 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Research Roadmap for Augmenting Software Engineering Processes and Software Products with Generative AI
Oct 30, 2025Generative AI (GenAI) is rapidly transforming software engineering (SE) practices, influencing how SE processes are executed, as well as how software systems are developed, operated, and evolved. This paper applies design science research to build a roadmap for GenAI-augmented SE. The process consists of three cycles that incrementally integrate multiple sources of evidence, including collaborative discussions from the FSE 2025 "Software Engineering 2030" workshop, rapid literature reviews, and external feedback sessions involving peers. McLuhan's tetrads were used as a conceptual instrument to systematically capture the transforming effects of GenAI on SE processes and software products.The resulting roadmap identifies four fundamental forms of GenAI augmentation in SE and systematically characterizes their related research challenges and opportunities. These insights are then consolidated into a set of future research directions. By grounding the roadmap in a rigorous multi-cycle process and cross-validating it among independent author teams and peers, the study provides a transparent and reproducible foundation for analyzing how GenAI affects SE processes, methods and tools, and for framing future research within this rapidly evolving area. Based on these findings, the article finally makes ten predictions for SE in the year 2030.
On the Forces of Driver Distraction: Explainable Predictions for the Visual Demand of In-Vehicle Touchscreen Interactions
Jan 05, 2023



With modern infotainment systems, drivers are increasingly tempted to engage in secondary tasks while driving. Since distracted driving is already one of the main causes of fatal accidents, in-vehicle touchscreen Human-Machine Interfaces (HMIs) must be as little distracting as possible. To ensure that these systems are safe to use, they undergo elaborate and expensive empirical testing, requiring fully functional prototypes. Thus, early-stage methods informing designers about the implication their design may have on driver distraction are of great value. This paper presents a machine learning method that, based on anticipated usage scenarios, predicts the visual demand of in-vehicle touchscreen interactions and provides local and global explanations of the factors influencing drivers' visual attention allocation. The approach is based on large-scale natural driving data continuously collected from production line vehicles and employs the SHapley Additive exPlanation (SHAP) method to provide explanations leveraging informed design decisions. Our approach is more accurate than related work and identifies interactions during which long glances occur with 68 % accuracy and predicts the total glance duration with a mean error of 2.4 s. Our explanations replicate the results of various recent studies and provide fast and easily accessible insights into the effect of UI elements, driving automation, and vehicle speed on driver distraction. The system can not only help designers to evaluate current designs but also help them to better anticipate and understand the implications their design decisions might have on future designs.
