 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating New Language and Voice Components for the Updated MaryTTS Text-to-Speech Synthesis Platform
May 11, 2018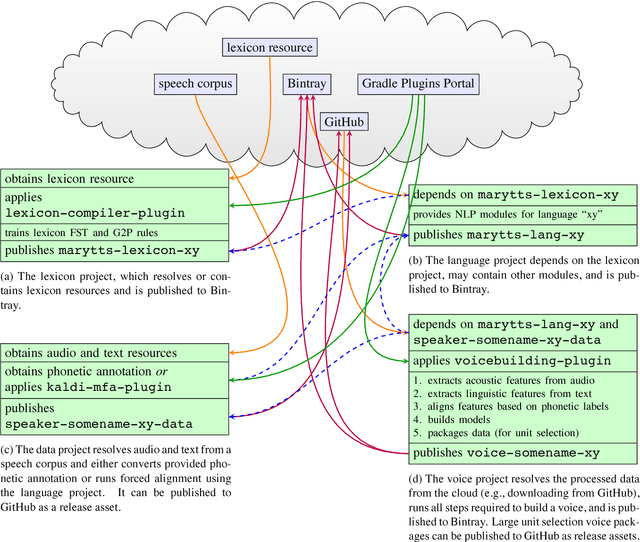
We present a new workflow to create components for the MaryTTS text-to-speech synthesis platform, which is popular with researchers and developers, extending it to support new languages and custom synthetic voices. This workflow replaces the previous toolkit with an efficient, flexible process that leverages modern build automation and cloud-hosted infrastructure. Moreover, it is compatible with the updated MaryTTS architecture, enabling new features and state-of-the-art paradigms such as synthesis based on deep neural networks (DNNs). Like MaryTTS itself, the new tools are free, open source software (FOSS), and promote the use of open data.
A Multimodal Corpus of Expert Gaze and Behavior during Phonetic Segmentation Tasks
May 11, 2018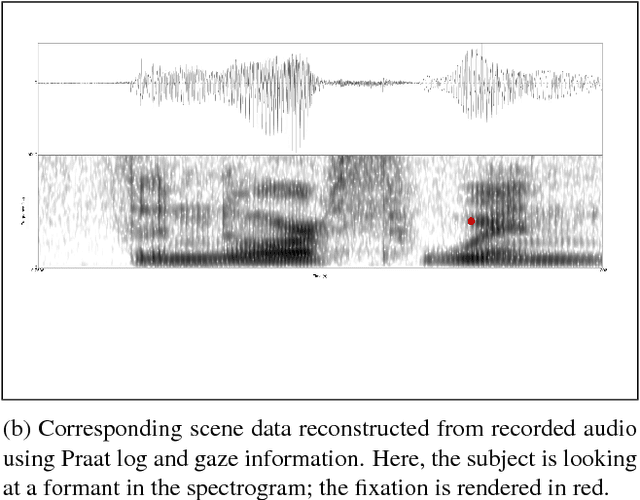

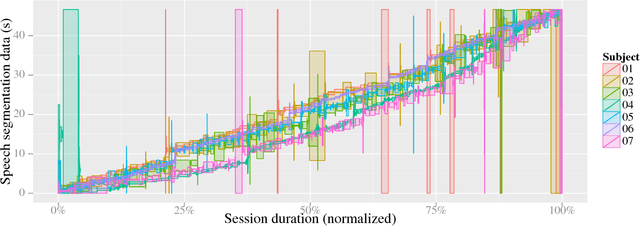
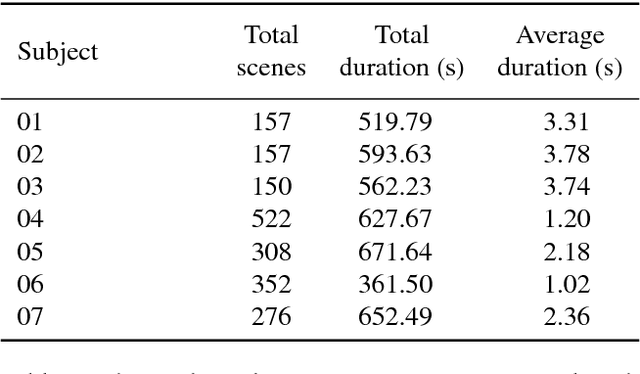
Phonetic segmentation is the process of splitting speech into distinct phonetic units. Human experts routinely perform this task manually by analyzing auditory and visual cues using analysis software, which is an extremely time-consuming process. Methods exist for automatic segmentation, but these are not always accurate enough. In order to improve automatic segmentation, we need to model it as close to the manual segmentation as possible. This corpus is an effort to capture the human segmentation behavior by recording experts performing a segmentation task. We believe that this data will enable us to highlight the important aspects of manual segmentation, which can be used in automatic segmentation to improve its accuracy.
