 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable post-training bias mitigation with distribution-based fairness metrics
Apr 01, 2025We develop a novel optimization framework with distribution-based fairness constraints for efficiently producing demographically blind, explainable models across a wide range of fairness levels. This is accomplished through post-processing, avoiding the need for retraining. Our framework, which is based on stochastic gradient descent, can be applied to a wide range of model types, with a particular emphasis on the post-processing of gradient-boosted decision trees. Additionally, we design a broad class of interpretable global bias metrics compatible with our method by building on previous work. We empirically test our methodology on a variety of datasets and compare it to other methods.
MBExplainer: Multilevel bandit-based explanations for downstream models with augmented graph embeddings
Nov 01, 2024In many industrial applications, it is common that the graph embeddings generated from training GNNs are used in an ensemble model where the embeddings are combined with other tabular features (e.g., original node or edge features) in a downstream ML task. The tabular features may even arise naturally if, e.g., one tries to build a graph such that some of the node or edge features are stored in a tabular format. Here we address the problem of explaining the output of such ensemble models for which the input features consist of learned neural graph embeddings combined with additional tabular features. We propose MBExplainer, a model-agnostic explanation approach for downstream models with augmented graph embeddings. MBExplainer returns a human-legible triple as an explanation for an instance prediction of the whole pipeline consisting of three components: a subgraph with the highest importance, the topmost important nodal features, and the topmost important augmented downstream features. A game-theoretic formulation is used to take the contributions of each component and their interactions into account by assigning three Shapley values corresponding to their own specific games. Finding the explanation requires an efficient search through the corresponding local search spaces corresponding to each component. MBExplainer applies a novel multilevel search algorithm that enables simultaneous pruning of local search spaces in a computationally tractable way. In particular, three interweaved Monte Carlo Tree Search are utilized to iteratively prune the local search spaces. MBExplainer also includes a global search algorithm that uses contextual bandits to efficiently allocate pruning budget among the local search spaces. We show the effectiveness of MBExplainer by presenting a set of comprehensive numerical examples on multiple public graph datasets for both node and graph classification tasks.
Model-agnostic bias mitigation methods with regressor distribution control for Wasserstein-based fairness metrics
Nov 19, 2021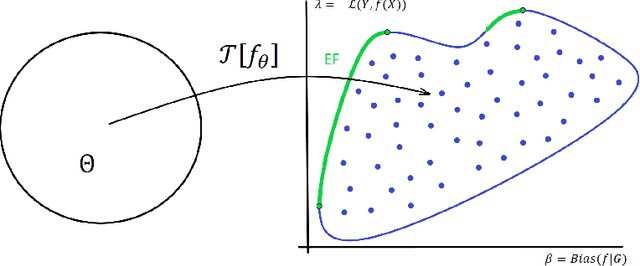
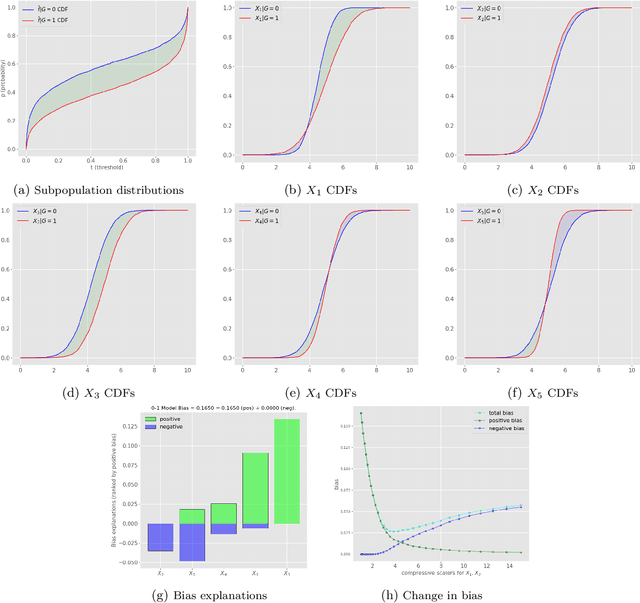
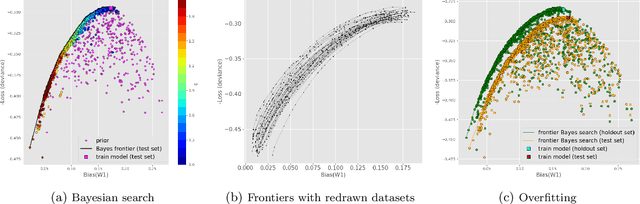
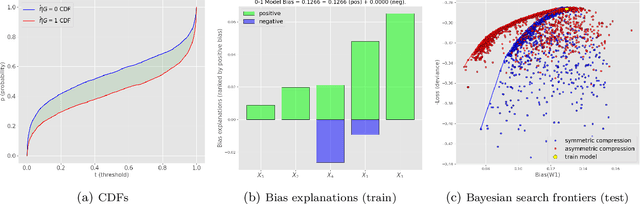
This article is a companion paper to our earlier work Miroshnikov et al. (2021) on fairness interpretability, which introduces bias explanations. In the current work, we propose a bias mitigation methodology based upon the construction of post-processed models with fairer regressor distributions for Wasserstein-based fairness metrics. By identifying the list of predictors contributing the most to the bias, we reduce the dimensionality of the problem by mitigating the bias originating from those predictors. The post-processing methodology involves reshaping the predictor distributions by balancing the positive and negative bias explanations and allows for the regressor bias to decrease. We design an algorithm that uses Bayesian optimization to construct the bias-performance efficient frontier over the family of post-processed models, from which an optimal model is selected. Our novel methodology performs optimization in low-dimensional spaces and avoids expensive model retraining.
