 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocoNeRF: A NeRF-based Approach for Local Structure from Motion for Precise Localization
Oct 08, 2023Visual localization is a critical task in mobile robotics, and researchers are continuously developing new approaches to enhance its efficiency. In this article, we propose a novel approach to improve the accuracy of visual localization using Structure from Motion (SfM) techniques. We highlight the limitations of global SfM, which suffers from high latency, and the challenges of local SfM, which requires large image databases for accurate reconstruction. To address these issues, we propose utilizing Neural Radiance Fields (NeRF), as opposed to image databases, to cut down on the space required for storage. We suggest that sampling reference images around the prior query position can lead to further improvements. We evaluate the accuracy of our proposed method against ground truth obtained using LIDAR and Advanced Lidar Odometry and Mapping in Real-time (A-LOAM), and compare its storage usage against local SfM with COLMAP in the conducted experiments. Our proposed method achieves an accuracy of 0.068 meters compared to the ground truth, which is slightly lower than the most advanced method COLMAP, which has an accuracy of 0.022 meters. However, the size of the database required for COLMAP is 400 megabytes, whereas the size of our NeRF model is only 160 megabytes. Finally, we perform an ablation study to assess the impact of using reference images from the NeRF reconstruction.
Hierarchical Visual Localization Based on Sparse Feature Pyramid for Adaptive Reduction of Keypoint Map Size
May 08, 2023
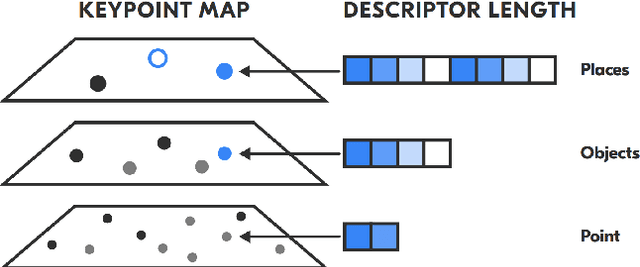
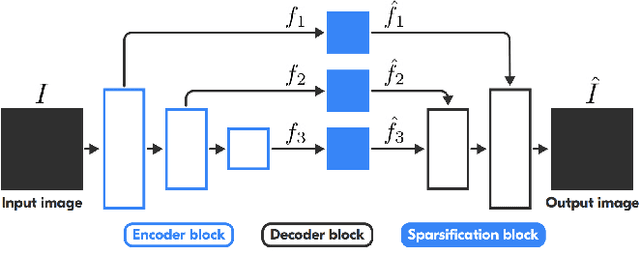
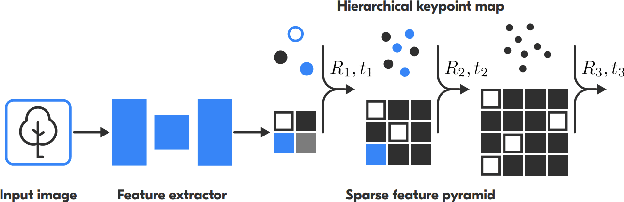
Visual localization is a fundamental task for a wide range of applications in the field of robotics. Yet, it is still a complex problem with no universal solution, and the existing approaches are difficult to scale: most state-of-the-art solutions are unable to provide accurate localization without a significant amount of storage space. We propose a hierarchical, low-memory approach to localization based on keypoints with different descriptor lengths. It becomes possible with the use of the developed unsupervised neural network, which predicts a feature pyramid with different descriptor lengths for images. This structure allows applying coarse-to-fine paradigms for localization based on keypoint map, and varying the accuracy of localization by changing the type of the descriptors used in the pipeline. Our approach achieves comparable results in localization accuracy and a significant reduction in memory consumption (up to 16 times) among state-of-the-art methods.
