 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI Systems Applied to tasks in Financial Services: Modeling and model risk management crews
Feb 08, 2025The advent of large language models has ushered in a new era of agentic systems, where artificial intelligence programs exhibit remarkable autonomous decision-making capabilities across diverse domains. This paper explores agentic system workflows in the financial services industry. In particular, we build agentic crews that can effectively collaborate to perform complex modeling and model risk management (MRM) tasks. The modeling crew consists of a manager and multiple agents who perform specific tasks such as exploratory data analysis, feature engineering, model selection, hyperparameter tuning, model training, model evaluation, and writing documentation. The MRM crew consists of a manager along with specialized agents who perform tasks such as checking compliance of modeling documentation, model replication, conceptual soundness, analysis of outcomes, and writing documentation. We demonstrate the effectiveness and robustness of modeling and MRM crews by presenting a series of numerical examples applied to credit card fraud detection, credit card approval, and portfolio credit risk modeling datasets.
MBExplainer: Multilevel bandit-based explanations for downstream models with augmented graph embeddings
Nov 01, 2024In many industrial applications, it is common that the graph embeddings generated from training GNNs are used in an ensemble model where the embeddings are combined with other tabular features (e.g., original node or edge features) in a downstream ML task. The tabular features may even arise naturally if, e.g., one tries to build a graph such that some of the node or edge features are stored in a tabular format. Here we address the problem of explaining the output of such ensemble models for which the input features consist of learned neural graph embeddings combined with additional tabular features. We propose MBExplainer, a model-agnostic explanation approach for downstream models with augmented graph embeddings. MBExplainer returns a human-legible triple as an explanation for an instance prediction of the whole pipeline consisting of three components: a subgraph with the highest importance, the topmost important nodal features, and the topmost important augmented downstream features. A game-theoretic formulation is used to take the contributions of each component and their interactions into account by assigning three Shapley values corresponding to their own specific games. Finding the explanation requires an efficient search through the corresponding local search spaces corresponding to each component. MBExplainer applies a novel multilevel search algorithm that enables simultaneous pruning of local search spaces in a computationally tractable way. In particular, three interweaved Monte Carlo Tree Search are utilized to iteratively prune the local search spaces. MBExplainer also includes a global search algorithm that uses contextual bandits to efficiently allocate pruning budget among the local search spaces. We show the effectiveness of MBExplainer by presenting a set of comprehensive numerical examples on multiple public graph datasets for both node and graph classification tasks.
Mechanistic interpretability of large language models with applications to the financial services industry
Jul 15, 2024


Large Language Models such as GPTs (Generative Pre-trained Transformers) exhibit remarkable capabilities across a broad spectrum of applications. Nevertheless, due to their intrinsic complexity, these models present substantial challenges in interpreting their internal decision-making processes. This lack of transparency poses critical challenges when it comes to their adaptation by financial institutions, where concerns and accountability regarding bias, fairness, and reliability are of paramount importance. Mechanistic interpretability aims at reverse engineering complex AI models such as transformers. In this paper, we are pioneering the use of mechanistic interpretability to shed some light on the inner workings of large language models for use in financial services applications. We offer several examples of how algorithmic tasks can be designed for compliance monitoring purposes. In particular, we investigate GPT-2 Small's attention pattern when prompted to identify potential violation of Fair Lending laws. Using direct logit attribution, we study the contributions of each layer and its corresponding attention heads to the logit difference in the residual stream. Finally, we design clean and corrupted prompts and use activation patching as a causal intervention method to localize our task completion components further. We observe that the (positive) heads $10.2$ (head $2$, layer $10$), $10.7$, and $11.3$, as well as the (negative) heads $9.6$ and $10.6$ play a significant role in the task completion.
MS-IMAP -- A Multi-Scale Graph Embedding Approach for Interpretable Manifold Learning
Jun 06, 2024



Deriving meaningful representations from complex, high-dimensional data in unsupervised settings is crucial across diverse machine learning applications. This paper introduces a framework for multi-scale graph network embedding based on spectral graph wavelets that employs a contrastive learning approach. A significant feature of the proposed embedding is its capacity to establish a correspondence between the embedding space and the input feature space which aids in deriving feature importance of the original features. We theoretically justify our approach and demonstrate that, in Paley-Wiener spaces on combinatorial graphs, the spectral graph wavelets operator offers greater flexibility and better control over smoothness properties compared to the Laplacian operator. We validate the effectiveness of our proposed graph embedding on a variety of public datasets through a range of downstream tasks, including clustering and unsupervised feature importance.
