 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Navigation in Environments with Traversable Obstacles Using Large Language and Vision-Language Models
Oct 13, 2023This paper proposes an interactive navigation framework by using large language and vision-language models, allowing robots to navigate in environments with traversable obstacles. We utilize the large language model (GPT-3.5) and the open-set Vision-language Model (Grounding DINO) to create an action-aware costmap to perform effective path planning without fine-tuning. With the large models, we can achieve an end-to-end system from textual instructions like "Can you pass through the curtains to deliver medicines to me?", to bounding boxes (e.g., curtains) with action-aware attributes. They can be used to segment LiDAR point clouds into two parts: traversable and untraversable parts, and then an action-aware costmap is constructed for generating a feasible path. The pre-trained large models have great generalization ability and do not require additional annotated data for training, allowing fast deployment in the interactive navigation tasks. We choose to use multiple traversable objects such as curtains and grasses for verification by instructing the robot to traverse them. Besides, traversing curtains in a medical scenario was tested. All experimental results demonstrated the proposed framework's effectiveness and adaptability to diverse environments.
FashionTex: Controllable Virtual Try-on with Text and Texture
May 08, 2023



Virtual try-on attracts increasing research attention as a promising way for enhancing the user experience for online cloth shopping. Though existing methods can generate impressive results, users need to provide a well-designed reference image containing the target fashion clothes that often do not exist. To support user-friendly fashion customization in full-body portraits, we propose a multi-modal interactive setting by combining the advantages of both text and texture for multi-level fashion manipulation. With the carefully designed fashion editing module and loss functions, FashionTex framework can semantically control cloth types and local texture patterns without annotated pairwise training data. We further introduce an ID recovery module to maintain the identity of input portrait. Extensive experiments have demonstrated the effectiveness of our proposed pipeline.
Refer-it-in-RGBD: A Bottom-up Approach for 3D Visual Grounding in RGBD Images
Mar 17, 2021

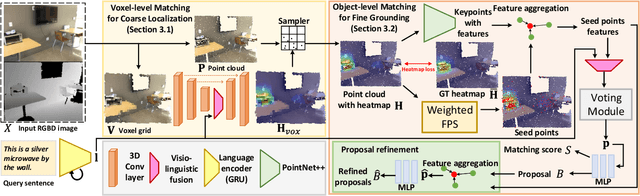
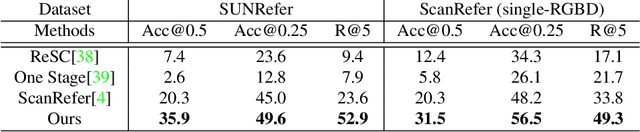
Grounding referring expressions in RGBD image has been an emerging field. We present a novel task of 3D visual grounding in single-view RGBD image where the referred objects are often only partially scanned due to occlusion. In contrast to previous works that directly generate object proposals for grounding in the 3D scenes, we propose a bottom-up approach to gradually aggregate context-aware information, effectively addressing the challenge posed by the partial geometry. Our approach first fuses the language and the visual features at the bottom level to generate a heatmap that coarsely localizes the relevant regions in the RGBD image. Then our approach conducts an adaptive feature learning based on the heatmap and performs the object-level matching with another visio-linguistic fusion to finally ground the referred object. We evaluate the proposed method by comparing to the state-of-the-art methods on both the RGBD images extracted from the ScanRefer dataset and our newly collected SUNRefer dataset. Experiments show that our method outperforms the previous methods by a large margin (by 11.2% and 15.6% Acc@0.5) on both datasets.