 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Autonomous Approach to Measure Social Distances and Hygienic Practices during COVID-19 Pandemic in Public Open Spaces
Nov 14, 2020
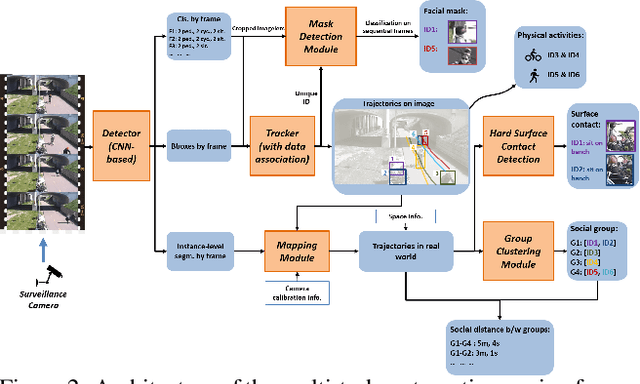
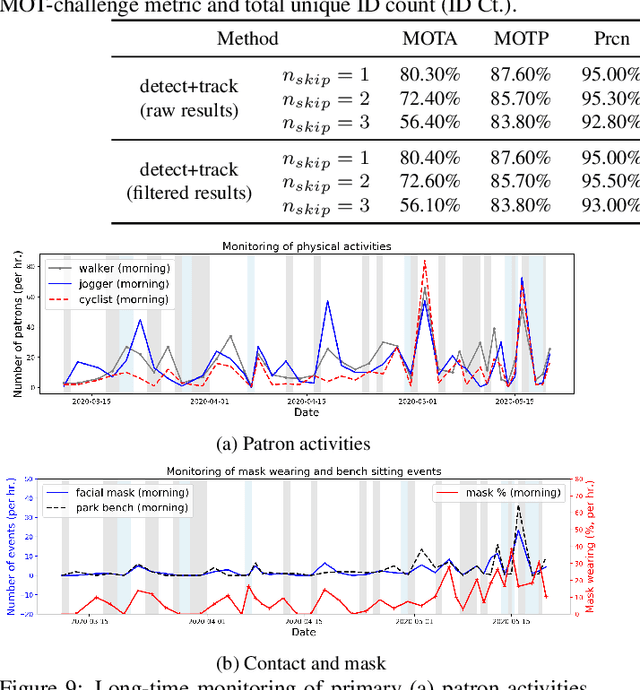
Coronavirus has been spreading around the world since the end of 2019. The virus can cause acute respiratory syndrome, which can be lethal, and is easily transmitted between hosts. Most states have issued state-at-home executive orders, however, parks and other public open spaces have largely remained open and are seeing sharp increases in public use. Therefore, in order to ensure public safety, it is imperative for patrons of public open spaces to practice safe hygiene and take preventative measures. This work provides a scalable sensing approach to detect physical activities within public open spaces and monitor adherence to social distancing guidelines suggested by the US Centers for Disease Control and Prevention (CDC). A deep learning-based computer vision sensing framework is designed to investigate the careful and proper utilization of parks and park facilities with hard surfaces (e.g. benches, fence poles, and trash cans) using video feeds from a pre-installed surveillance camera network. The sensing framework consists of a CNN-based object detector, a multi-target tracker, a mapping module, and a group reasoning module. The experiments are carried out during the COVID-19 pandemic between March 2020 and May 2020 across several key locations at the Detroit Riverfront Parks in Detroit, Michigan. The sensing framework is validated by comparing automatic sensing results with manually labeled ground-truth results. The proposed approach significantly improves the efficiency of providing spatial and temporal statistics of users in public open spaces by creating straightforward data visualizations for federal and state agencies. The results can also provide on-time triggering information for an alarming or actuator system which can later be added to intervene inappropriate behavior during this pandemic.
