 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational analyses of the topics, sentiments, literariness, creativity and beauty of texts in a large Corpus of English Literature
Paper and Code

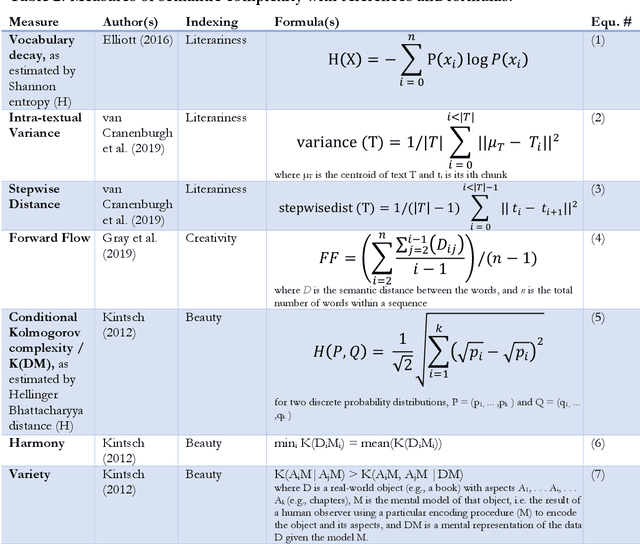
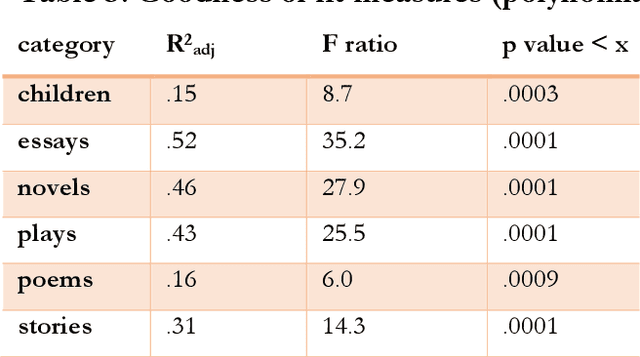
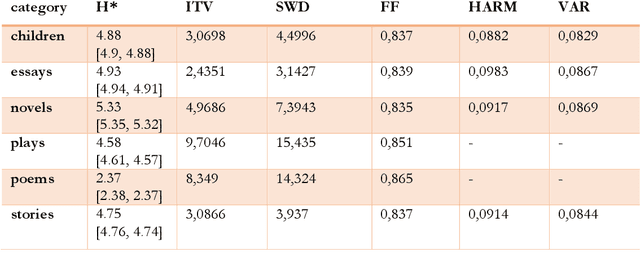
The Gutenberg Literary English Corpus (GLEC, Jacobs, 2018a) provides a rich source of textual data for research in digital humanities, computational linguistics or neurocognitive poetics. In this study we address differences among the different literature categories in GLEC, as well as differences between authors. We report the results of three studies providing i) topic and sentiment analyses for six text categories of GLEC (i.e., children and youth, essays, novels, plays, poems, stories) and its >100 authors, ii) novel measures of semantic complexity as indices of the literariness, creativity and book beauty of the works in GLEC (e.g., Jane Austen's six novels), and iii) two experiments on text classification and authorship recognition using novel features of semantic complexity. The data on two novel measures estimating a text's literariness, intratextual variance and stepwise distance (van Cranenburgh et al., 2019) revealed that plays are the most literary texts in GLEC, followed by poems and novels. Computation of a novel index of text creativity (Gray et al., 2016) revealed poems and plays as the most creative categories with the most creative authors all being poets (Milton, Pope, Keats, Byron, or Wordsworth). We also computed a novel index of perceived beauty of verbal art (Kintsch, 2012) for the works in GLEC and predict that Emma is the theoretically most beautiful of Austen's novels. Finally, we demonstrate that these novel measures of semantic complexity are important features for text classification and authorship recognition with overall predictive accuracies in the range of .75 to .97. Our data pave the way for future computational and empirical studies of literature or experiments in reading psychology and offer multiple baselines and benchmarks for analysing and validating other book corpora.