 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplorations in an English Poetry Corpus: A Neurocognitive Poetics Perspective
Paper and Code
Jan 06, 2018

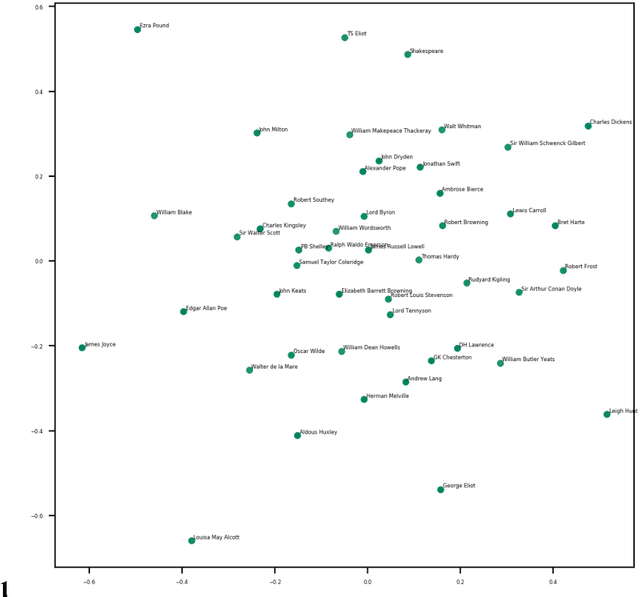
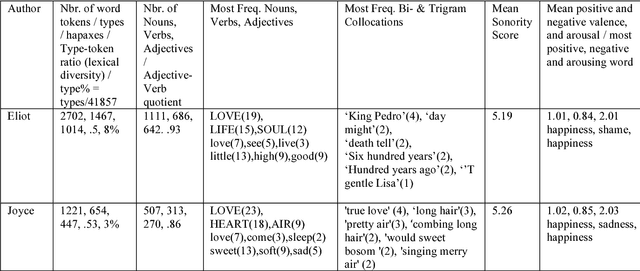
This paper describes a corpus of about 3000 English literary texts with about 250 million words extracted from the Gutenberg project that span a range of genres from both fiction and non-fiction written by more than 130 authors (e.g., Darwin, Dickens, Shakespeare). Quantitative Narrative Analysis (QNA) is used to explore a cleaned subcorpus, the Gutenberg English Poetry Corpus (GEPC) which comprises over 100 poetic texts with around 2 million words from about 50 authors (e.g., Keats, Joyce, Wordsworth). Some exemplary QNA studies show author similarities based on latent semantic analysis, significant topics for each author or various text-analytic metrics for George Eliot's poem 'How Lisa Loved the King' and James Joyce's 'Chamber Music', concerning e.g. lexical diversity or sentiment analysis. The GEPC is particularly suited for research in Digital Humanities, Natural Language Processing or Neurocognitive Poetics, e.g. as training and test corpus, or for stimulus development and control.