 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBengali to Assamese Statistical Machine Translation using Moses (Corpus Based)
Apr 06, 2015



Machine dialect interpretation assumes a real part in encouraging man-machine correspondence and in addition men-men correspondence in Natural Language Processing (NLP). Machine Translation (MT) alludes to utilizing machine to change one dialect to an alternate. Statistical Machine Translation is a type of MT consisting of Language Model (LM), Translation Model (TM) and decoder. In this paper, Bengali to Assamese Statistical Machine Translation Model has been created by utilizing Moses. Other translation tools like IRSTLM for Language Model and GIZA-PP-V1.0.7 for Translation model are utilized within this framework which is accessible in Linux situations. The purpose of the LM is to encourage fluent output and the purpose of TM is to encourage similarity between input and output, the decoder increases the probability of translated text in target language. A parallel corpus of 17100 sentences in Bengali and Assamese has been utilized for preparing within this framework. Measurable MT procedures have not so far been generally investigated for Indian dialects. It might be intriguing to discover to what degree these models can help the immense continuous MT deliberations in the nation.
Morphological Analysis of the Bishnupriya Manipuri Language using Finite State Transducers
Apr 22, 2014



In this work we present a morphological analysis of Bishnupriya Manipuri language, an Indo-Aryan language spoken in the north eastern India. As of now, there is no computational work available for the language. Finite state morphology is one of the successful approaches applied in a wide variety of languages over the year. Therefore we adapted the finite state approach to analyse morphology of the Bishnupriya Manipuri language.
Towards The Development of a Bishnupriya Manipuri Corpus
Dec 11, 2013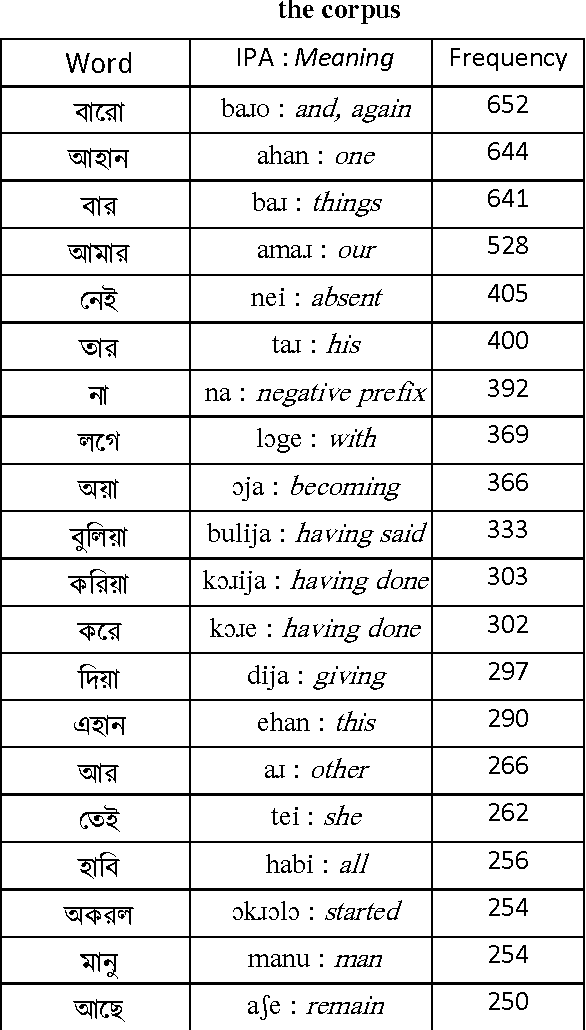
For any deep computational processing of language we need evidences, and one such set of evidences is corpus. This paper describes the development of a text-based corpus for the Bishnupriya Manipuri language. A Corpus is considered as a building block for any language processing tasks. Due to the lack of awareness like other Indian languages, it is also studied less frequently. As a result the language still lacks a good corpus and basic language processing tools. As per our knowledge this is the first effort to develop a corpus for Bishnupriya Manipuri language.