A Multilinear Tongue Model Derived from Speech Related MRI Data of the Human Vocal Tract
Apr 17, 2018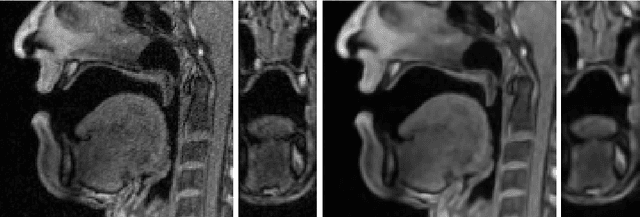
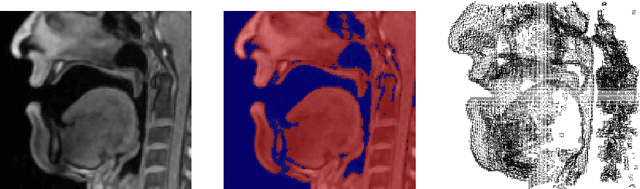
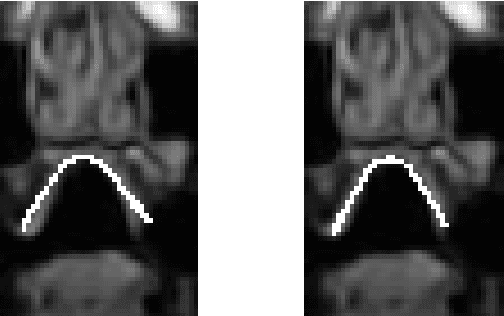
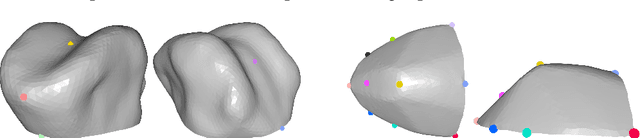
We present a multilinear statistical model of the human tongue that captures anatomical and tongue pose related shape variations separately. The model is derived from 3D magnetic resonance imaging data of 11 speakers sustaining speech related vocal tract configurations. The extraction is performed by using a minimally supervised method that uses as basis an image segmentation approach and a template fitting technique. Furthermore, it uses image denoising to deal with possibly corrupt data, palate surface information reconstruction to handle palatal tongue contacts, and a bootstrap strategy to refine the obtained shapes. Our evaluation concludes that limiting the degrees of freedom for the anatomical and speech related variations to 5 and 4, respectively, produces a model that can reliably register unknown data while avoiding overfitting effects. Furthermore, we show that it can be used to generate a plausible tongue animation by tracking sparse motion capture data.
A statistical shape space model of the palate surface trained on 3D MRI scans of the vocal tract
Sep 04, 2015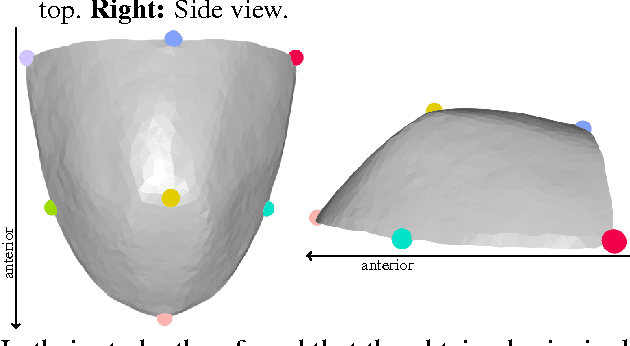
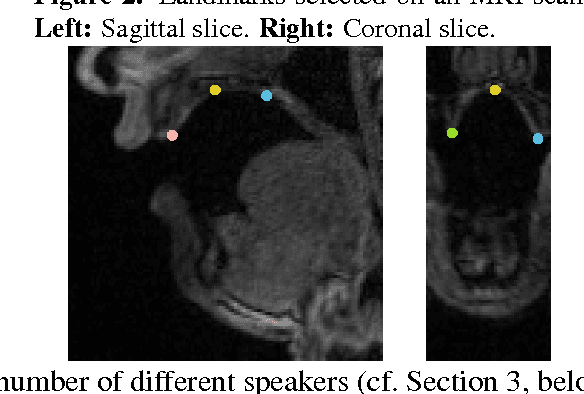
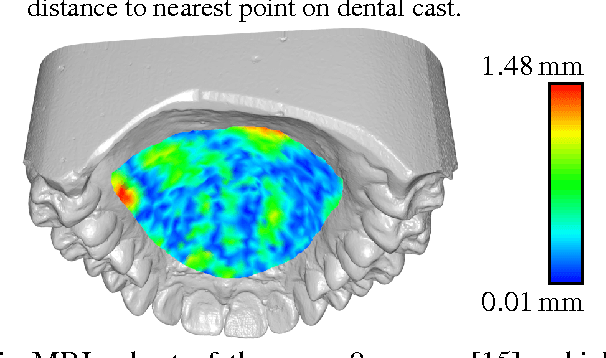