MeSLAM: Memory Efficient SLAM based on Neural Fields
Sep 19, 2022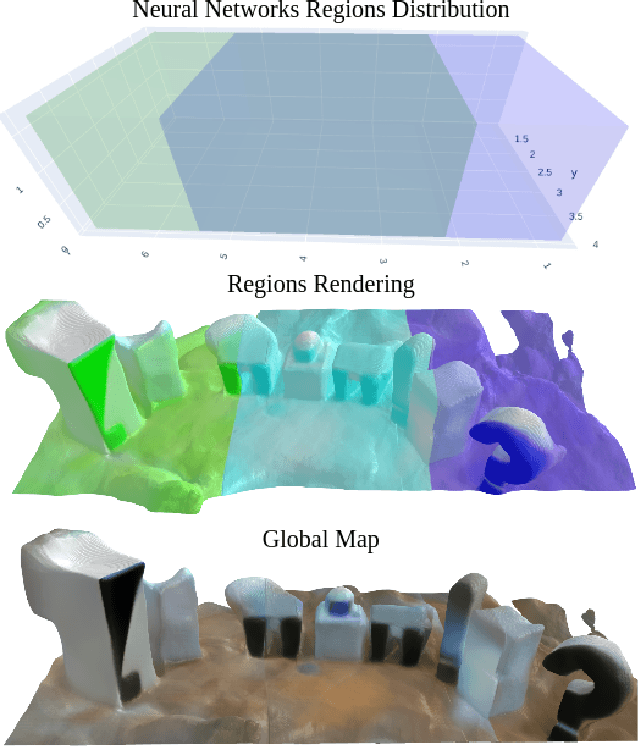
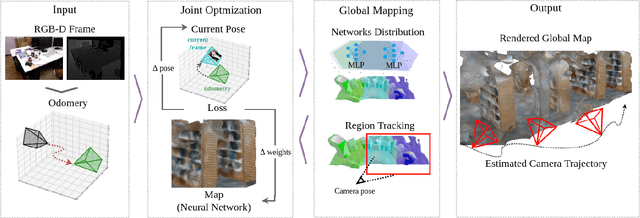

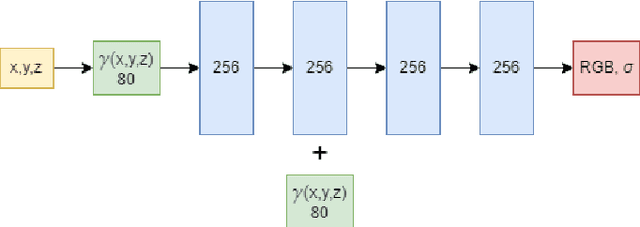
Existing Simultaneous Localization and Mapping (SLAM) approaches are limited in their scalability due to growing map size in long-term robot operation. Moreover, processing such maps for localization and planning tasks leads to the increased computational resources required onboard. To address the problem of memory consumption in long-term operation, we develop a novel real-time SLAM algorithm, MeSLAM, that is based on neural field implicit map representation. It combines the proposed global mapping strategy, including neural networks distribution and region tracking, with an external odometry system. As a result, the algorithm is able to efficiently train multiple networks representing different map regions and track poses accurately in large-scale environments. Experimental results show that the accuracy of the proposed approach is comparable to the state-of-the-art methods (on average, 6.6 cm on TUM RGB-D sequences) and outperforms the baseline, iMAP$^*$. Moreover, the proposed SLAM approach provides the most compact-sized maps without details distortion (1.9 MB to store 57 m$^3$) among the state-of-the-art SLAM approaches.
