 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Text Corpora Predict Openness, Interests, Knowledge and Level of Education
Mar 29, 2024
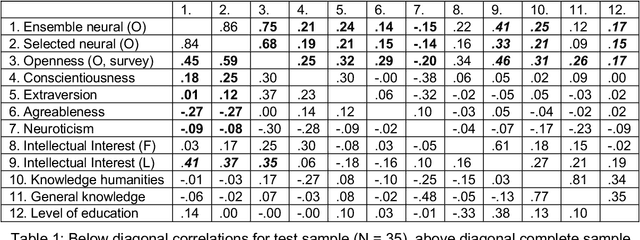


Here we examine whether the personality dimension of openness to experience can be predicted from the individual google search history. By web scraping, individual text corpora (ICs) were generated from 214 participants with a mean number of 5 million word tokens. We trained word2vec models and used the similarities of each IC to label words, which were derived from a lexical approach of personality. These IC-label-word similarities were utilized as predictive features in neural models. For training and validation, we relied on 179 participants and held out a test sample of 35 participants. A grid search with varying number of predictive features, hidden units and boost factor was performed. As model selection criterion, we used R2 in the validation samples penalized by the absolute R2 difference between training and validation. The selected neural model explained 35% of the openness variance in the test sample, while an ensemble model with the same architecture often provided slightly more stable predictions for intellectual interests, knowledge in humanities and level of education. Finally, a learning curve analysis suggested that around 500 training participants are required for generalizable predictions. We discuss ICs as a complement or replacement of survey-based psychodiagnostics.
Language Models Explain Word Reading Times Better Than Empirical Predictability
Feb 02, 2022
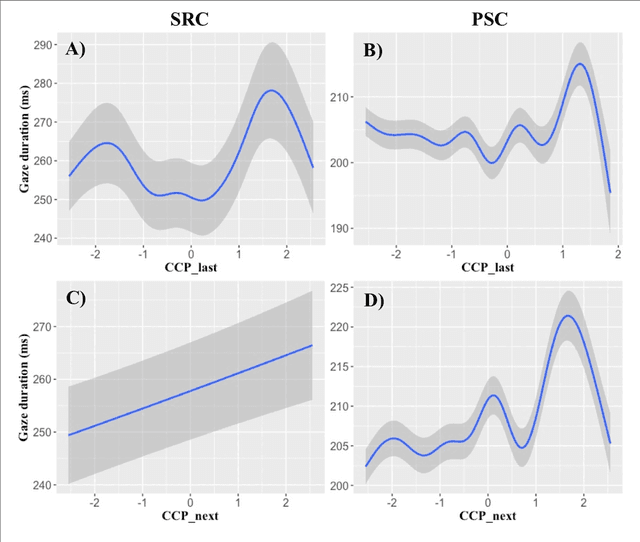
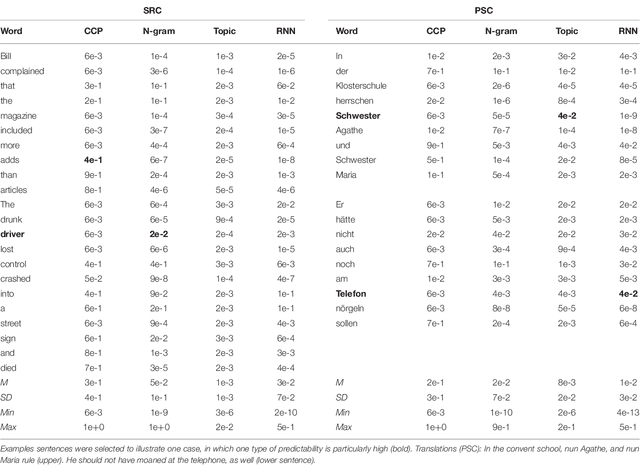
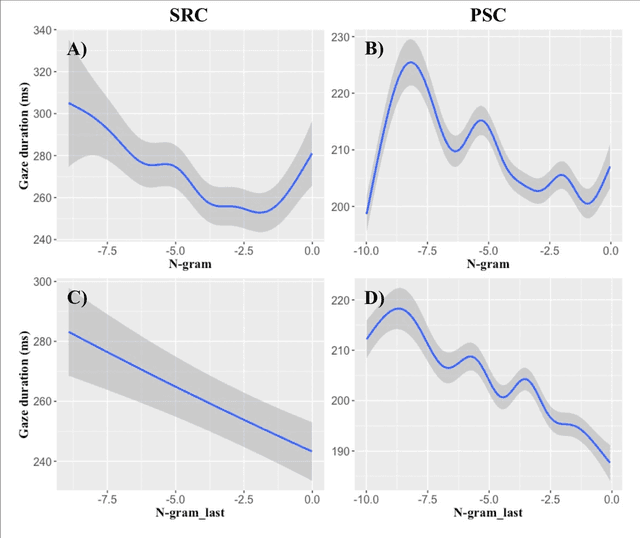
Though there is a strong consensus that word length and frequency are the most important single-word features determining visual-orthographic access to the mental lexicon, there is less agreement as how to best capture syntactic and semantic factors. The traditional approach in cognitive reading research assumes that word predictability from sentence context is best captured by cloze completion probability (CCP) derived from human performance data. We review recent research suggesting that probabilistic language models provide deeper explanations for syntactic and semantic effects than CCP. Then we compare CCP with (1) Symbolic n-gram models consolidate syntactic and