 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finite State Transducer Based Morphological Analyzer of Maithili Language
Feb 29, 2020
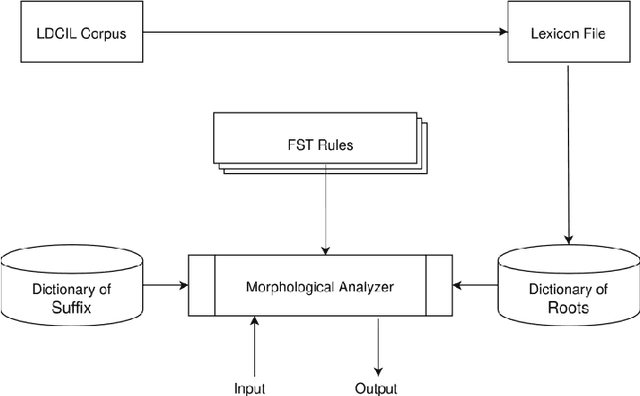
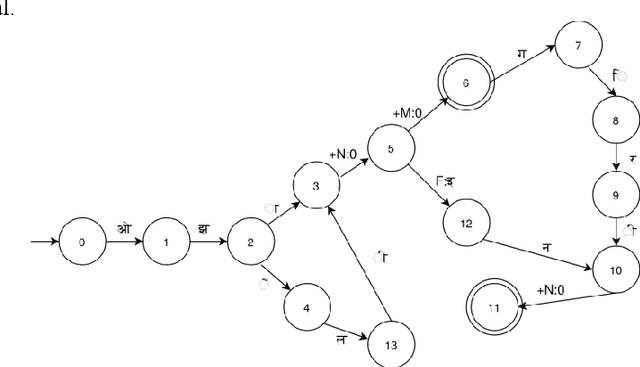
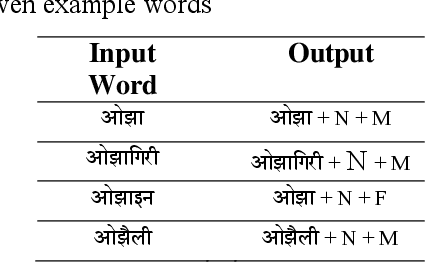
Morphological analyzers are the essential milestones for many linguistic applications like; machine translation, word sense disambiguation, spells checkers, and search engines etc. Therefore, development of an effective morphological analyzer has a greater impact on the computational recognition of a language. In this paper, we present a finite state transducer based inflectional morphological analyzer for a resource poor language of India, known as Maithili. Maithili is an eastern Indo-Aryan language spoken in the eastern and northern regions of Bihar in India and the southeastern plains, known as tarai of Nepal. This work can be recognized as the first work towards the computational development of Maithili which may attract researchers around the country to up-rise the language to establish in computational world.
Morphological Analysis of the Bishnupriya Manipuri Language using Finite State Transducers
Apr 22, 2014



In this work we present a morphological analysis of Bishnupriya Manipuri language, an Indo-Aryan language spoken in the north eastern India. As of now, there is no computational work available for the language. Finite state morphology is one of the successful approaches applied in a wide variety of languages over the year. Therefore we adapted the finite state approach to analyse morphology of the Bishnupriya Manipuri language.
Towards The Development of a Bishnupriya Manipuri Corpus
Dec 11, 2013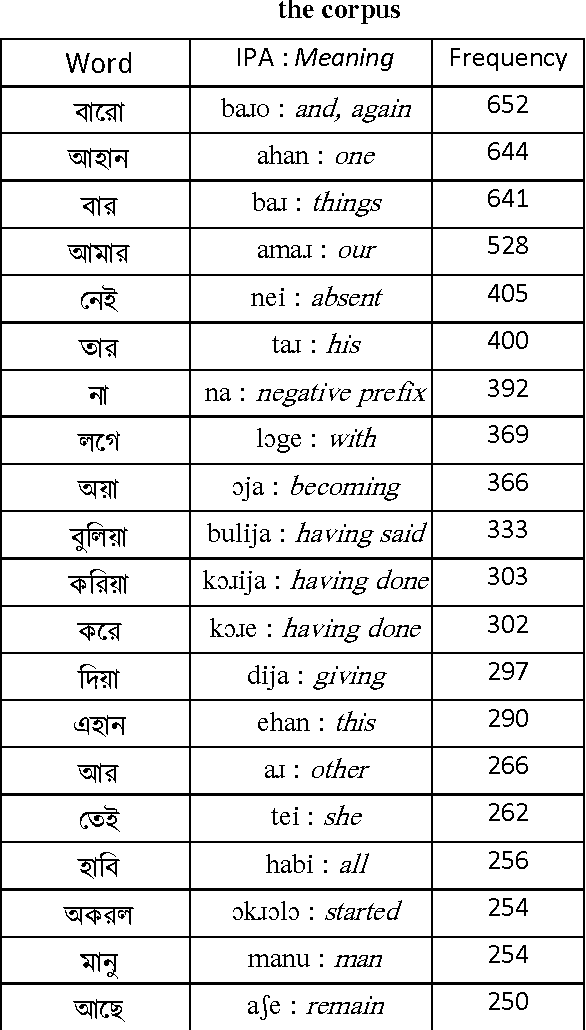
For any deep computational processing of language we need evidences, and one such set of evidences is corpus. This paper describes the development of a text-based corpus for the Bishnupriya Manipuri language. A Corpus is considered as a building block for any language processing tasks. Due to the lack of awareness like other Indian languages, it is also studied less frequently. As a result the language still lacks a good corpus and basic language processing tools. As per our knowledge this is the first effort to develop a corpus for Bishnupriya Manipuri language.