Approximation of group explainers with coalition structure using Monte Carlo sampling on the product space of coalitions and features
Mar 17, 2023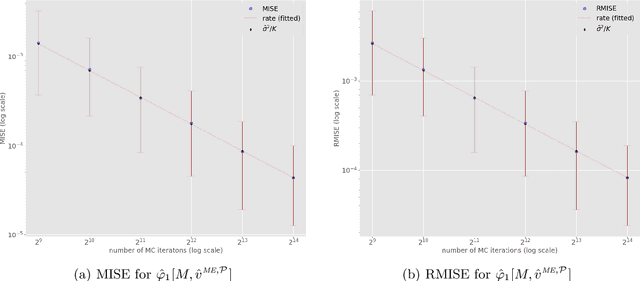
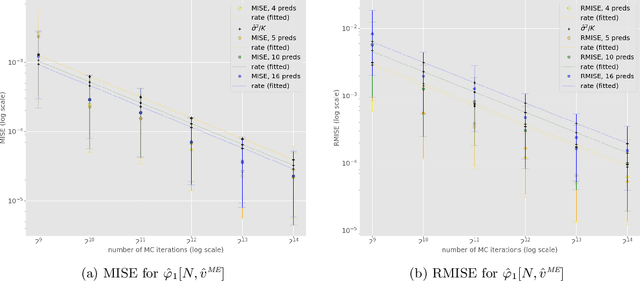
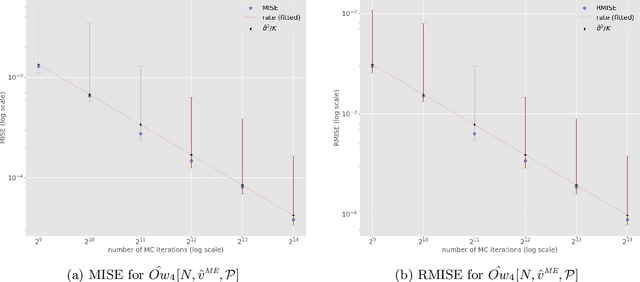
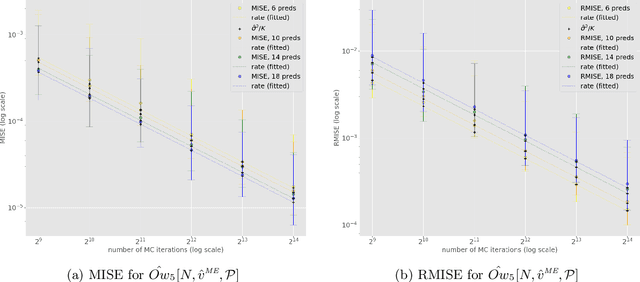
In recent years, many Machine Learning (ML) explanation techniques have been designed using ideas from cooperative game theory. These game-theoretic explainers suffer from high complexity, hindering their exact computation in practical settings. In our work, we focus on a wide class of linear game values, as well as coalitional values, for the marginal game based on a given ML model and predictor vector. By viewing these explainers as expectations over appropriate sample spaces, we design a novel Monte Carlo sampling algorithm that estimates them at a reduced complexity that depends linearly on the size of the background dataset. We set up a rigorous framework for the statistical analysis and obtain error bounds for our sampling methods. The advantage of this approach is that it is fast, easily implementable, and model-agnostic. Furthermore, it has similar statistical accuracy as other known estimation techniques that are more complex and model-specific. We provide rigorous proofs of statistical convergence, as well as numerical experiments whose results agree with our theoretical findings.
