 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Explain Word Reading Times Better Than Empirical Predictability
Paper and Code

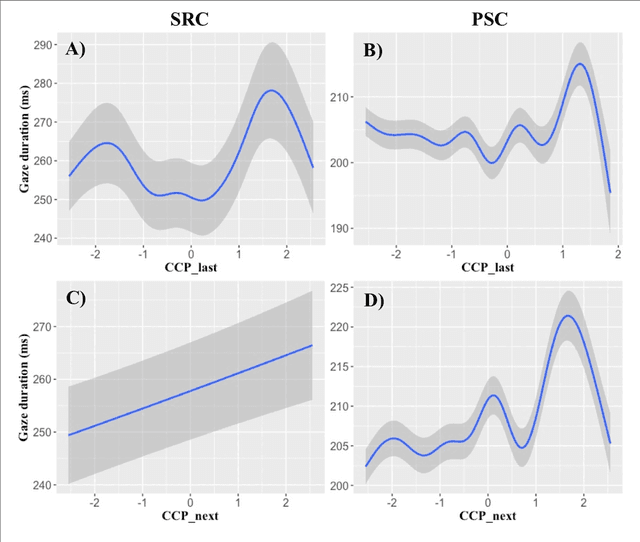
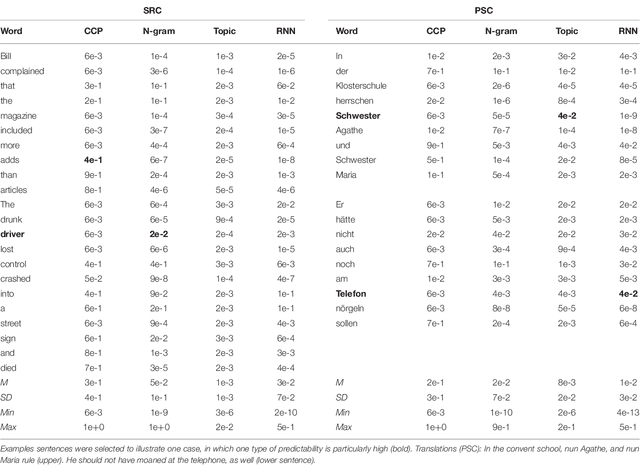
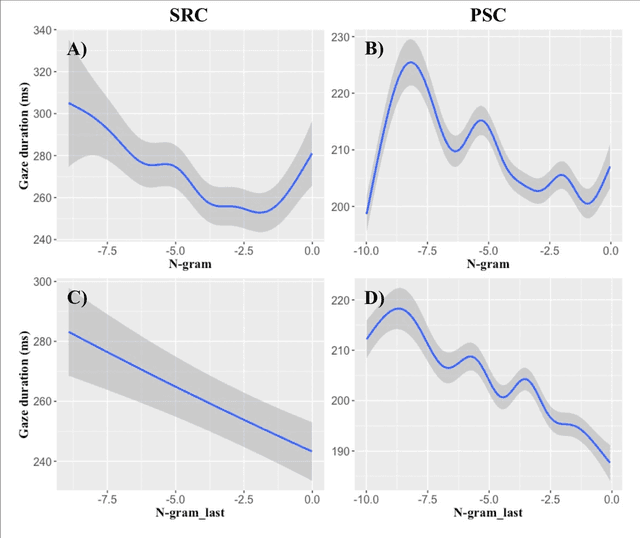
Though there is a strong consensus that word length and frequency are the most important single-word features determining visual-orthographic access to the mental lexicon, there is less agreement as how to best capture syntactic and semantic factors. The traditional approach in cognitive reading research assumes that word predictability from sentence context is best captured by cloze completion probability (CCP) derived from human performance data. We review recent research suggesting that probabilistic language models provide deeper explanations for syntactic and semantic effects than CCP. Then we compare CCP with (1) Symbolic n-gram models consolidate syntactic and semantic short-range relations by computing the probability of a word to occur, given two preceding words. (2) Topic models rely on subsymbolic representations to capture long-range semantic similarity by word co-occurrence counts in documents. (3) In recurrent neural networks (RNNs), the subsymbolic units are trained to predict the next word, given all preceding words in the sentences. To examine lexical retrieval, these models were used to predict single fixation durations and gaze durations to capture rapidly successful and standard lexical access, and total viewing time to capture late semantic integration. The linear item-level analyses showed greater correlations of all language models with all eye-movement measures than CCP. Then we examined non-linear relations between the different types of predictability and the reading times using generalized additive models. N-gram and RNN probabilities of the present word more consistently predicted reading performance compared with topic models or CCP.