Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatures of word similarity
Paper and Code
Aug 24, 2018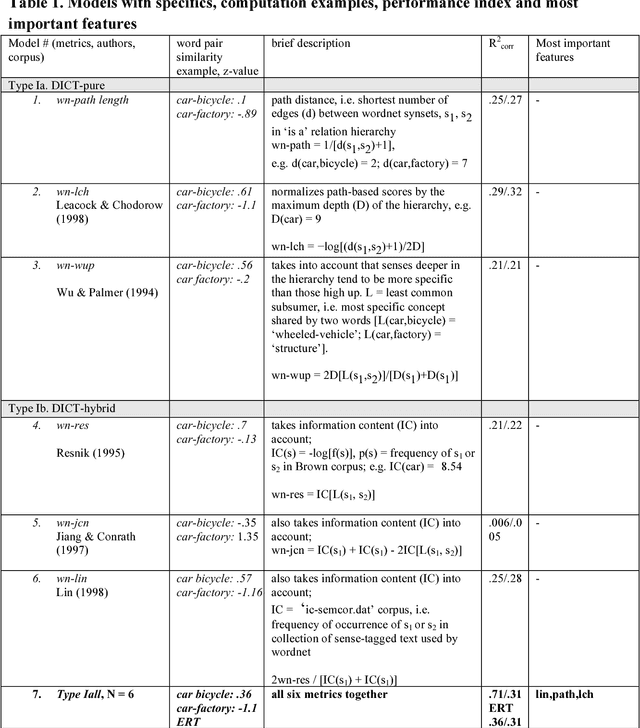
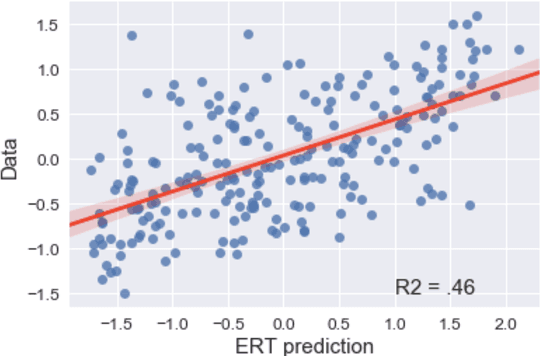
In this theoretical note we compare different types of computational models of word similarity and association in their ability to predict a set of about 900 rating data. Using regression and predictive modeling tools (neural net, decision tree) the performance of a total of 28 models using different combinations of both surface and semantic word features is evaluated. The results present evidence for the hypothesis that word similarity ratings are based on more than only semantic relatedness. The limited cross-validated performance of the models asks for the development of psychological process models of the word similarity rating task.
* 20 pages, 1 Figure
View paper on