 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy3D: A Simple Yet Effective Method for 3D Interactive Segmentation
Apr 15, 2025



The increasing availability of digital 3D environments, whether through image-based 3D reconstruction, generation, or scans obtained by robots, is driving innovation across various applications. These come with a significant demand for 3D interaction, such as 3D Interactive Segmentation, which is useful for tasks like object selection and manipulation. Additionally, there is a persistent need for solutions that are efficient, precise, and performing well across diverse settings, particularly in unseen environments and with unfamiliar objects. In this work, we introduce a 3D interactive segmentation method that consistently surpasses previous state-of-the-art techniques on both in-domain and out-of-domain datasets. Our simple approach integrates a voxel-based sparse encoder with a lightweight transformer-based decoder that implements implicit click fusion, achieving superior performance and maximizing efficiency. Our method demonstrates substantial improvements on benchmark datasets, including ScanNet, ScanNet++, S3DIS, and KITTI-360, and also on unseen geometric distributions such as the ones obtained by Gaussian Splatting. The project web-page is available at https://simonelli-andrea.github.io/easy3d.
AutoRF: Learning 3D Object Radiance Fields from Single View Observations
Apr 07, 2022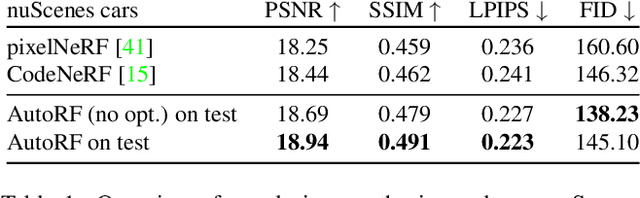
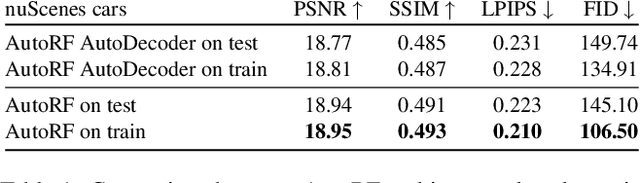
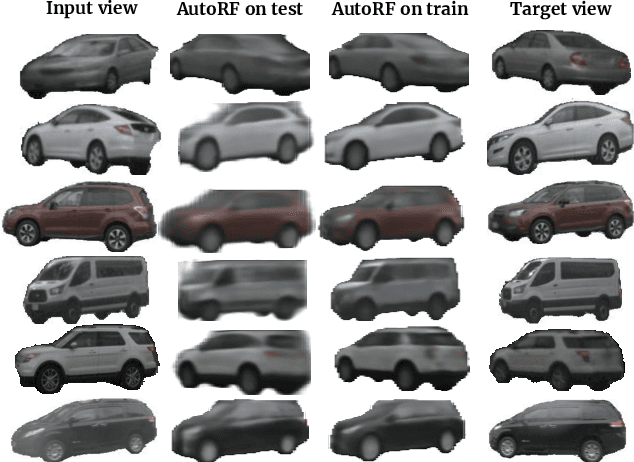
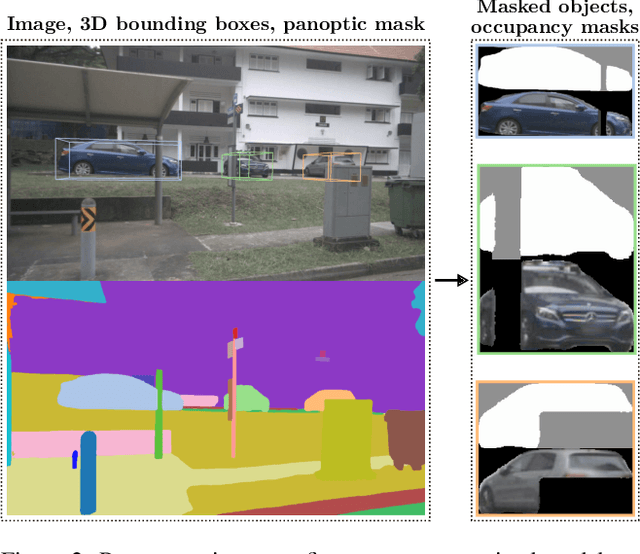
We introduce AutoRF - a new approach for learning neural 3D object representations where each object in the training set is observed by only a single view. This setting is in stark contrast to the majority of existing works that leverage multiple views of the same object, employ explicit priors during training, or require pixel-perfect annotations. To address this challenging setting, we propose to learn a normalized, object-centric representation whose embedding describes and disentangles shape, appearance, and pose. Each encoding provides well-generalizable, compact information about the object of interest, which is decoded in a single-shot into a new target view, thus enabling novel view synthesis. We further improve the reconstruction quality by optimizing shape and appearance codes at test time by fitting the representation tightly to the input image. In a series of experiments, we show that our method generalizes well to unseen objects, even across different datasets of challenging real-world street scenes such as nuScenes, KITTI, and Mapillary Metropolis.
