 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Mining Feature Requests and Bug Reports from Tweets and App Store Reviews
Paper and Code
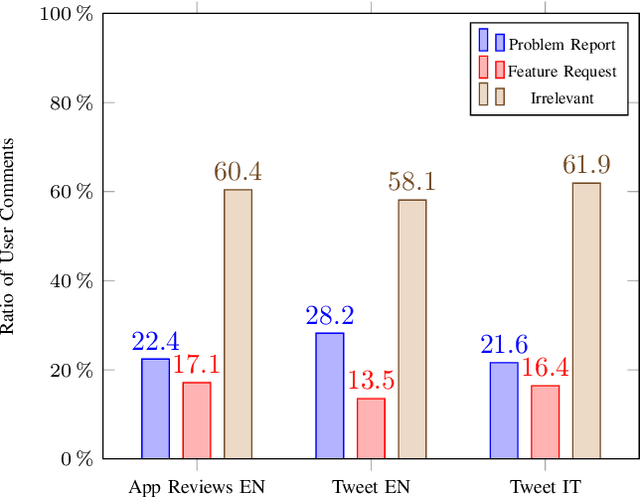
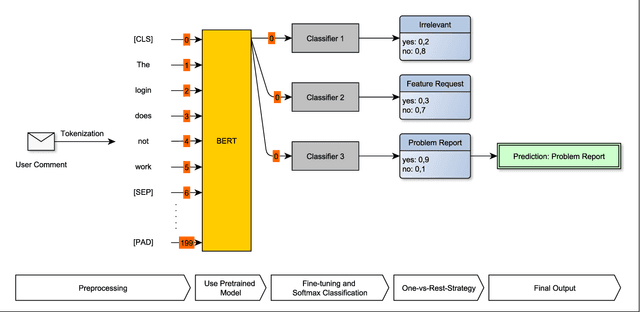
Identifying feature requests and bug reports in user comments holds great potential for development teams. However, automated mining of RE-related information from social media and app stores is challenging since (1) about 70% of user comments contain noisy, irrelevant information, (2) the amount of user comments grows daily making manual analysis unfeasible, and (3) user comments are written in different languages. Existing approaches build on traditional machine learning (ML) and deep learning (DL), but fail to detect feature requests and bug reports with high Recall and acceptable Precision which is necessary for this task. In this paper, we investigate the potential of transfer learning (TL) for the classification of user comments. Specifically, we train both monolingual and multilingual BERT models and compare the performance with state-of-the-art methods. We found that monolingual BERT models outperform existing baseline methods in the classification of English App Reviews as well as English and Italian Tweets. However, we also observed that the application of heavyweight TL models does not necessarily lead to better performance. In fact, our multilingual BERT models perform worse than traditional ML methods.