 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Modeling on User Stories using Word Mover's Distance
Jul 13, 2020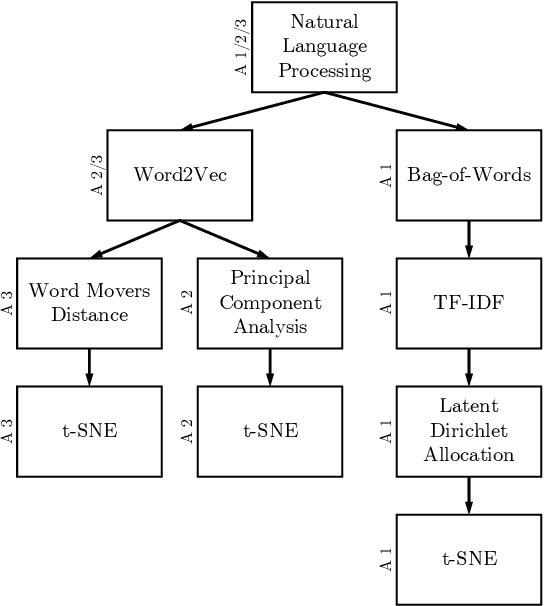
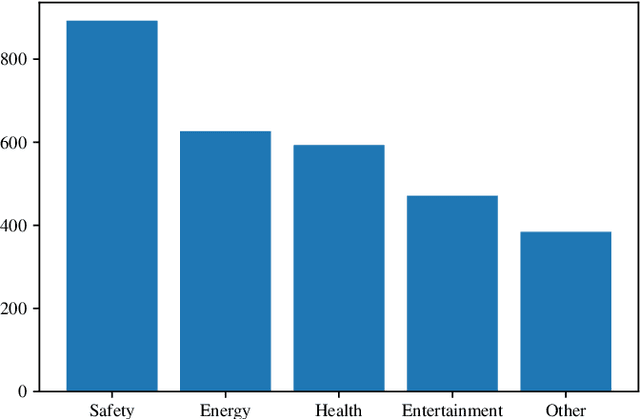
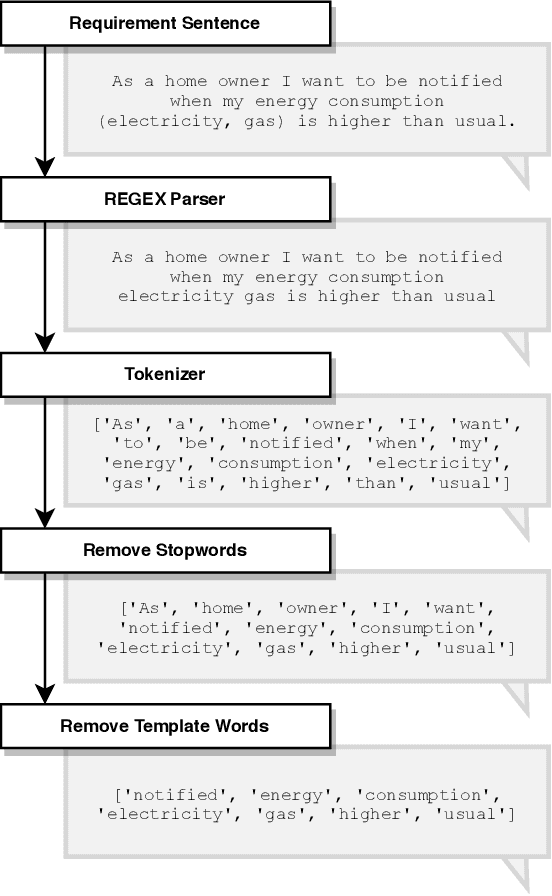

Requirements elicitation has recently been complemented with crowd-based techniques, which continuously involve large, heterogeneous groups of users who express their feedback through a variety of media. Crowd-based elicitation has great potential for engaging with (potential) users early on but also results in large sets of raw and unstructured feedback. Consolidating and analyzing this feedback is a key challenge for turning it into sensible user requirements. In this paper, we focus on topic modeling as a means to identify topics within a large set of crowd-generated user stories and compare three approaches: (1) a traditional approach based on Latent Dirichlet Allocation, (2) a combination of word embeddings and principal component analysis, and (3) a combination of word embeddings and Word Mover's Distance. We evaluate the approaches on a publicly available set of 2,966 user stories written and categorized by crowd workers. We found that a combination of word embeddings and Word Mover's Distance is most promising. Depending on the word embeddings we use in our approaches, we manage to cluster the user stories in two ways: one that is closer to the original categorization and another that allows new insights into the dataset, e.g. to find potentially new categories. Unfortunately, no measure exists to rate the quality of our results objectively. Still, our findings provide a basis for future work towards analyzing crowd-sourced user stories.