 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory of generative Artificial Intelligence (AI) chatbots: past, present, and future development
Feb 04, 2024This research provides an in-depth comprehensive review of the progress of chatbot technology over time, from the initial basic systems relying on rules to today's advanced conversational bots powered by artificial intelligence. Spanning many decades, the paper explores the major milestones, innovations, and paradigm shifts that have driven the evolution of chatbots. Looking back at the very basic statistical model in 1906 via the early chatbots, such as ELIZA and ALICE in the 1960s and 1970s, the study traces key innovations leading to today's advanced conversational agents, such as ChatGPT and Google Bard. The study synthesizes insights from academic literature and industry sources to highlight crucial milestones, including the introduction of Turing tests, influential projects such as CALO, and recent transformer-based models. Tracing the path forward, the paper highlights how natural language processing and machine learning have been integrated into modern chatbots for more sophisticated capabilities. This chronological survey of the chatbot landscape provides a holistic reference to understand the technological and historical factors propelling conversational AI. By synthesizing learnings from this historical analysis, the research offers important context about the developmental trajectory of chatbots and their immense future potential across various field of application which could be the potential take ways for the respective research community and stakeholders.
Deep Reinforcement Learning to Maximize Arterial Usage during Extreme Congestion
May 16, 2023



Collisions, crashes, and other incidents on road networks, if left unmitigated, can potentially cause cascading failures that can affect large parts of the system. Timely handling such extreme congestion scenarios is imperative to reduce emissions, enhance productivity, and improve the quality of urban living. In this work, we propose a Deep Reinforcement Learning (DRL) approach to reduce traffic congestion on multi-lane freeways during extreme congestion. The agent is trained to learn adaptive detouring strategies for congested freeway traffic such that the freeway lanes along with the local arterial network in proximity are utilized optimally, with rewards being congestion reduction and traffic speed improvement. The experimental setup is a 2.6-mile-long 4-lane freeway stretch in Shoreline, Washington, USA with two exits and associated arterial roads simulated on a microscopic and continuous multi-modal traffic simulator SUMO (Simulation of Urban MObility) while using parameterized traffic profiles generated using real-world traffic data. Our analysis indicates that DRL-based controllers can improve average traffic speed by 21\% when compared to no-action during steep congestion. The study further discusses the trade-offs involved in the choice of reward functions, the impact of human compliance on agent performance, and the feasibility of knowledge transfer from one agent to other to address data sparsity and scaling issues.
A Finite State Transducer Based Morphological Analyzer of Maithili Language
Feb 29, 2020
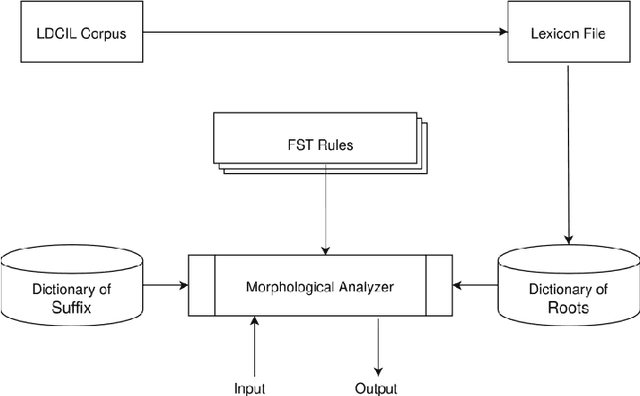
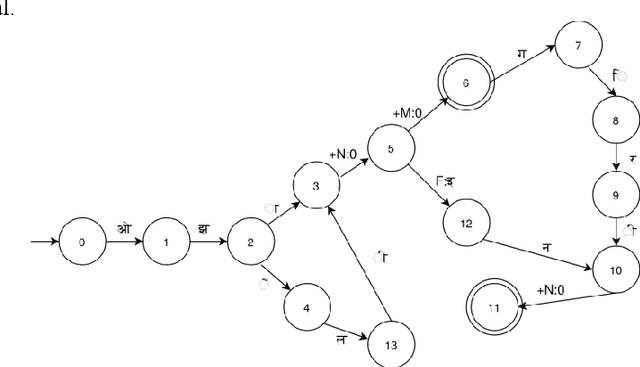
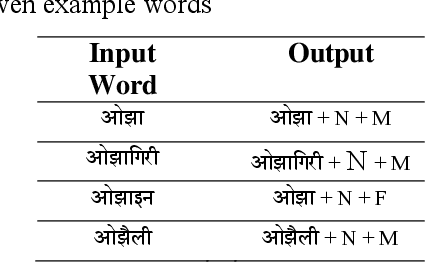
Morphological analyzers are the essential milestones for many linguistic applications like; machine translation, word sense disambiguation, spells checkers, and search engines etc. Therefore, development of an effective morphological analyzer has a greater impact on the computational recognition of a language. In this paper, we present a finite state transducer based inflectional morphological analyzer for a resource poor language of India, known as Maithili. Maithili is an eastern Indo-Aryan language spoken in the eastern and northern regions of Bihar in India and the southeastern plains, known as tarai of Nepal. This work can be recognized as the first work towards the computational development of Maithili which may attract researchers around the country to up-rise the language to establish in computational world.