Transfer Learning for Mining Feature Requests and Bug Reports from Tweets and App Store Reviews
Aug 02, 2021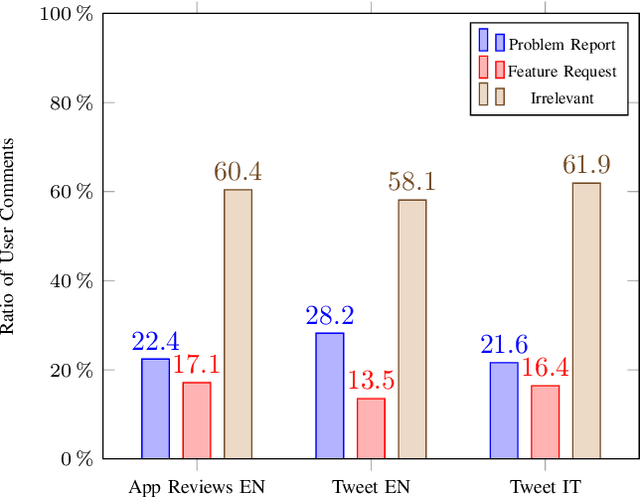
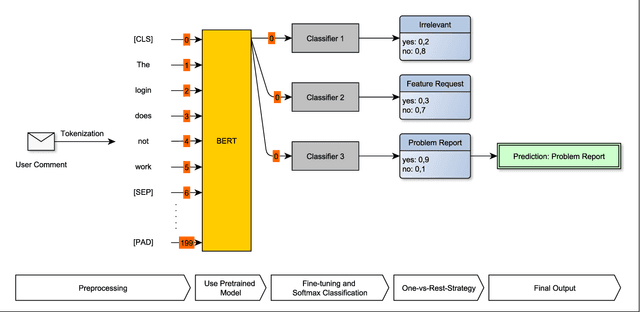
Identifying feature requests and bug reports in user comments holds great potential for development teams. However, automated mining of RE-related information from social media and app stores is challenging since (1) about 70% of user comments contain noisy, irrelevant information, (2) the amount of user comments grows daily making manual analysis unfeasible, and (3) user comments are written in different languages. Existing approaches build on traditional machine learning (ML) and deep learning (DL), but fail to detect feature requests and bug reports with high Recall and acceptable Precision which is necessary for this task. In this paper, we investigate the potential of transfer learning (TL) for the classification of user comments. Specifically, we train both monolingual and multilingual BERT models and compare the performance with state-of-the-art methods. We found that monolingual BERT models outperform existing baseline methods in the classification of English App Reviews as well as English and Italian Tweets. However, we also observed that the application of heavyweight TL models does not necessarily lead to better performance. In fact, our multilingual BERT models perform worse than traditional ML methods.
Fine-Grained Causality Extraction From Natural Language Requirements Using Recursive Neural Tensor Networks
Jul 22, 2021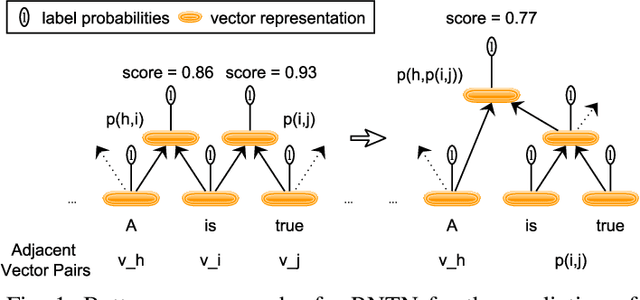
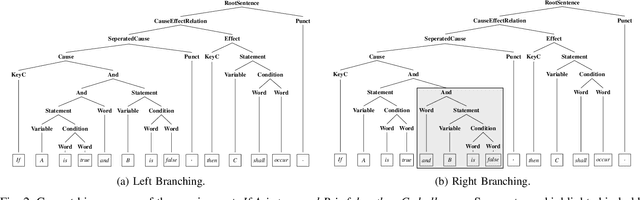

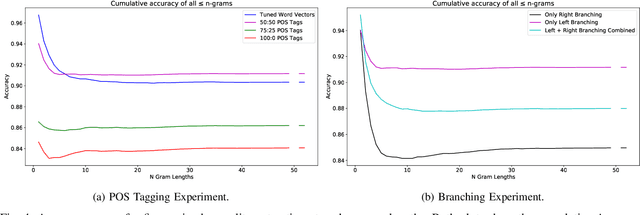
[Context:] Causal relations (e.g., If A, then B) are prevalent in functional requirements. For various applications of AI4RE, e.g., the automatic derivation of suitable test cases from requirements, automatically extracting such causal statements are a basic necessity. [Problem:] We lack an approach that is able to extract causal relations from natural language requirements in fine-grained form. Specifically, existing approaches do not consider the combinatorics between causes and effects. They also do not allow to split causes and effects into more granular text fragments (e.g., variable and condition), making the extracted relations unsuitable for automatic test case derivation. [Objective & Contributions:] We address this research gap and make the following contributions: First, we present the Causality Treebank, which is the first corpus of fully labeled binary parse trees representing the composition of 1,571 causal requirements. Second, we propose a fine-grained causality extractor based on Recursive Neural Tensor Networks. Our approach is capable of recovering the composition of causal statements written in natural language and achieves a F1 score of 74 % in the evaluation on the Causality Treebank. Third, we disclose our open data sets as well as our code to foster the discourse on the automatic extraction of causality in the RE community.
