 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic ESG Assessment of Companies by Mining and Evaluating Media Coverage Data: NLP Approach and Tool
Dec 13, 2022


Context: Sustainable corporate behavior is increasingly valued by society and impacts corporate reputation and customer trust. Hence, companies regularly publish sustainability reports to shed light on their impact on environmental, social, and governance (ESG) factors. Problem: Sustainability reports are written by companies themselves and are therefore considered a company-controlled source. Contrary, studies reveal that non-corporate channels (e.g., media coverage) represent the main driver for ESG transparency. However, analysing media coverage regarding ESG factors is challenging since (1) the amount of published news articles grows daily, (2) media coverage data does not necessarily deal with an ESG-relevant topic, meaning that it must be carefully filtered, and (3) the majority of media coverage data is unstructured. Research Goal: We aim to extract ESG-relevant information from textual media reactions automatically to calculate an ESG score for a given company. Our goal is to reduce the cost of ESG data collection and make ESG information available to the general public. Contribution: Our contributions are three-fold: First, we publish a corpus of 432,411 news headlines annotated as being environmental-, governance-, social-related, or ESG-irrelevant. Second, we present our tool-supported approach called ESG-Miner capable of analyzing and evaluating headlines on corporate ESG-performance automatically. Third, we demonstrate the feasibility of our approach in an experiment and apply the ESG-Miner on 3000 manually labeled headlines. Our approach processes 96.7 % of the headlines correctly and shows a great performance in detecting environmental-related headlines along with their correct sentiment. We encourage fellow researchers and practitioners to use the ESG-Miner at https://www.esg-miner.com.
Transfer Learning for Mining Feature Requests and Bug Reports from Tweets and App Store Reviews
Aug 02, 2021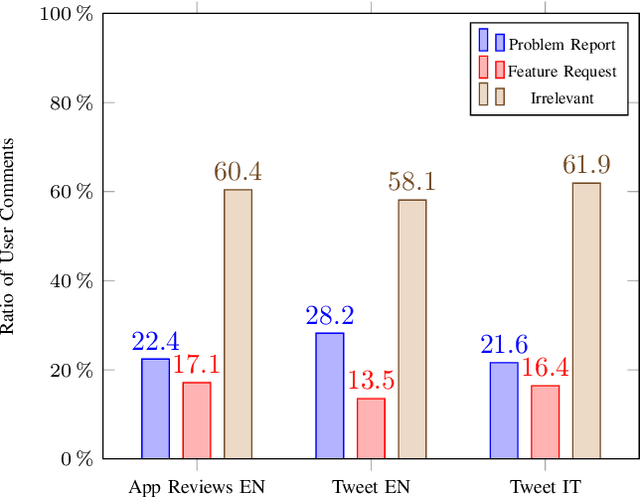
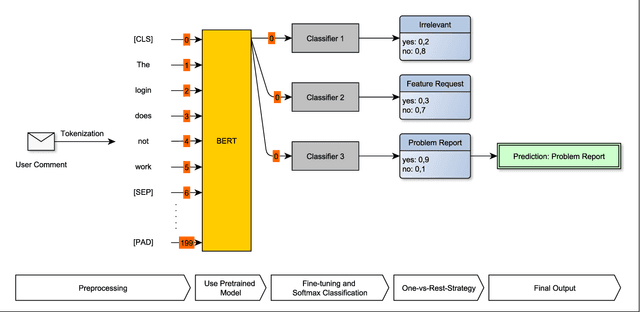
Identifying feature requests and bug reports in user comments holds great potential for development teams. However, automated mining of RE-related information from social media and app stores is challenging since (1) about 70% of user comments contain noisy, irrelevant information, (2) the amount of user comments grows daily making manual analysis unfeasible, and (3) user comments are written in different languages. Existing approaches build on traditional machine learning (ML) and deep learning (DL), but fail to detect feature requests and bug reports with high Recall and acceptable Precision which is necessary for this task. In this paper, we investigate the potential of transfer learning (TL) for the classification of user comments. Specifically, we train both monolingual and multilingual BERT models and compare the performance with state-of-the-art methods. We found that monolingual BERT models outperform existing baseline methods in the classification of English App Reviews as well as English and Italian Tweets. However, we also observed that the application of heavyweight TL models does not necessarily lead to better performance. In fact, our multilingual BERT models perform worse than traditional ML methods.