MuCaSLAM: CNN-Based Frame Quality Assessment for Mobile Robot with Omnidirectional Visual SLAM
Sep 05, 2022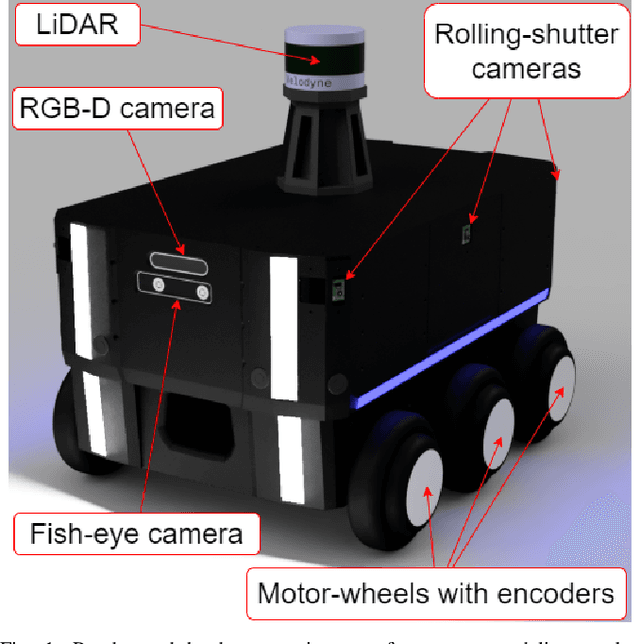
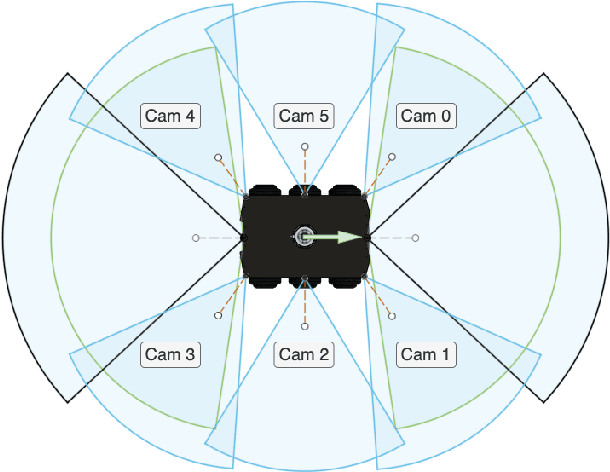
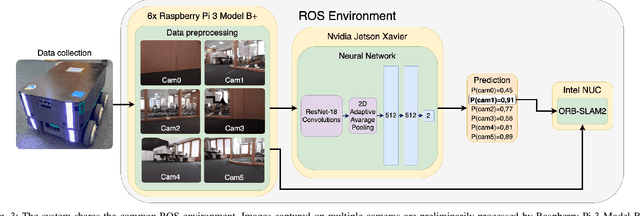
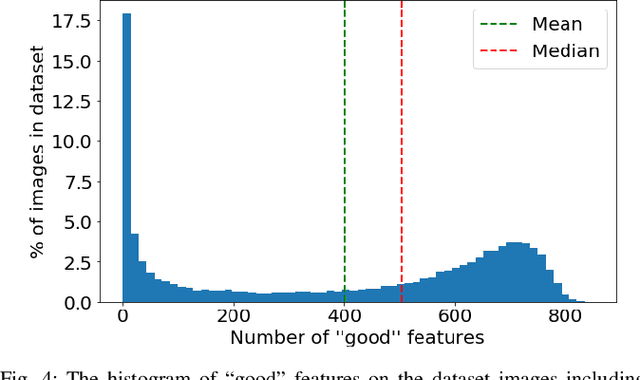
In the proposed study, we describe an approach to improving the computational efficiency and robustness of visual SLAM algorithms on mobile robots with multiple cameras and limited computational power by implementing an intermediate layer between the cameras and the SLAM pipeline. In this layer, the images are classified using a ResNet18-based neural network regarding their applicability to the robot localization. The network is trained on a six-camera dataset collected in the campus of the Skolkovo Institute of Science and Technology (Skoltech). For training, we use the images and ORB features that were successfully matched with subsequent frame of the same camera ("good" keypoints or features). The results have shown that the network is able to accurately determine the optimal images for ORB-SLAM2, and implementing the proposed approach in the SLAM pipeline can help significantly increase the number of images the SLAM algorithm can localize on, and improve the overall robustness of visual SLAM. The experiments on operation time state that the proposed approach is at least 6 times faster compared to using ORB extractor and feature matcher when operated on CPU, and more than 30 times faster when run on GPU. The network evaluation has shown at least 90% accuracy in recognizing images with a big number of "good" ORB keypoints. The use of the proposed approach allowed to maintain a high number of features throughout the dataset by robustly switching from cameras with feature-poor streams.
