 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCaSLAM: CNN-Based Frame Quality Assessment for Mobile Robot with Omnidirectional Visual SLAM
Sep 05, 2022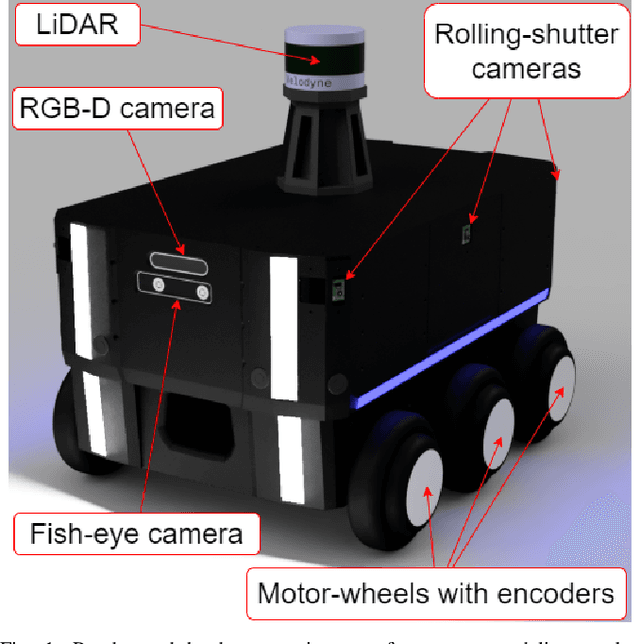
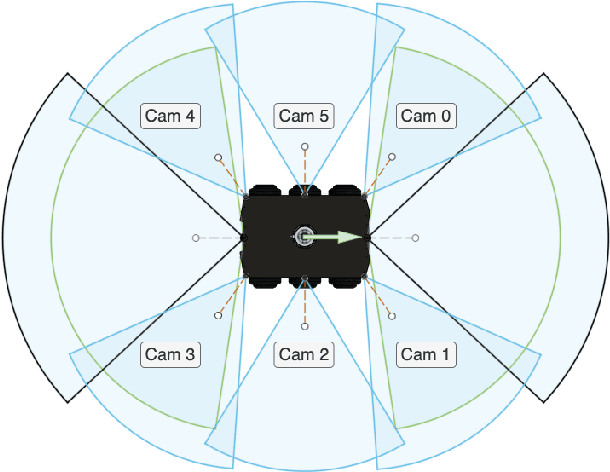
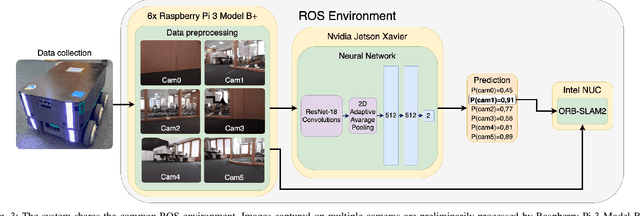
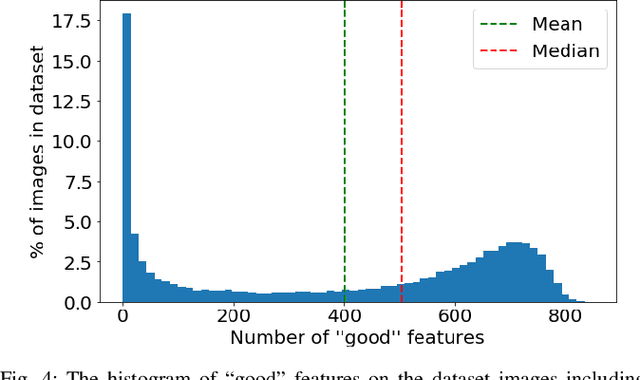
In the proposed study, we describe an approach to improving the computational efficiency and robustness of visual SLAM algorithms on mobile robots with multiple cameras and limited computational power by implementing an intermediate layer between the cameras and the SLAM pipeline. In this layer, the images are classified using a ResNet18-based neural network regarding their applicability to the robot localization. The network is trained on a six-camera dataset collected in the campus of the Skolkovo Institute of Science and Technology (Skoltech). For training, we use the images and ORB features that were successfully matched with subsequent frame of the same camera ("good" keypoints or features). The results have shown that the network is able to accurately determine the optimal images for ORB-SLAM2, and implementing the proposed approach in the SLAM pipeline can help significantly increase the number of images the SLAM algorithm can localize on, and improve the overall robustness of visual SLAM. The experiments on operation time state that the proposed approach is at least 6 times faster compared to using ORB extractor and feature matcher when operated on CPU, and more than 30 times faster when run on GPU. The network evaluation has shown at least 90% accuracy in recognizing images with a big number of "good" ORB keypoints. The use of the proposed approach allowed to maintain a high number of features throughout the dataset by robustly switching from cameras with feature-poor streams.