Fine-Grained Causality Extraction From Natural Language Requirements Using Recursive Neural Tensor Networks
Jul 22, 2021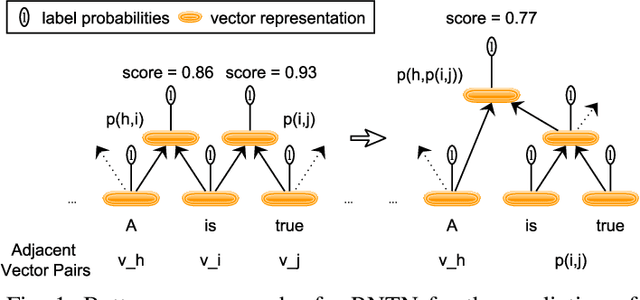
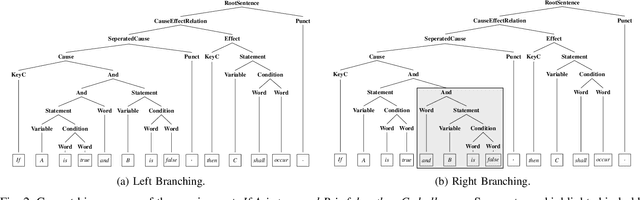

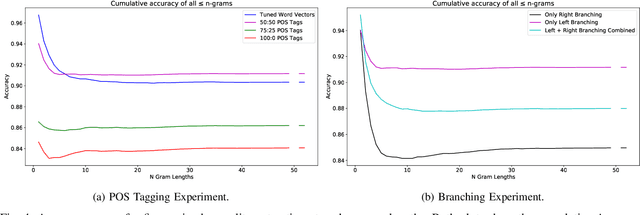
[Context:] Causal relations (e.g., If A, then B) are prevalent in functional requirements. For various applications of AI4RE, e.g., the automatic derivation of suitable test cases from requirements, automatically extracting such causal statements are a basic necessity. [Problem:] We lack an approach that is able to extract causal relations from natural language requirements in fine-grained form. Specifically, existing approaches do not consider the combinatorics between causes and effects. They also do not allow to split causes and effects into more granular text fragments (e.g., variable and condition), making the extracted relations unsuitable for automatic test case derivation. [Objective & Contributions:] We address this research gap and make the following contributions: First, we present the Causality Treebank, which is the first corpus of fully labeled binary parse trees representing the composition of 1,571 causal requirements. Second, we propose a fine-grained causality extractor based on Recursive Neural Tensor Networks. Our approach is capable of recovering the composition of causal statements written in natural language and achieves a F1 score of 74 % in the evaluation on the Causality Treebank. Third, we disclose our open data sets as well as our code to foster the discourse on the automatic extraction of causality in the RE community.
CATE: CAusality Tree Extractor from Natural Language Requirements
Jul 22, 2021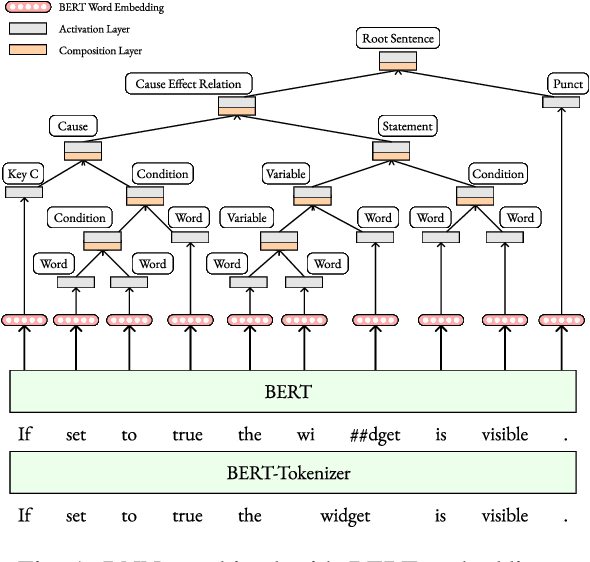
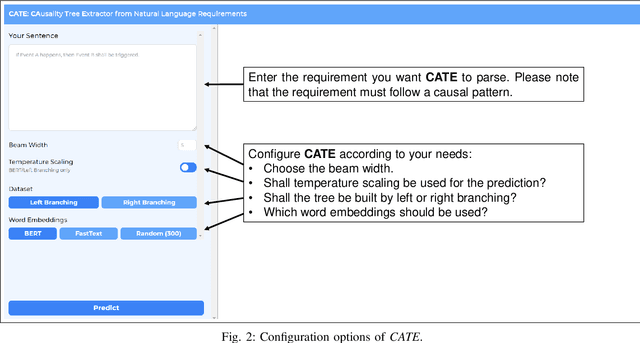
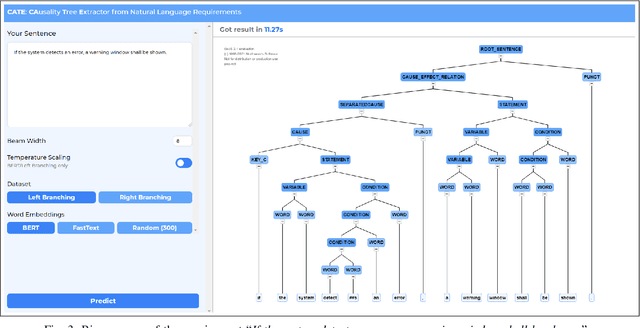
Causal relations (If A, then B) are prevalent in requirements artifacts. Automatically extracting causal relations from requirements holds great potential for various RE activities (e.g., automatic derivation of suitable test cases). However, we lack an approach capable of extracting causal relations from natural language with reasonable performance. In this paper, we present our tool CATE (CAusality Tree Extractor), which is able to parse the composition of a causal relation as a tree structure. CATE does not only provide an overview of causes and effects in a sentence, but also reveals their semantic coherence by translating the causal relation into a binary tree. We encourage fellow researchers and practitioners to use CATE at https://causalitytreeextractor.com/