 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Panoptic Segmentation from Dense Detections
Dec 04, 2019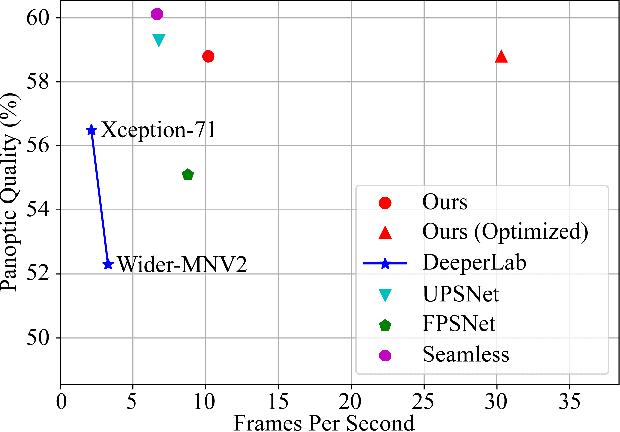
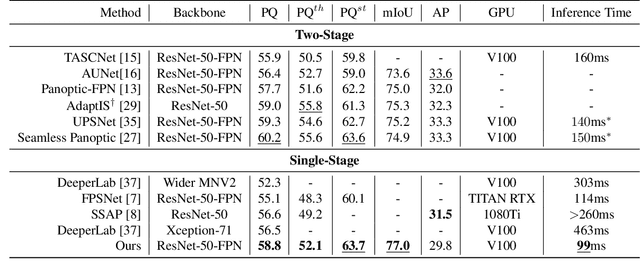
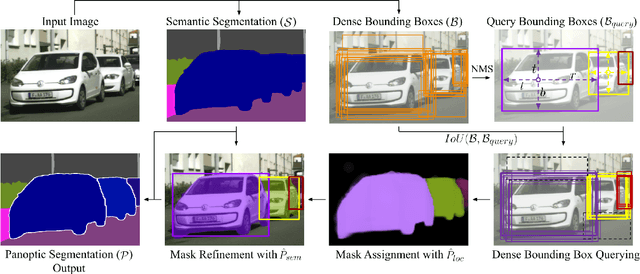
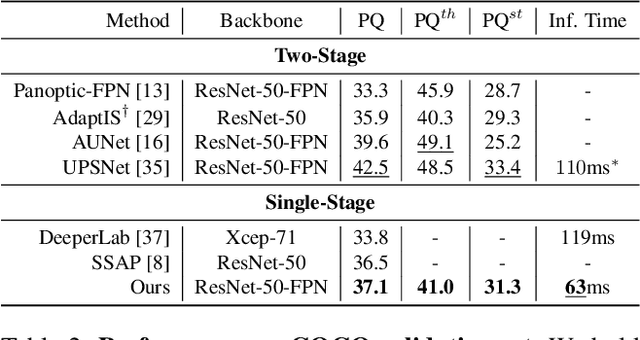
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Autolabeling 3D Objects with Differentiable Rendering of SDF Shape Priors
Nov 26, 2019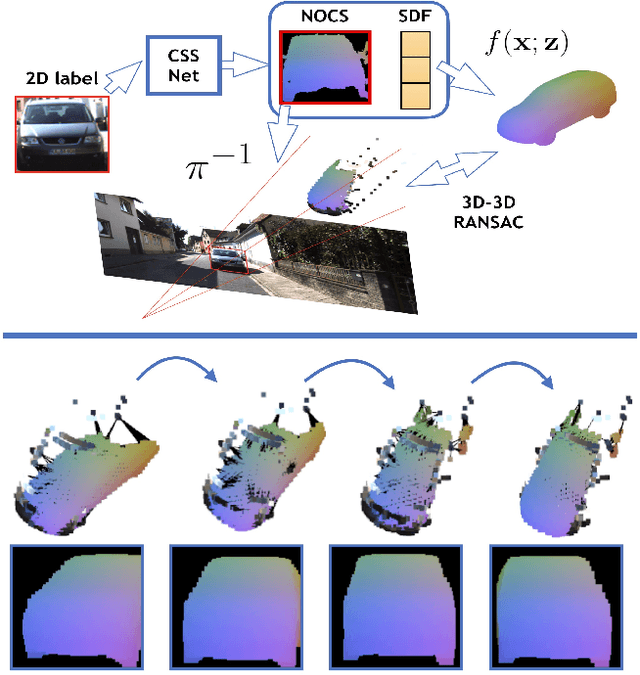



We present an automatic annotation pipeline to recover 9D cuboids and 3D shape from pre-trained off-the-shelf 2D detectors and sparse LIDAR data. Our autolabeling method solves this challenging ill-posed inverse problem by relying on learned shape priors and optimization of geometric and physical parameters. To that end, we propose a novel differentiable shape renderer over signed distance fields (SDF), which we leverage in combination with normalized object coordinate spaces (NOCS). Initially trained on synthetic data to predict shape and coordinates, our method uses these predictions for projective and geometrical alignment over real samples. We also propose a curriculum learning