On marginal feature attributions of tree-based models
Feb 16, 2023Due to their power and ease of use, tree-based machine learning models have become very popular. To interpret these models, local feature attributions based on marginal expectations e.g. marginal (interventional) Shapley, Owen or Banzhaf values may be employed. Such feature attribution methods are true to the model and implementation invariant, i.e. dependent only on the input-output function of the model. By taking advantage of the internal structure of tree-based models, we prove that their marginal Shapley values, or more generally marginal feature attributions obtained from a linear game value, are simple (piecewise-constant) functions with respect to a certain finite partition of the input space determined by the trained model. The same is true for feature attributions obtained from the famous TreeSHAP algorithm. Nevertheless, we show that the "path-dependent" TreeSHAP is not implementation invariant by presenting two (statistically similar) decision trees computing the exact same function for which the algorithm yields different rankings of features, whereas the marginal Shapley values coincide. Furthermore, we discuss how the fact that marginal feature attributions are simple functions can potentially be utilized to compute them. An important observation, showcased by experiments with XGBoost, LightGBM and CatBoost libraries, is that only a portion of all features appears in a tree from the ensemble; thus the complexity of computing marginal Shapley (or Owen or Banzhaf) feature attributions may be reduced. In particular, in the case of CatBoost models, the trees are oblivious (symmetric) and the number of features in each of them is no larger than the depth. We exploit the symmetry to derive an explicit formula with improved complexity for marginal Shapley (and Banzhaf and Owen) values which is only in terms of the internal parameters of the CatBoost model.
Model-agnostic bias mitigation methods with regressor distribution control for Wasserstein-based fairness metrics
Nov 19, 2021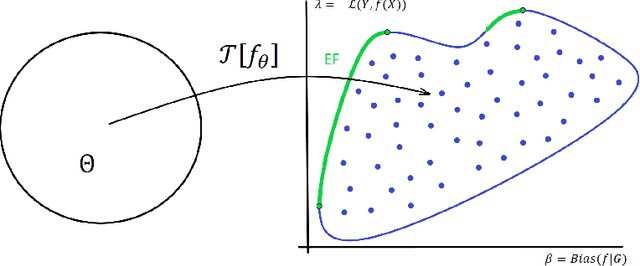
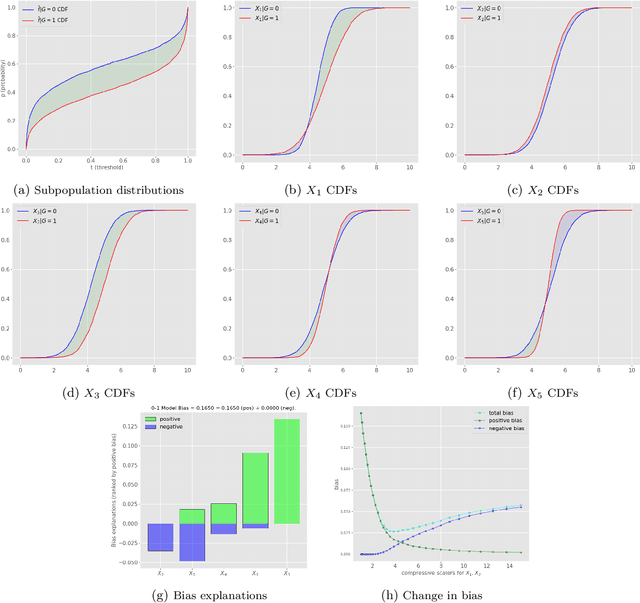
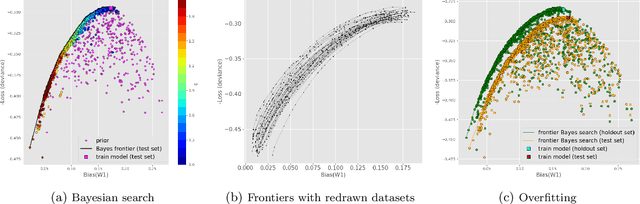
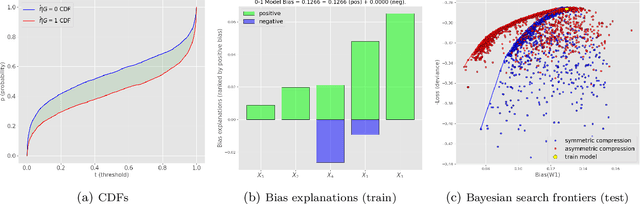
This article is a companion paper to our earlier work Miroshnikov et al. (2021) on fairness interpretability, which introduces bias explanations. In the current work, we propose a bias mitigation methodology based upon the construction of post-processed models with fairer regressor distributions for Wasserstein-based fairness metrics. By identifying the list of predictors contributing the most to the bias, we reduce the dimensionality of the problem by mitigating the bias originating from those predictors. The post-processing methodology involves reshaping the predictor distributions by balancing the positive and negative bias explanations and allows for the regressor bias to decrease. We design an algorithm that uses Bayesian optimization to construct the bias-performance efficient frontier over the family of post-processed models, from which an optimal model is selected. Our novel methodology performs optimization in low-dimensional spaces and avoids expensive model retraining.
