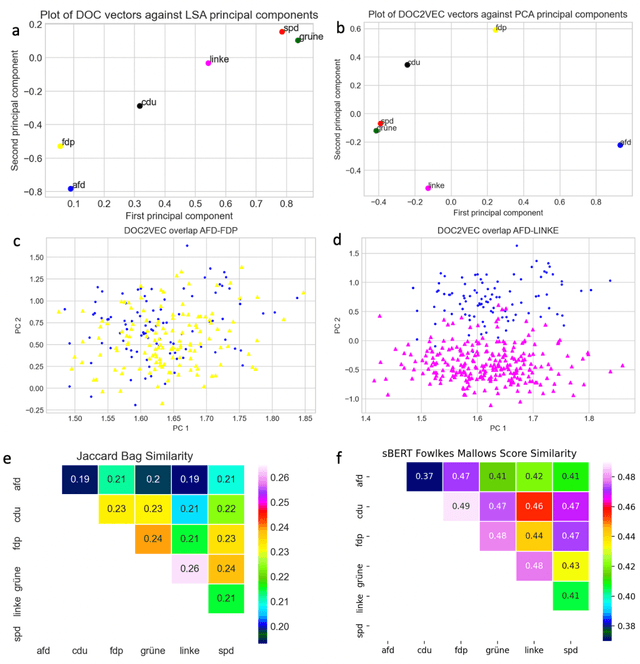
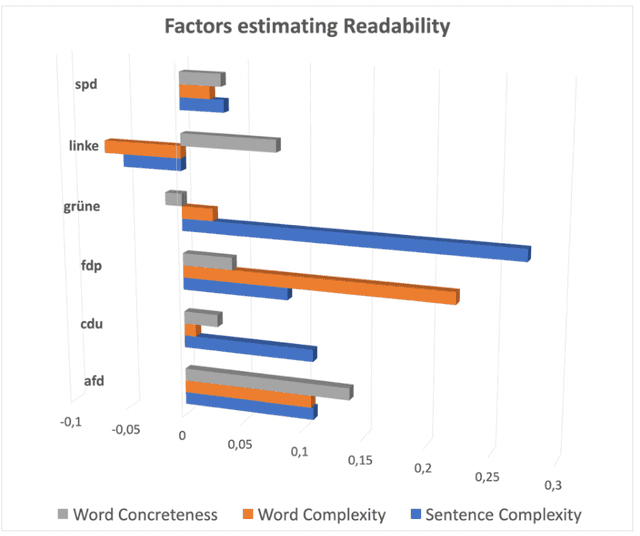
The electoral programs of six German parties issued before the parliamentary elections of 2021 are analyzed using state-of-the-art computational tools for quantitative narrative, topic and sentiment analysis. We compare different methods for computing the textual similarity of the programs, Jaccard Bag similarity, Latent Semantic Analysis, doc2vec, and sBERT, the representational and computational complexity increasing from the 1st to the 4th method. A new similarity measure for entire documents derived from the Fowlkes Mallows Score is applied to kmeans clustering of sBERT transformed sentences. Using novel indices of the readability and emotion potential of texts computed via SentiArt (Jacobs, 2019), our data shed light on the similarities and differences of the programs regarding their length, main ideas, comprehensibility, likeability, and semantic complexity. Among others, they reveal that the programs of the SPD and CDU have the best chances to be comprehensible and likeable -all other things being equal-, and they raise the important issue of which similarity measure is optimal for comparing texts such as electoral programs which necessarily share a lot of words. While such analyses can not replace qualitative analyses or a deep reading of the texts, they offer predictions that can be verified in empirical studies and may serve as a motivation for changing aspects of future electoral programs potentially making them more comprehensible and/or likeable.