CATE: CAusality Tree Extractor from Natural Language Requirements
Jul 22, 2021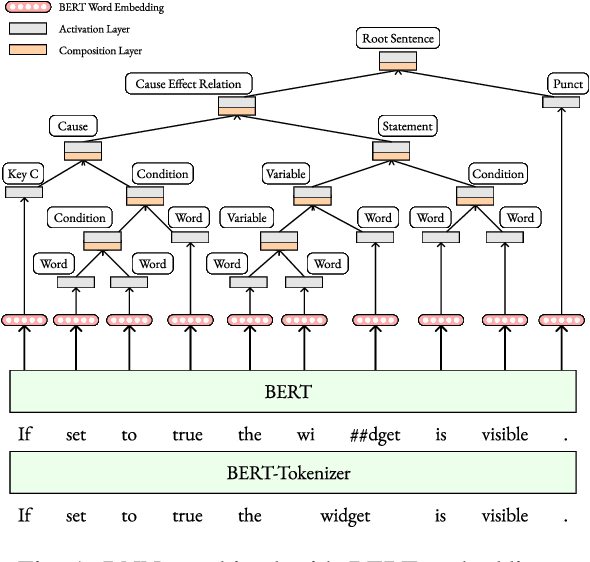
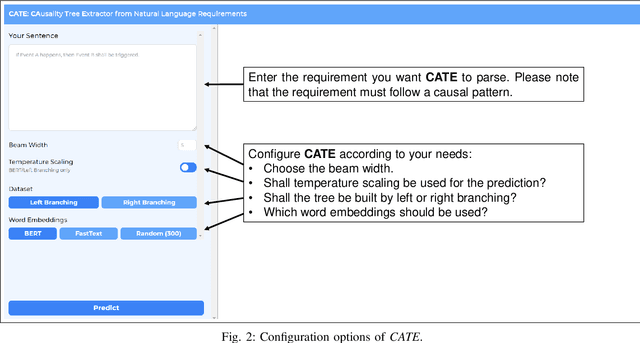
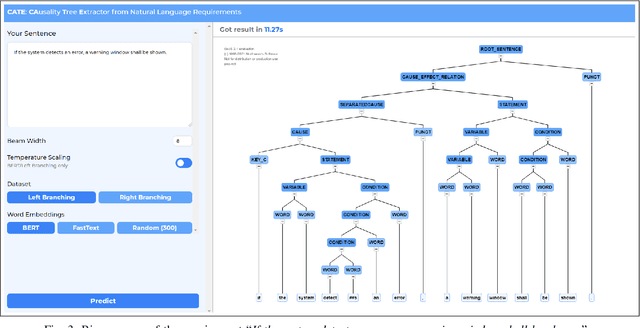
Causal relations (If A, then B) are prevalent in requirements artifacts. Automatically extracting causal relations from requirements holds great potential for various RE activities (e.g., automatic derivation of suitable test cases). However, we lack an approach capable of extracting causal relations from natural language with reasonable performance. In this paper, we present our tool CATE (CAusality Tree Extractor), which is able to parse the composition of a causal relation as a tree structure. CATE does not only provide an overview of causes and effects in a sentence, but also reveals their semantic coherence by translating the causal relation into a binary tree. We encourage fellow researchers and practitioners to use CATE at https://causalitytreeextractor.com/
Topic Modeling on User Stories using Word Mover's Distance
Jul 13, 2020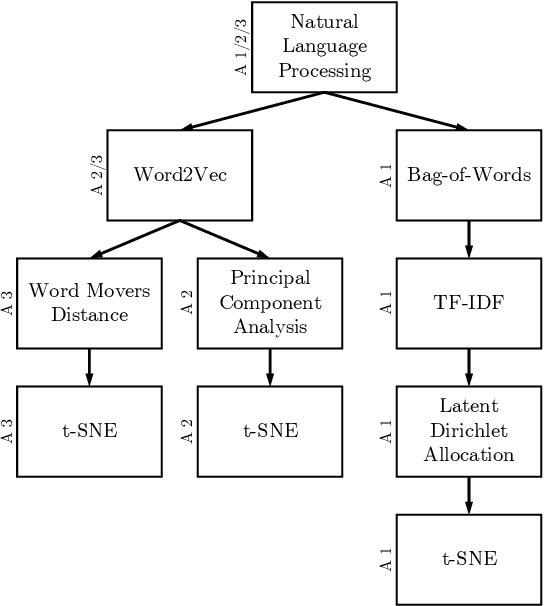
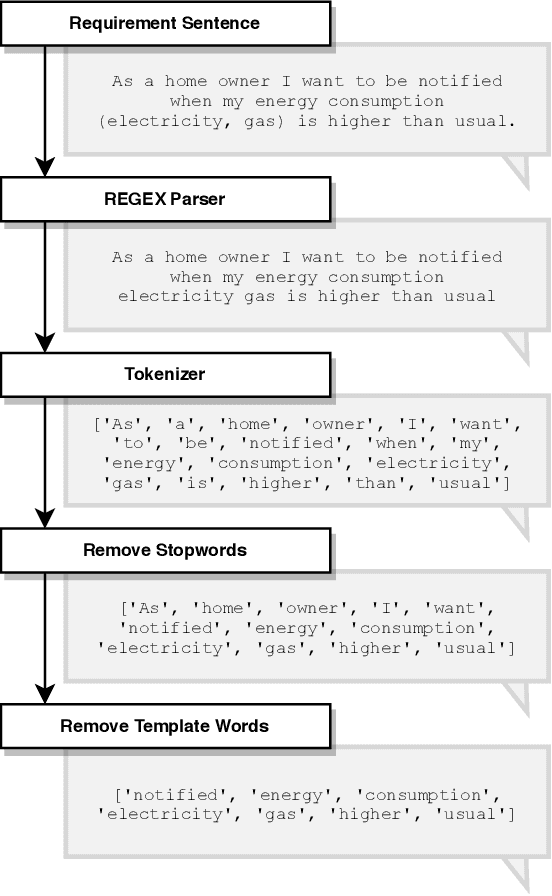

Requirements elicitation has recently been complemented with crowd-based techniques, which continuously involve large, heterogeneous groups of users who express their feedback through a variety of media. Crowd-based elicitation has great potential for engaging with (potential) users early on but also results in large sets of raw and unstructured feedback. Consolidating and analyzing this feedback is a key challenge for turning it into sensible user requirements. In this paper, we focus on topic modeling as a means to identify topics within a large set of crowd-generated user stories and compare three approaches: (1) a traditional approach based on Latent Dirichlet Allocation, (2) a combination of word embeddings and principal component analysis, and (3) a combination of word embeddings and Word Mover's Distance. We evaluate the approaches on a publicly available set of 2,966 user stories written and categorized by crowd workers. We found that a combination of word embeddings and Word Mover's Distance is most promising. Depending on the word embeddings we use in our approaches, we manage to cluster the user stories in two ways: one that is closer to the original categorization and another that allows new insights into the dataset, e.g. to find potentially new categories. Unfortunately, no measure exists to rate the quality of our results objectively. Still, our findings provide a basis for future work towards analyzing crowd-sourced user stories.