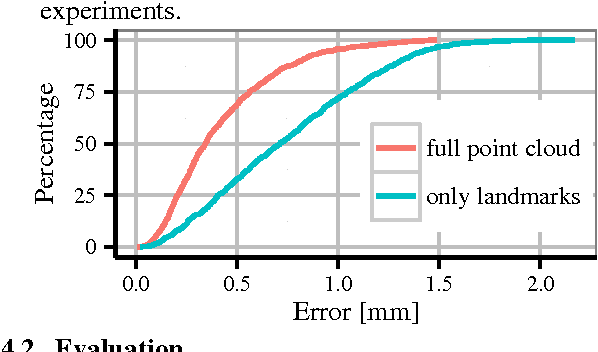
We describe a minimally-supervised method for computing a statistical shape space model of the palate surface. The model is created from a corpus of volumetric magnetic resonance imaging (MRI) scans collected from 12 speakers. We extract a 3D mesh of the palate from each speaker, then train the model using principal component analysis (PCA). The palate model is then tested using 3D MRI from another corpus and evaluated using a high-resolution optical scan. We find that the error is low even when only a handful of measured coordinates are available. In both cases, our approach yields promising results. It can be applied to extract the palate shape from MRI data, and could be useful to other analysis modalities, such as electromagnetic articulography (EMA) and ultrasound tongue imaging (UTI).
Progress in animation of an EMA-controlled tongue model for acoustic-visual speech synthesis
Jan 19, 2012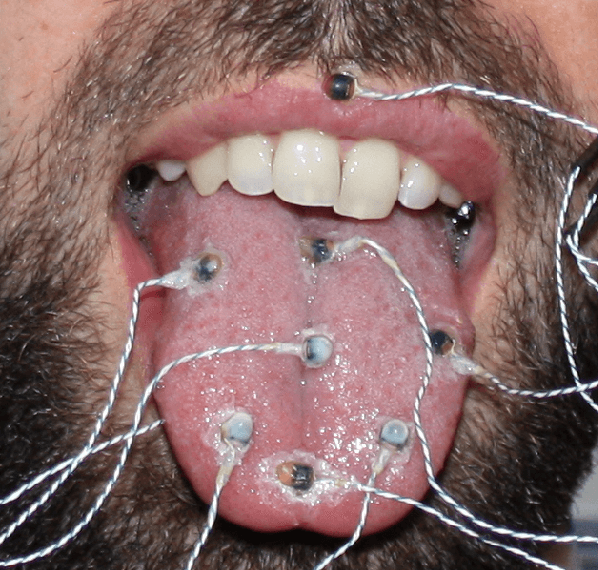
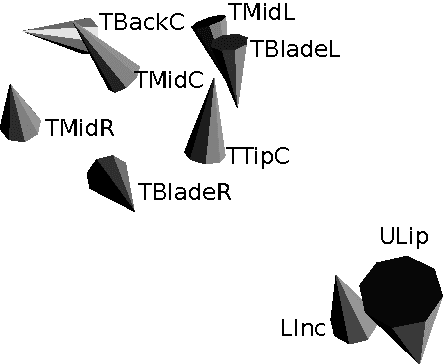

We present a technique for the animation of a 3D kinematic tongue model, one component of the talking head of an acoustic-visual (AV) speech synthesizer. The skeletal animation approach is adapted to make use of a deformable rig controlled by tongue motion capture data obtained with electromagnetic articulography (EMA), while the tongue surface is extracted from volumetric magnetic resonance imaging (MRI) data. Initial results are shown and future work outlined.