Wasserstein-based fairness interpretability framework for machine learning models
Nov 06, 2020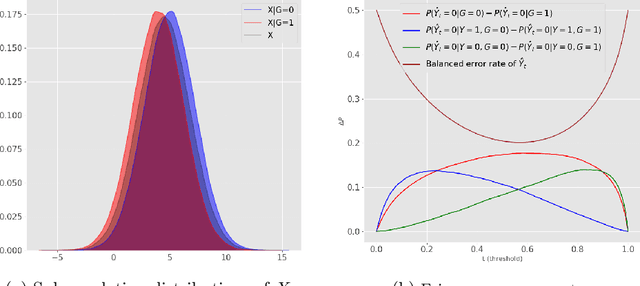
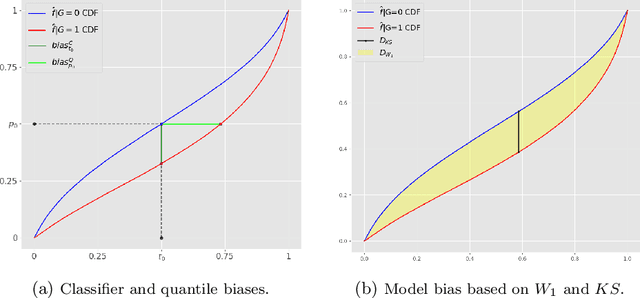
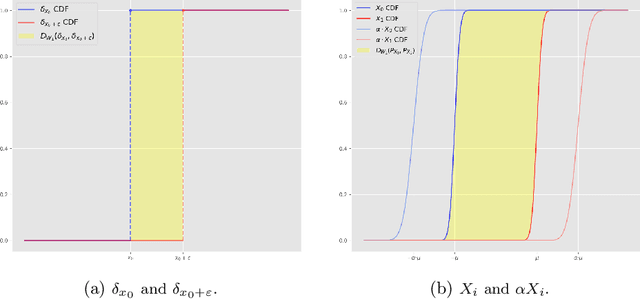
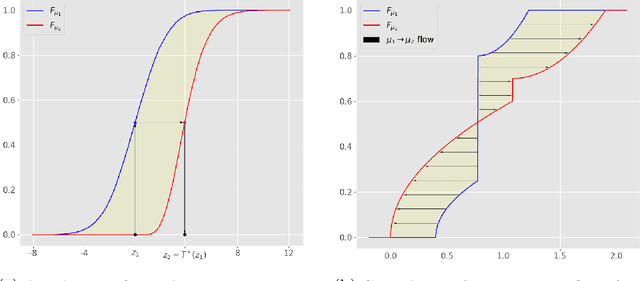
In this article, we introduce a fairness interpretability framework for measuring and explaining bias in classification and regression models at the level of a distribution. In our work, motivated by the ideas of Dwork et al. (2012), we measure the model bias across sub-population distributions using the Wasserstein metric. The transport theory characterization of the Wasserstein metric allows us to take into account the sign of the bias across the model distribution which in turn yields the decomposition of the model bias into positive and negative components. To understand how predictors contribute to the model bias, we introduce and theoretically characterize bias predictor attributions called bias explanations. We also provide the formulation for the bias explanations that take into account the impact of missing values. In addition, motivated by the works of Strumbelj and Kononenko (2014) and Lundberg and Lee (2017) we construct additive bias explanations by employing cooperative game theory.