Destination Prediction Based on Partial Trajectory Data
Apr 16, 2020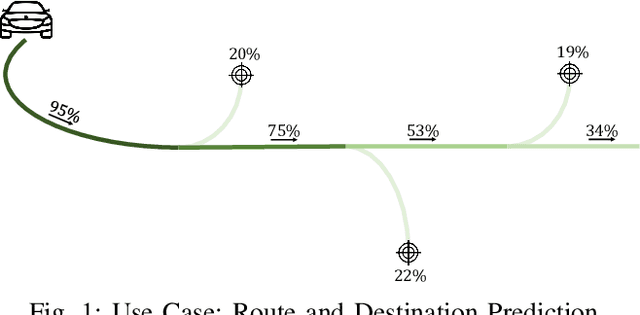
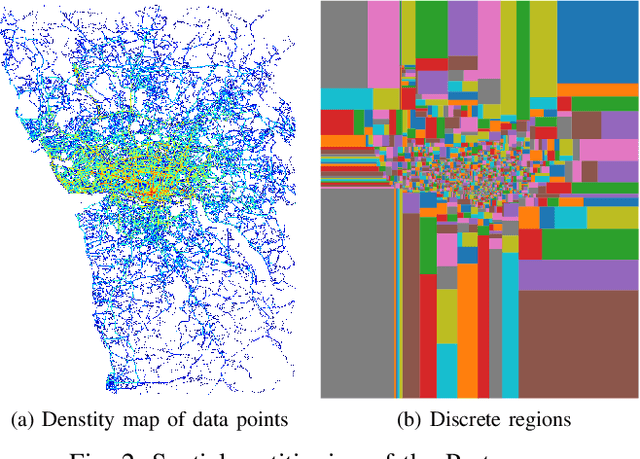
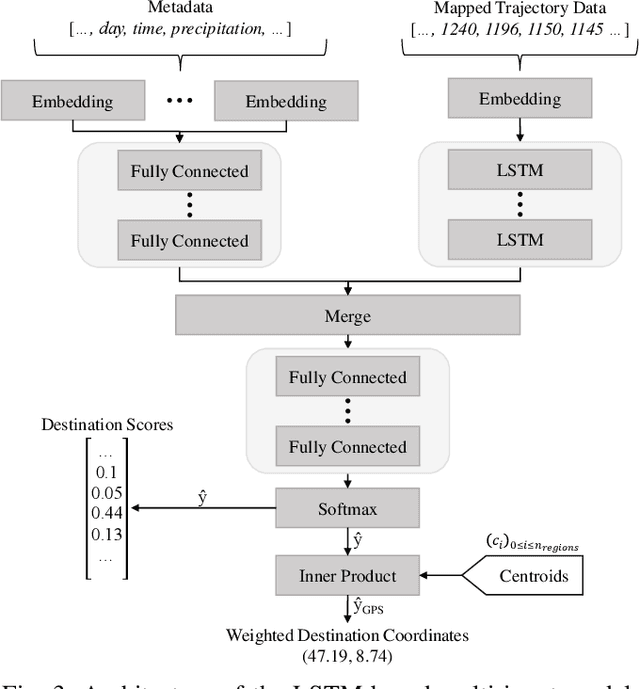
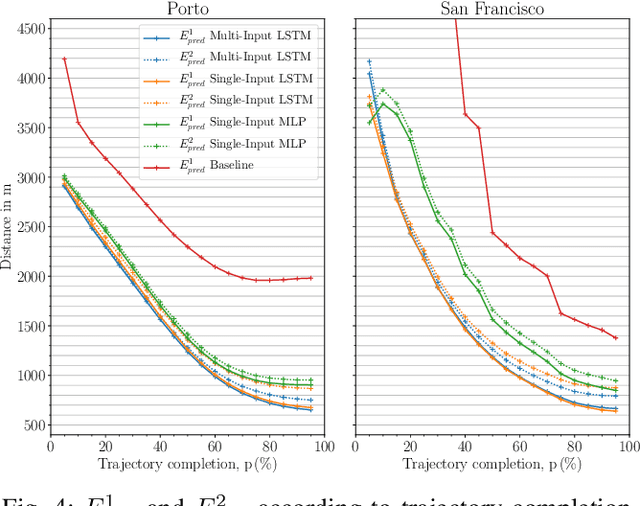
Two-thirds of the people who buy a new car prefer to use a substitute instead of the built-in navigation system. However, for many applications, knowledge about a user's intended destination and route is crucial. For example, suggestions for available parking spots close to the destination can be made or ride-sharing opportunities along the route are facilitated. Our approach predicts probable destinations and routes of a vehicle, based on the most recent partial trajectory and additional contextual data. The approach follows a three-step procedure: First, a $k$-d tree-based space discretization is performed, mapping GPS locations to discrete regions. Secondly, a recurrent neural network is trained to predict the destination based on partial sequences of trajectories. The neural network produces destination scores, signifying the probability of each region being the destination. Finally, the routes to the most probable destinations are calculated. To evaluate the method, we compare multiple neural architectures and present the experimental results of the destination prediction. The experiments are based on two public datasets of non-personalized, timestamped GPS locations of taxi trips. The best performing models were able to predict the destination of a vehicle with a mean error of 1.3 km and 1.43 km respectively.