CloudVision: DNN-based Visual Localization of Autonomous Robots using Prebuilt LiDAR Point Cloud
Sep 04, 2022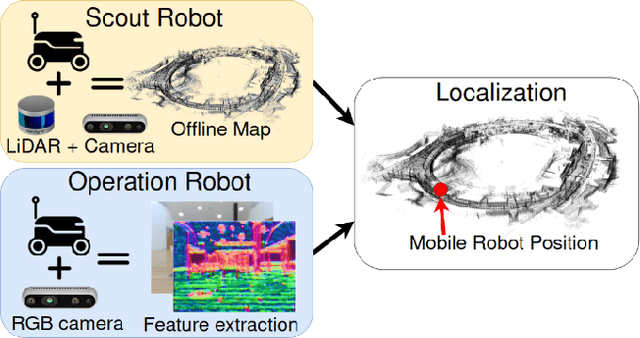
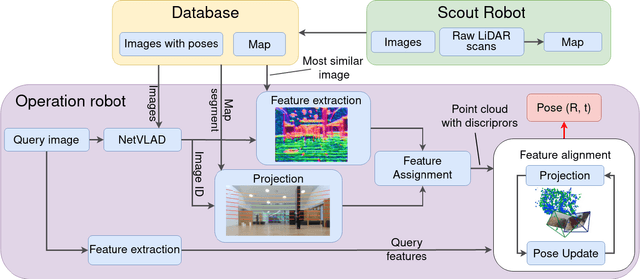
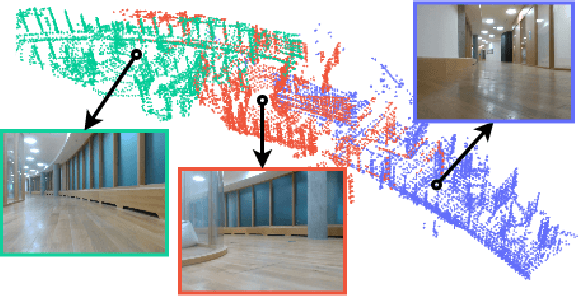

In this study, we propose a novel visual localization approach to accurately estimate six degrees of freedom (6-DoF) poses of the robot within the 3D LiDAR map based on visual data from an RGB camera. The 3D map is obtained utilizing an advanced LiDAR-based simultaneous localization and mapping (SLAM) algorithm capable of collecting a precise sparse map. The features extracted from the camera images are compared with the points of the 3D map, and then the geometric optimization problem is being solved to achieve precise visual localization. Our approach allows employing a scout robot equipped with an expensive LiDAR only once - for mapping of the environment, and multiple operational robots with only RGB cameras onboard - for performing mission tasks, with the localization accuracy higher than common camera-based solutions. The proposed method was tested on the custom dataset collected in the Skolkovo Institute of Science and Technology (Skoltech). During the process of assessing the localization accuracy, we managed to achieve centimeter-level accuracy; the median translation error was as low as 1.3 cm. The precise positioning achieved with only cameras makes possible the usage of autonomous mobile robots to solve the most complex tasks that require high localization accuracy.
DarkSLAM: GAN-assisted Visual SLAM for Reliable Operation in Low-light Conditions
Jun 05, 2022
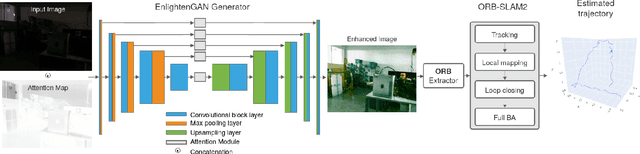


Existing visual SLAM approaches are sensitive to illumination, with their precision drastically falling in dark conditions due to feature extractor limitations. The algorithms currently used to overcome this issue are not able to provide reliable results due to poor performance and noisiness, and the localization quality in dark conditions is still insufficient for practical use. In this paper, we present a novel SLAM method capable of working in low light using Generative Adversarial Network (GAN) preprocessing module to enhance the light conditions on input images, thus improving the localization robustness. The proposed algorithm was evaluated on a custom indoor dataset consisting of 14 sequences with varying illumination levels and ground truth data collected using a motion capture system. According to the experimental results, the reliability of the proposed approach remains high even in extremely low light conditions, providing 25.1% tracking time on darkest sequences, whereas existing approaches achieve tracking only 0.6% of the sequence time.