 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilinear Tongue Model Derived from Speech Related MRI Data of the Human Vocal Tract
Paper and Code
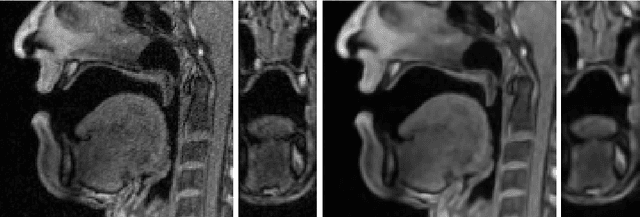
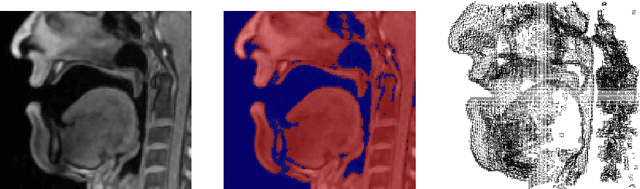
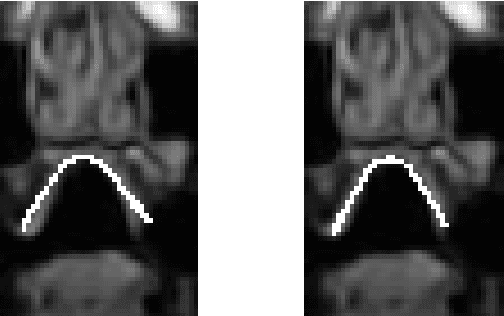
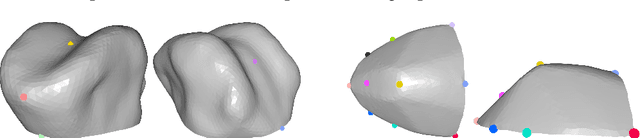
We present a multilinear statistical model of the human tongue that captures anatomical and tongue pose related shape variations separately. The model is derived from 3D magnetic resonance imaging data of 11 speakers sustaining speech related vocal tract configurations. The extraction is performed by using a minimally supervised method that uses as basis an image segmentation approach and a template fitting technique. Furthermore, it uses image denoising to deal with possibly corrupt data, palate surface information reconstruction to handle palatal tongue contacts, and a bootstrap strategy to refine the obtained shapes. Our evaluation concludes that limiting the degrees of freedom for the anatomical and speech related variations to 5 and 4, respectively, produces a model that can reliably register unknown data while avoiding overfitting effects. Furthermore, we show that it can be used to generate a plausible tongue animation by tracking sparse motion capture data.