semantic short-range relations by computing the probability of a word to occur, given two preceding words. (2) Topic models rely on subsymbolic representations to capture long-range semantic similarity by word co-occurrence counts in documents. (3) In recurrent neural networks (RNNs), the subsymbolic units are trained to predict the next word, given all preceding words in the sentences. To examine lexical retrieval, these models were used to predict single fixation durations and gaze durations to capture rapidly successful and standard lexical access, and total viewing time to capture late semantic integration. The linear item-level analyses showed greater correlations of all language models with all eye-movement measures than CCP. Then we examined non-linear relations between the different types of predictability and the reading times using generalized additive models. N-gram and RNN probabilities of the present word more consistently predicted reading performance compared with topic models or CCP.
Individual corpora predict fast memory retrieval during reading
Oct 20, 2020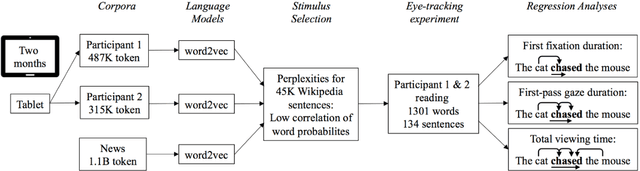
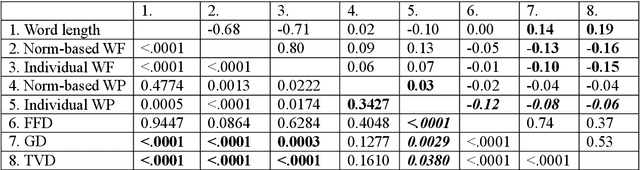

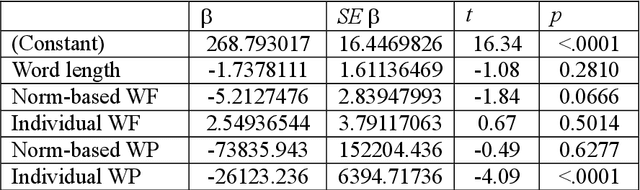
The corpus, from which a predictive language model is trained, can be considered the experience of a semantic system. We recorded everyday reading of two participants for two months on a tablet, generating individual corpus samples of 300/500K tokens. Then we trained word2vec models from individual corpora and a 70 million-sentence newspaper corpus to obtain individual and norm-based long-term memory structure. To test whether individual corpora can make better predictions for a cognitive task of long-term memory retrieval, we generated stimulus materials consisting of 134 sentences with uncorrelated individual and norm-based word probabilities. For the subsequent eye tracking study 1-2 months later, our regression analyses revealed that individual, but not norm-corpus-based word probabilities can account for first-fixation duration and first-pass gaze duration. Word length additionally affected gaze duration and total viewing duration. The results suggest that corpora representative for an individual's longterm memory structure can better explain reading performance than a norm corpus, and that recently acquired information is lexically accessed rapidly.