Development and Transcription of Assamese Speech Corpus
Sep 27, 2013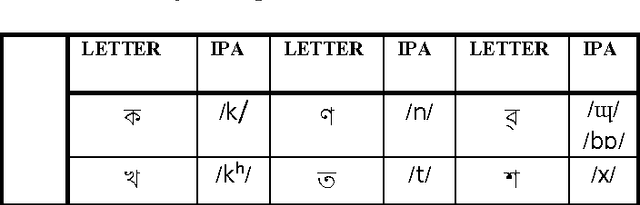
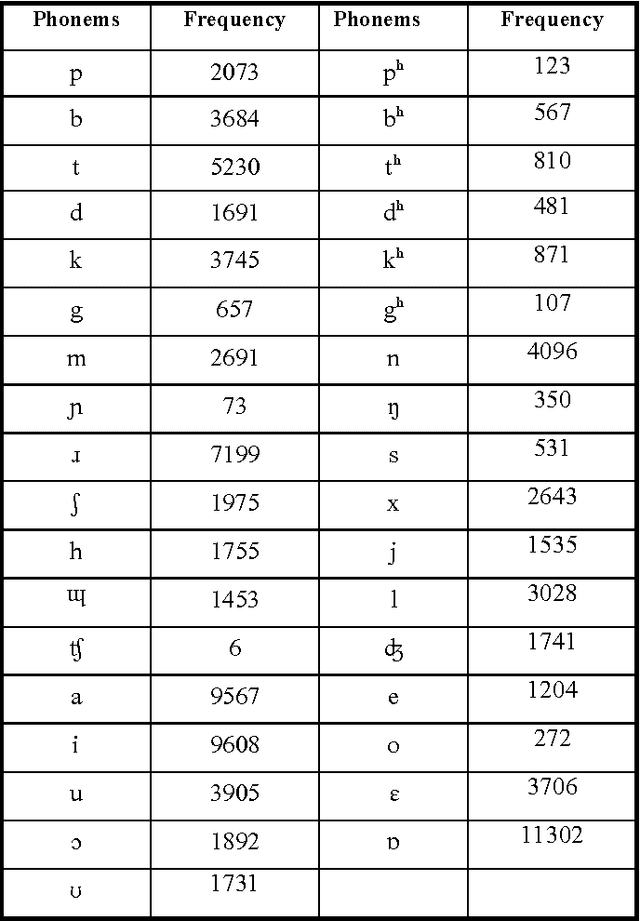
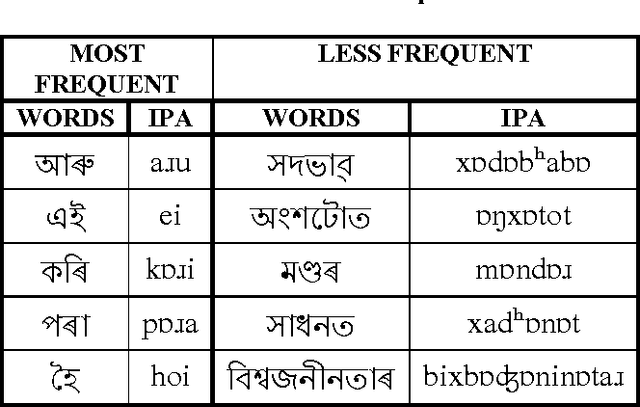
A balanced speech corpus is the basic need for any speech processing task. In this report we describe our effort on development of Assamese speech corpus. We mainly focused on some issues and challenges faced during development of the corpus. Being a less computationally aware language, this is the first effort to develop speech corpus for Assamese. As corpus development is an ongoing process, in this paper we report only the initial task.