Measuring the Utilization of Public Open Spaces by Deep Learning: a Benchmark Study at the Detroit Riverfront
Feb 04, 2020
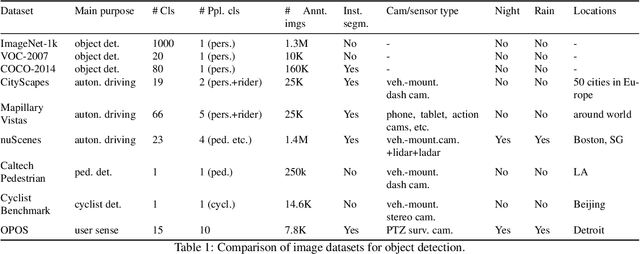

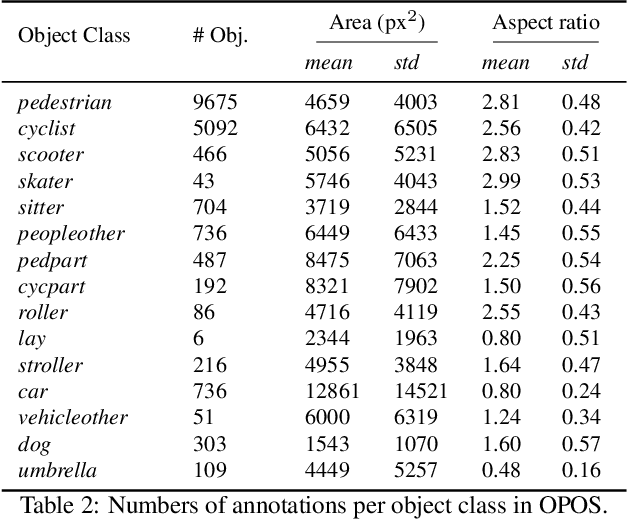
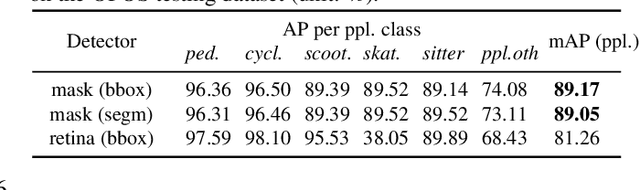
Physical activities and social interactions are essential activities that ensure a healthy lifestyle. Public open spaces (POS), such as parks, plazas and greenways, are key environments that encourage those activities. To evaluate a POS, there is a need to study how humans use the facilities within it. However, traditional approaches to studying use of POS are manual and therefore time and labor intensive. They also may only provide qualitative insights. It is appealing to make use of surveillance cameras and to extract user-related information through computer vision. This paper proposes a proof-of-concept deep learning computer vision framework for measuring human activities quantitatively in POS and demonstrates a case study of the proposed framework using the Detroit Riverfront Conservancy (DRFC) surveillance camera network. A custom image dataset is presented to train the framework; the dataset includes 7826 fully annotated images collected from 18 cameras across the DRFC park space under various illumination conditions. Dataset analysis is also provided as well as a baseline model for one-step user localization and activity recognition. The mAP results are 77.5\% for {\it pedestrian} detection and 81.6\% for {\it cyclist} detection. Behavioral maps are autonomously generated by the framework to locate different POS users and the average error for behavioral localization is within 10 cm.
Real-Time Panoptic Segmentation from Dense Detections
Dec 04, 2019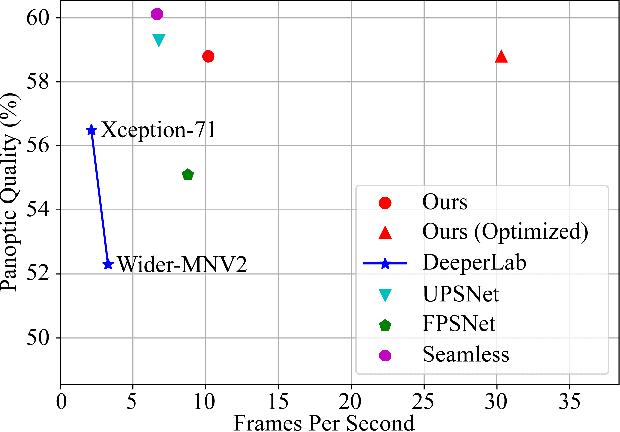
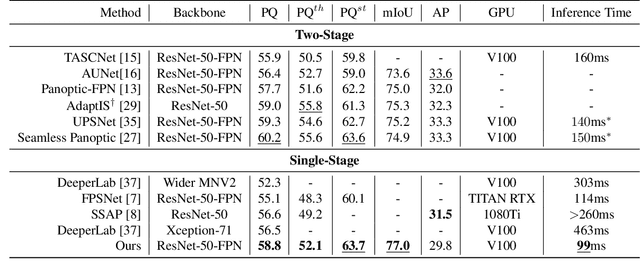
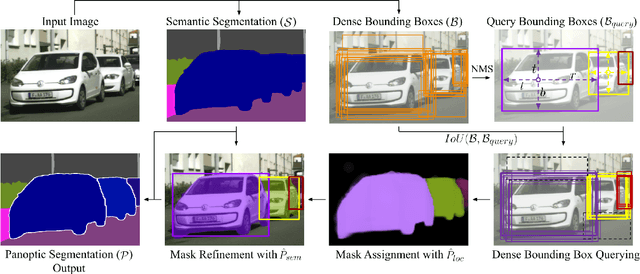
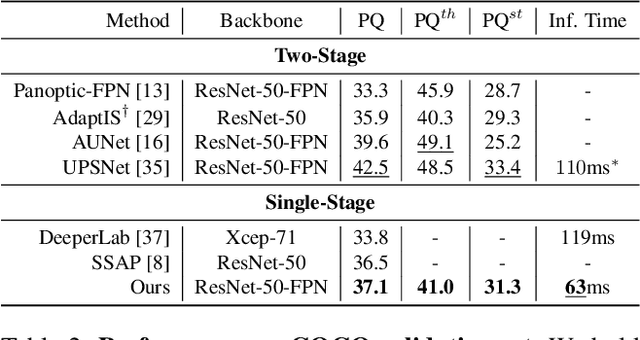
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.