Decomposing predictability: Semantic feature overlap between words and the dynamics of reading for meaning
Dec 06, 2019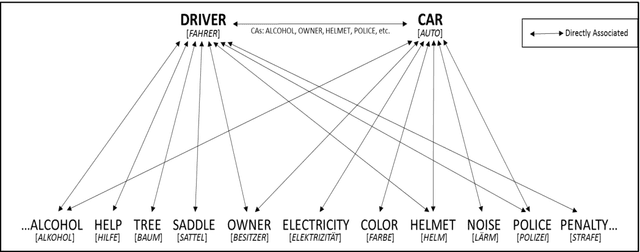
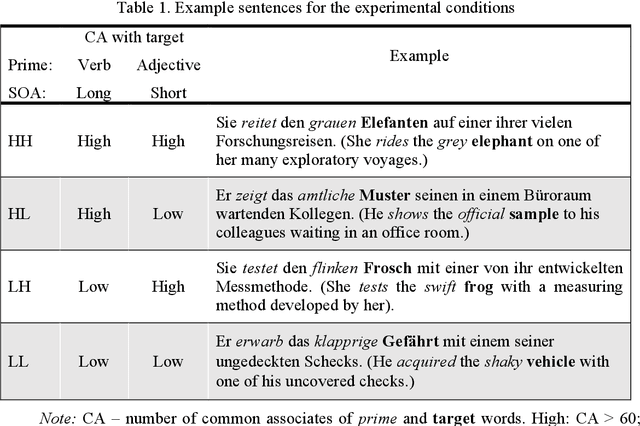
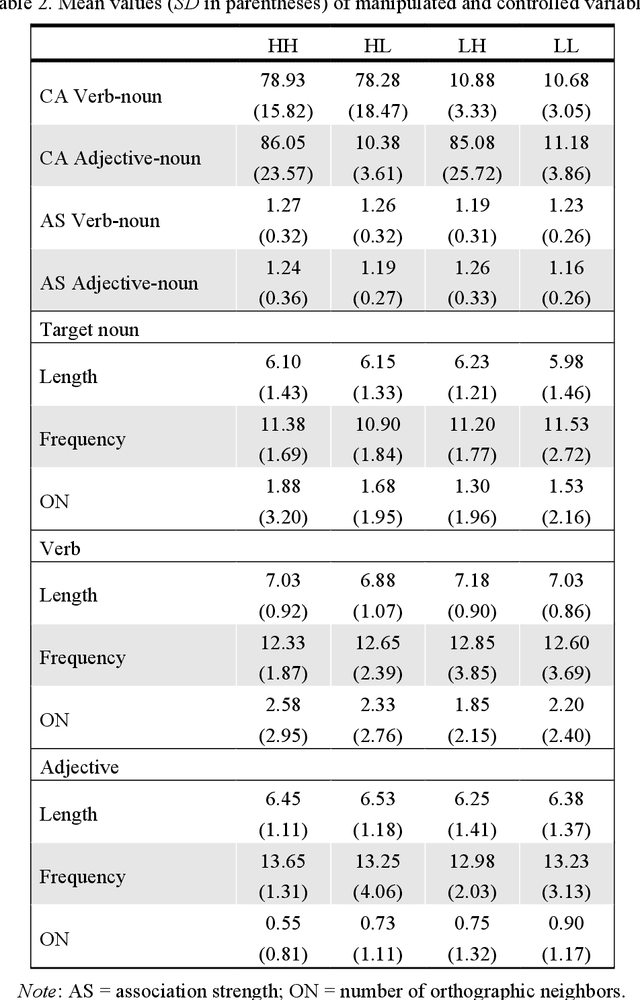

The present study uses a computational approach to examine the role of semantic constraints in normal reading. This methodology avoids confounds inherent in conventional measures of predictability, allowing for theoretically deeper accounts of semantic processing. We start from a definition of associations between words based on the significant log likelihood that two words co-occur frequently together in the sentences of a large text corpus. Direct associations between stimulus words were controlled, and semantic feature overlap between prime and target words was manipulated by their common associates. The stimuli consisted of sentences of the form pronoun, verb, article, adjective and noun, followed by a series of closed class words, e. g. "She rides the grey elephant on one of her many exploratory voyages". The results showed that verb-noun overlap reduces single and first fixation durations of the target noun and adjective-noun overlap reduces go-past durations. A dynamic spreading of activation account suggests that associates of the prime words take some time to become activated: The verb can act on the target noun's early eye-movement measures presented three words later, while the adjective is presented immediately prior to the target, which induces sentence re-examination after a difficult adjective-noun semantic integration.