Automated Generation of Test Models from Semi-Structured Requirements
Aug 22, 2019
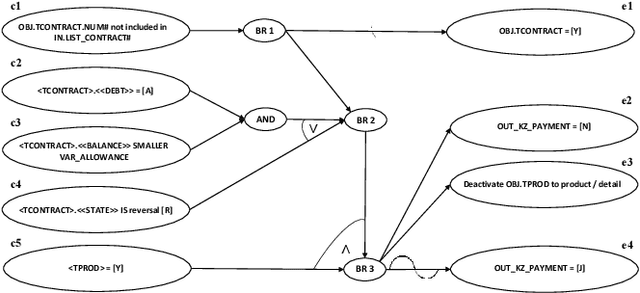
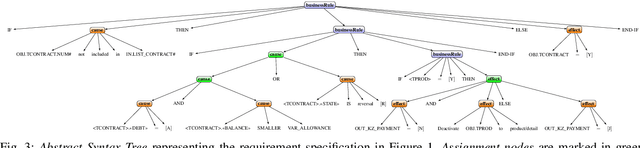
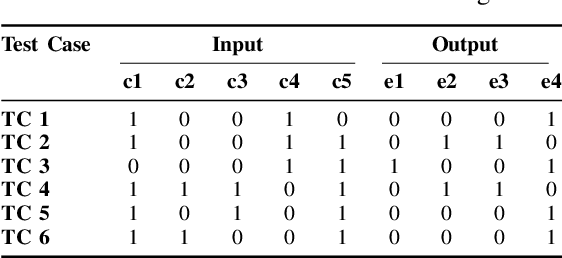
[Context:] Model-based testing is an instrument for automated generation of test cases. It requires identifying requirements in documents, understanding them syntactically and semantically, and then translating them into a test model. One light-weight language for these test models are Cause-Effect-Graphs (CEG) that can be used to derive test cases. [Problem:] The creation of test models is laborious and we lack an automated solution that covers the entire process from requirement detection to test model creation. In addition, the majority of requirements is expressed in natural language (NL), which is hard to translate to test models automatically. [Principal Idea:] We build on the fact that not all NL requirements are equally unstructured. We found that 14 % of the lines in requirements documents of our industry partner contain "pseudo-code"-like descriptions of business rules. We apply Machine Learning to identify such semi-structured requirements descriptions and propose a rule-based approach for their translation into CEGs. [Contribution:] We make three contributions: (1) an algorithm for the automatic detection of semi-structured requirements descriptions in documents, (2) an algorithm for the automatic translation of the identified requirements into a CEG and (3) a study demonstrating that our proposed solution leads to 86 % time savings for test model creation without loss of quality.
