 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cloud-based Multi-Agentic Workflow for Science
Jan 18, 2026As Large Language Models (LLMs) become ubiquitous across various scientific domains, their lack of ability to perform complex tasks like running simulations or to make complex decisions limits their utility. LLM-based agents bridge this gap due to their ability to call external resources and tools and thus are now rapidly gaining popularity. However, coming up with a workflow that can balance the models, cloud providers, and external resources is very challenging, making implementing an agentic system more of a hindrance than a help. In this work, we present a domain-agnostic, model-independent workflow for an agentic framework that can act as a scientific assistant while being run entirely on cloud. Built with a supervisor agent marshaling an array of agents with individual capabilities, our framework brings together straightforward tasks like literature review and data analysis with more complex ones like simulation runs. We describe the framework here in full, including a proof-of-concept system we built to accelerate the study of Catalysts, which is highly important in the field of Chemistry and Material Science. We report the cost to operate and use this framework, including the breakdown of the cost by services use. We also evaluate our system on a custom-curated synthetic benchmark and a popular Chemistry benchmark, and also perform expert validation of the system. The results show that our system is able to route the task to the correct agent 90% of the time and successfully complete the assigned task 97.5% of the time for the synthetic tasks and 91% of the time for real-world tasks, while still achieving better or comparable accuracy to most frontier models, showing that this is a viable framework for other scientific domains to replicate.
Street-level Travel-time Estimation via Aggregated Uber Data
Jan 13, 2020
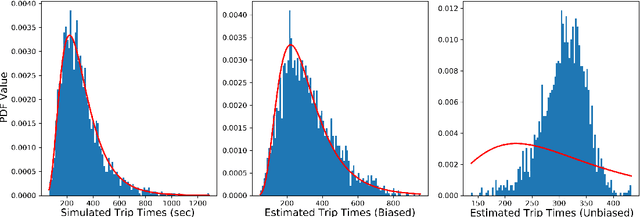
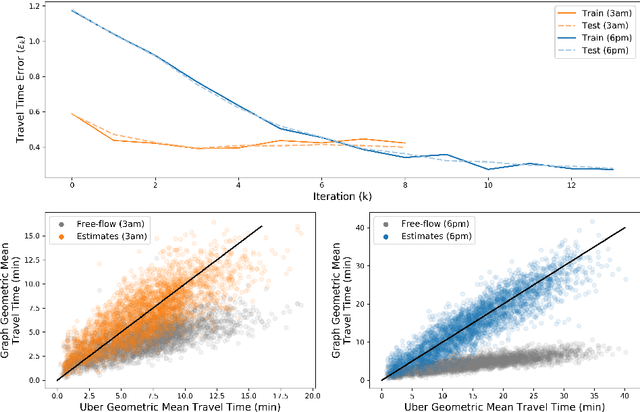
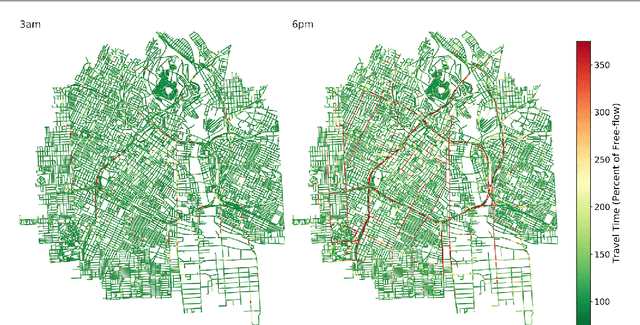
Estimating temporal patterns in travel times along road segments in urban settings is of central importance to traffic engineers and city planners. In this work, we propose a methodology to leverage coarse-grained and aggregated travel time data to estimate the street-level travel times of a given metropolitan area. Our main focus is to estimate travel times along the arterial road segments where relevant data are often unavailable. The central idea of our approach is to leverage easy-to-obtain, aggregated data sets with broad spatial coverage, such as the data published by Uber Movement, as the fabric over which other expensive, fine-grained datasets, such as loop counter and probe data, can be overlaid. Our proposed methodology uses a graph representation of the road network and combines several techniques such as graph-based routing, trip sampling, graph sparsification, and least-squares optimization to estimate the street-level travel times. Using sampled trips and weighted shortest-path routing, we iteratively solve constrained least-squares problems to obtain the travel time estimates. We demonstrate our method on the Los Angeles metropolitan-area street network, where aggregated travel time data is available for trips between traffic analysis zones. Additionally, we present techniques to scale our approach via a novel graph pseudo-sparsification technique.
Snomed2Vec: Random Walk and Poincaré Embeddings of a Clinical Knowledge Base for Healthcare Analytics
Jul 19, 2019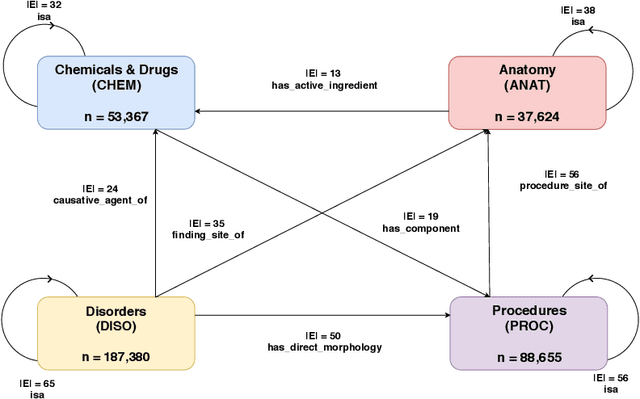
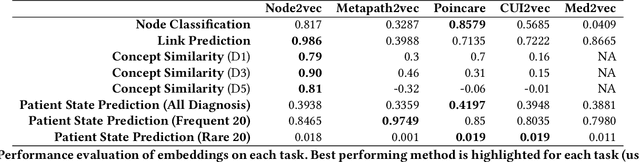
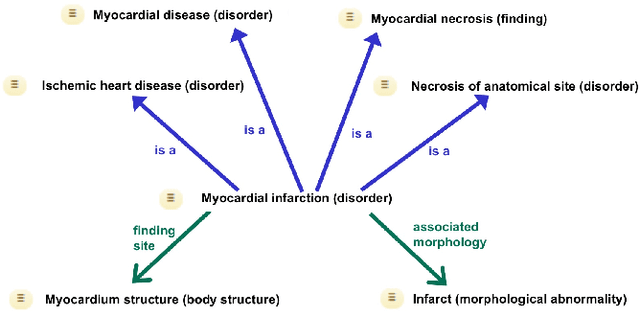

Representation learning methods that transform encoded data (e.g., diagnosis and drug codes) into continuous vector spaces (i.e., vector embeddings) are critical for the application of deep learning in healthcare. Initial work in this area explored the use of variants of the word2vec algorithm to learn embeddings for medical concepts from electronic health records or medical claims datasets. We propose learning embeddings for medical concepts by using graph-based representation learning methods on SNOMED-CT, a widely popular knowledge graph in the healthcare domain with numerous operational and research applications. Current work presents an empirical analysis of various embedding methods, including the evaluation of their performance on multiple tasks of biomedical relevance (node classification, link prediction, and patient state prediction). Our results show that concept embeddings derived from the SNOMED-CT knowledge graph significantly outperform state-of-the-art embeddings, showing 5-6x improvement in ``concept similarity" and 6-20\% improvement in patient diagnosis.