Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards The Development of a Bishnupriya Manipuri Corpus
Paper and Code
Dec 11, 2013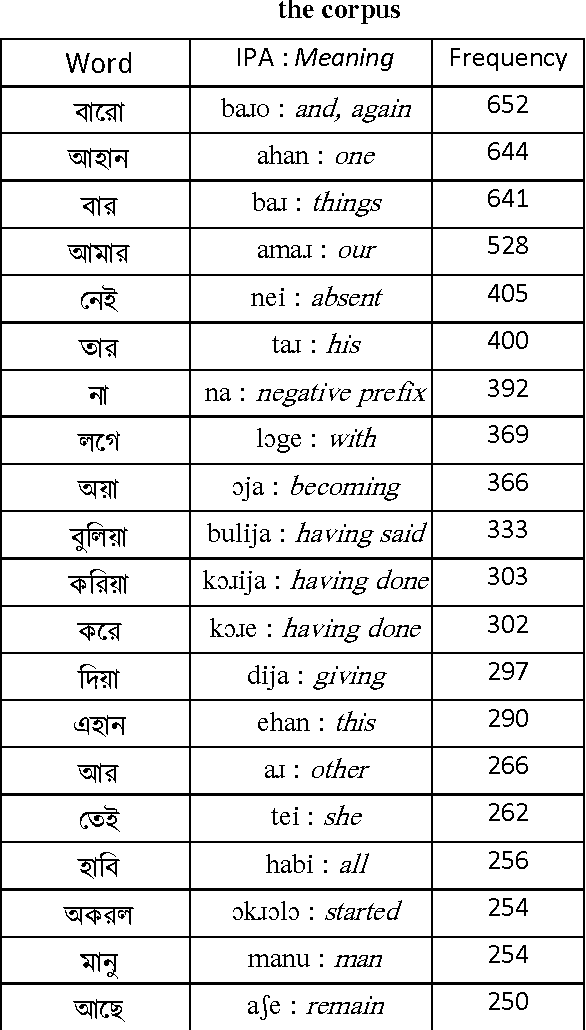
For any deep computational processing of language we need evidences, and one such set of evidences is corpus. This paper describes the development of a text-based corpus for the Bishnupriya Manipuri language. A Corpus is considered as a building block for any language processing tasks. Due to the lack of awareness like other Indian languages, it is also studied less frequently. As a result the language still lacks a good corpus and basic language processing tools. As per our knowledge this is the first effort to develop a corpus for Bishnupriya Manipuri language.
* 5 pages, conference at National Conference on Recent Trends in
Computer Sciences at Bodoland University, 25th-26th March, 2013
View paper on