Towards Self-Explainable Cyber-Physical Systems
Aug 13, 2019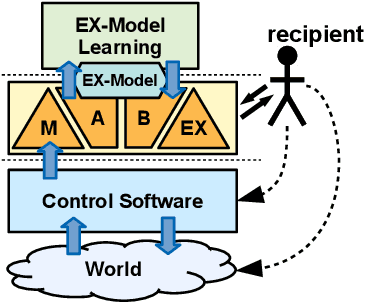
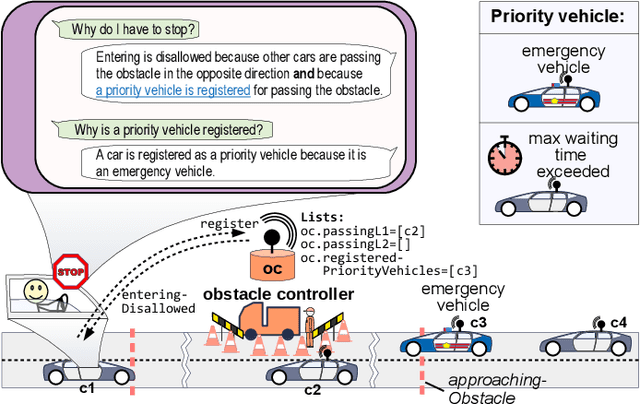
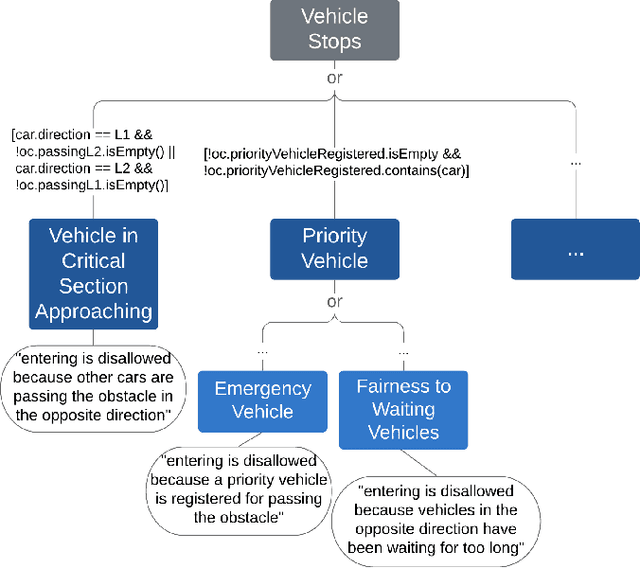
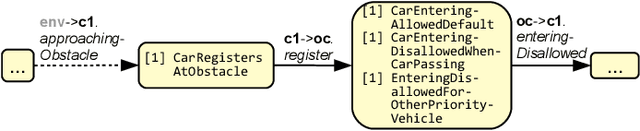
With the increasing complexity of CPSs, their behavior and decisions become increasingly difficult to understand and comprehend for users and other stakeholders. Our vision is to build self-explainable systems that can, at run-time, answer questions about the system's past, current, and future behavior. As hitherto no design methodology or reference framework exists for building such systems, we propose the MAB-EX framework for building self-explainable systems that leverage requirements- and explainability models at run-time. The basic idea of MAB-EX is to first Monitor and Analyze a certain behavior of a system, then Build an explanation from explanation models and convey this EXplanation in a suitable way to a stakeholder. We also take into account that new explanations can be learned, by updating the explanation models, should new and yet un-explainable behavior be detected by the system.
Requirements Engineering for Machine Learning: Perspectives from Data Scientists
Aug 13, 2019
Machine learning (ML) is used increasingly in real-world applications. In this paper, we describe our ongoing endeavor to define characteristics and challenges unique to Requirements Engineering (RE) for ML-based systems. As a first step, we interviewed four data scientists to understand how ML experts approach elicitation, specification, and assurance of requirements and expectations. The results show that changes in the development paradigm, i.e., from coding to training, also demands changes in RE. We conclude that development of ML systems demands requirements engineers to: (1) understand ML performance measures to state good functional requirements, (2) be aware of new quality requirements such as explainability, freedom from discrimination, or specific legal requirements, and (3) integrate ML specifics in the RE process. Our study provides a first contribution towards an RE methodology for ML systems.