Wasserstein-based fairness interpretability framework for machine learning models
Nov 06, 2020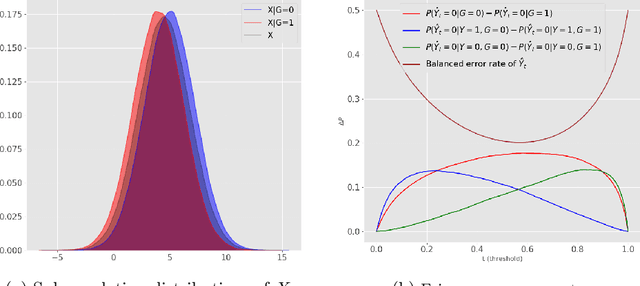
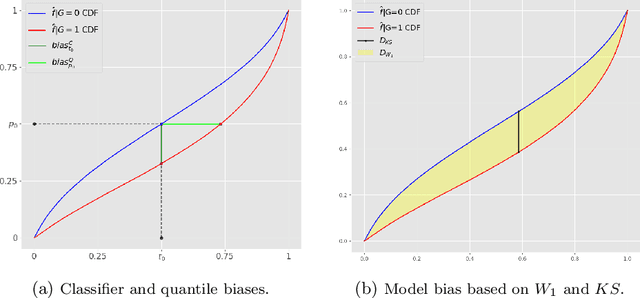
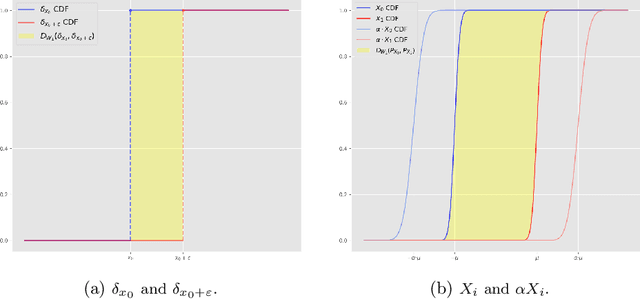
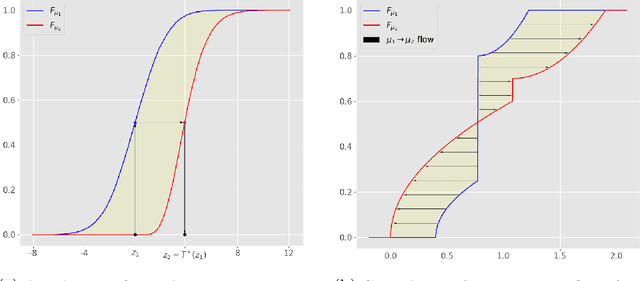
In this article, we introduce a fairness interpretability framework for measuring and explaining bias in classification and regression models at the level of a distribution. In our work, motivated by the ideas of Dwork et al. (2012), we measure the model bias across sub-population distributions using the Wasserstein metric. The transport theory characterization of the Wasserstein metric allows us to take into account the sign of the bias across the model distribution which in turn yields the decomposition of the model bias into positive and negative components. To understand how predictors contribute to the model bias, we introduce and theoretically characterize bias predictor attributions called bias explanations. We also provide the formulation for the bias explanations that take into account the impact of missing values. In addition, motivated by the works of Strumbelj and Kononenko (2014) and Lundberg and Lee (2017) we construct additive bias explanations by employing cooperative game theory.