strategy, iteratively retraining on samples of increasing difficulty for subsequent self-improving annotation rounds. Our experiments on the KITTI3D dataset show that we can recover a substantial amount of accurate cuboids, and that these autolabels can be used to train 3D vehicle detectors with state-of-the-art results. We will make the code publicly available soon.
Learning to Fuse Things and Stuff
Dec 04, 2018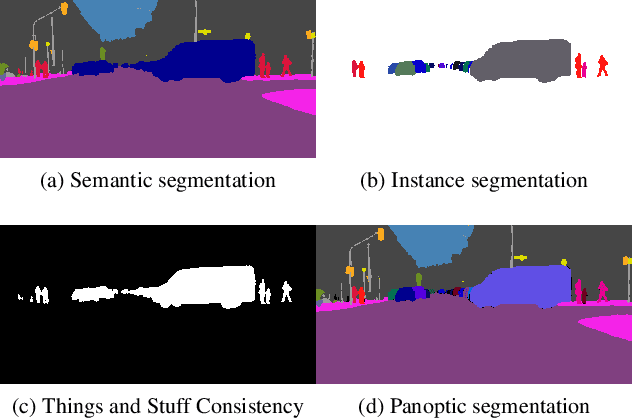
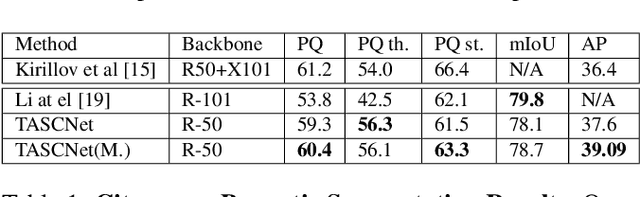
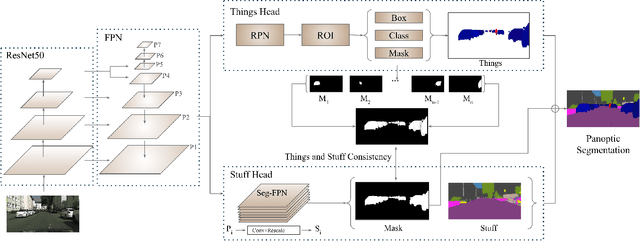

We propose an end-to-end learning approach for panoptic segmentation, a novel task unifying instance (things) and semantic (stuff) segmentation. Our model, TASCNet, uses feature maps from a shared backbone network to predict in a single feed-forward pass both things and stuff segmentations. We explicitly constrain these two output distributions through a global things and stuff binary mask to enforce cross-task consistency. Our proposed unified network is competitive with the state of the art on several benchmarks for panoptic segmentation as well as on the individual semantic and instance segmentation tasks.