 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual Text Corpora Predict Openness, Interests, Knowledge and Level of Education
Paper and Code
Mar 29, 2024
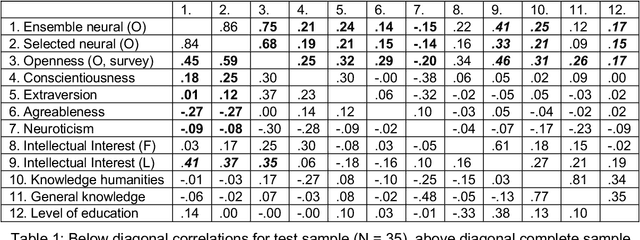


Here we examine whether the personality dimension of openness to experience can be predicted from the individual google search history. By web scraping, individual text corpora (ICs) were generated from 214 participants with a mean number of 5 million word tokens. We trained word2vec models and used the similarities of each IC to label words, which were derived from a lexical approach of personality. These IC-label-word similarities were utilized as predictive features in neural models. For training and validation, we relied on 179 participants and held out a test sample of 35 participants. A grid search with varying number of predictive features, hidden units and boost factor was performed. As model selection criterion, we used R2 in the validation samples penalized by the absolute R2 difference between training and validation. The selected neural model explained 35% of the openness variance in the test sample, while an ensemble model with the same architecture often provided slightly more stable predictions for intellectual interests, knowledge in humanities and level of education. Finally, a learning curve analysis suggested that around 500 training participants are required for generalizable predictions. We discuss ICs as a complement or replacement of survey-based psychodiagnostics.