Street-level Travel-time Estimation via Aggregated Uber Data
Jan 13, 2020
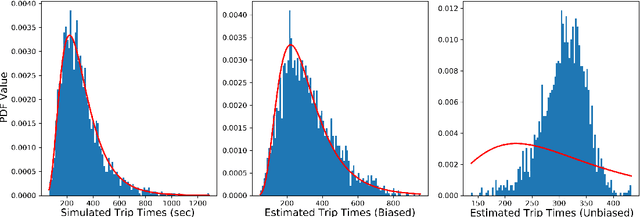
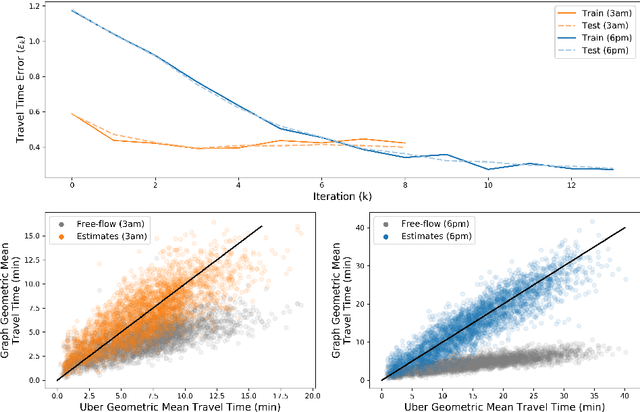
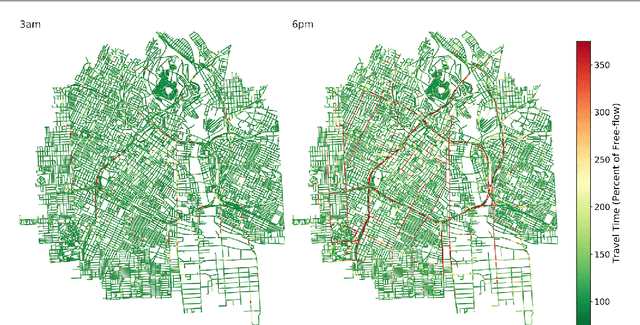
Estimating temporal patterns in travel times along road segments in urban settings is of central importance to traffic engineers and city planners. In this work, we propose a methodology to leverage coarse-grained and aggregated travel time data to estimate the street-level travel times of a given metropolitan area. Our main focus is to estimate travel times along the arterial road segments where relevant data are often unavailable. The central idea of our approach is to leverage easy-to-obtain, aggregated data sets with broad spatial coverage, such as the data published by Uber Movement, as the fabric over which other expensive, fine-grained datasets, such as loop counter and probe data, can be overlaid. Our proposed methodology uses a graph representation of the road network and combines several techniques such as graph-based routing, trip sampling, graph sparsification, and least-squares optimization to estimate the street-level travel times. Using sampled trips and weighted shortest-path routing, we iteratively solve constrained least-squares problems to obtain the travel time estimates. We demonstrate our method on the Los Angeles metropolitan-area street network, where aggregated travel time data is available for trips between traffic analysis zones. Additionally, we present techniques to scale our approach via a novel graph pseudo-sparsification technique.
A Multimodal Corpus of Expert Gaze and Behavior during Phonetic Segmentation Tasks
May 11, 2018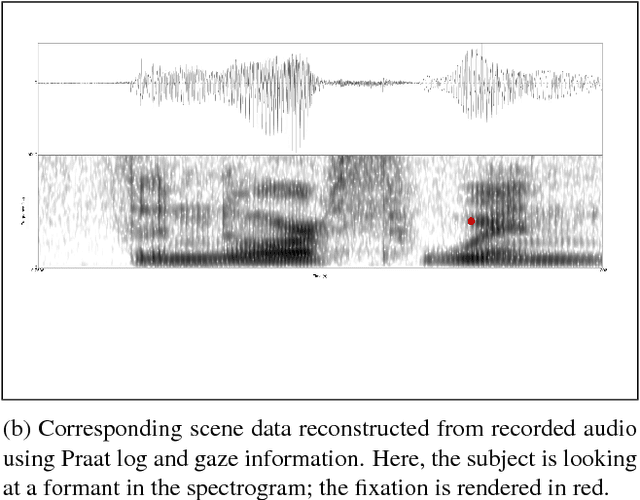

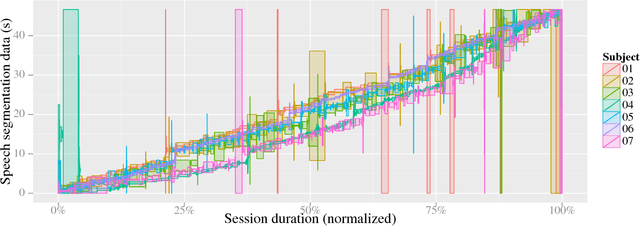
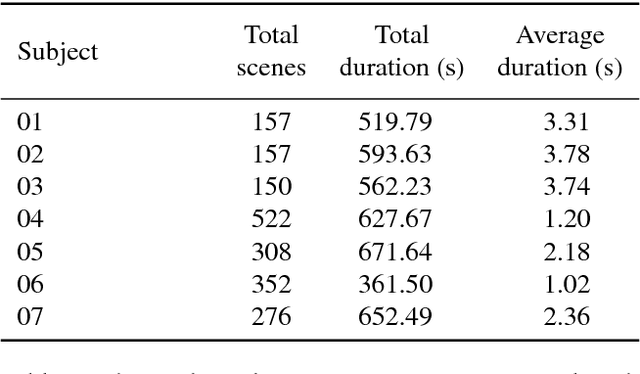
Phonetic segmentation is the process of splitting speech into distinct phonetic units. Human experts routinely perform this task manually by analyzing auditory and visual cues using analysis software, which is an extremely time-consuming process. Methods exist for automatic segmentation, but these are not always accurate enough. In order to improve automatic segmentation, we need to model it as close to the manual segmentation as possible. This corpus is an effort to capture the human segmentation behavior by recording experts performing a segmentation task. We believe that this data will enable us to highlight the important aspects of manual segmentation, which can be used in automatic segmentation to improve its accuracy.