3D Object Detection from Images for Autonomous Driving: A Survey
Feb 12, 2022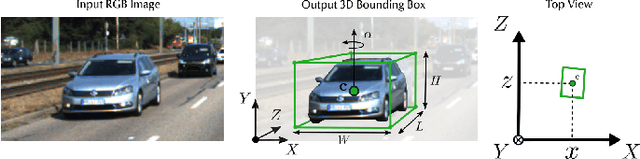
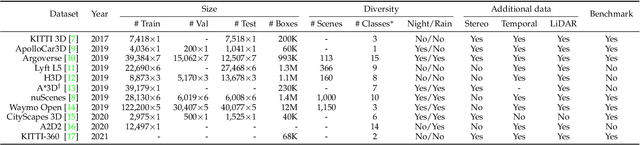
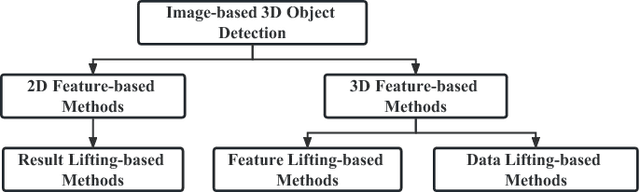
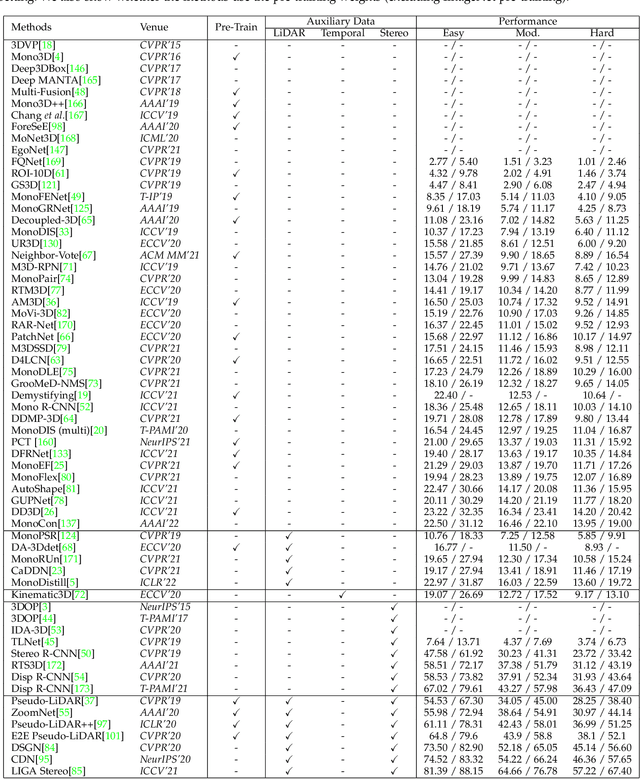
3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. Additionally, we also propose two new taxonomies to organize the state-of-the-art methods into different categories, with the intent of providing a more systematic review of existing methods and facilitating fair comparisons with future works. In retrospect of what has been achieved so far, we also analyze the current challenges in the field and discuss future directions for image-based 3D detection research.
Demystifying Pseudo-LiDAR for Monocular 3D Object Detection
Dec 10, 2020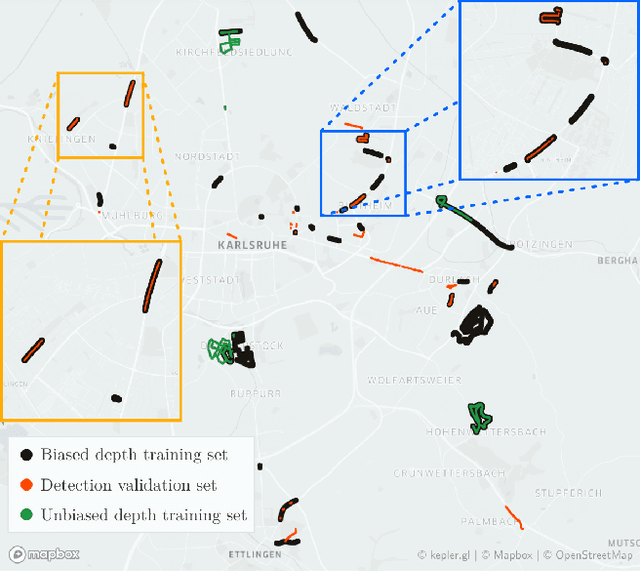
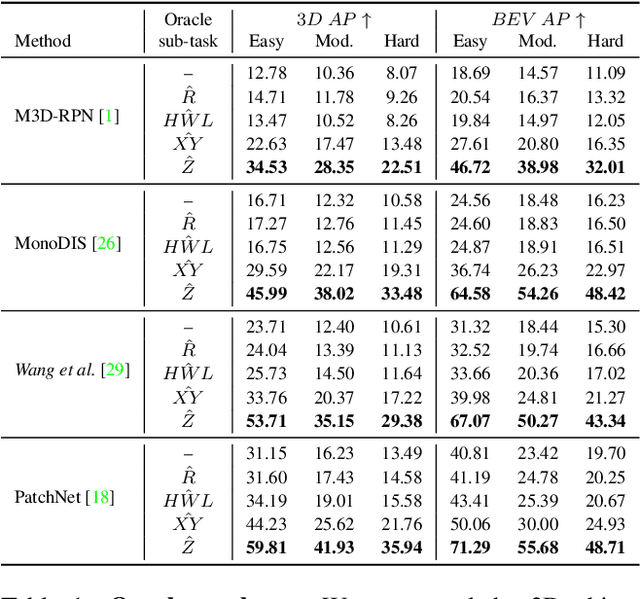


Pseudo-LiDAR-based methods for monocular 3D object detection have generated large attention in the community due to performance gains showed on the KITTI3D benchmark dataset, in particular on the commonly reported validation split. This generated a distorted impression about the superiority of Pseudo-LiDAR approaches against methods working with RGB-images only. Our first contribution consists in rectifying this view by analysing and showing experimentally that the validation results published by Pseudo-LiDAR-based methods are substantially biased. The source of the bias resides in an overlap between the KITTI3D object detection validation set and the training/validation sets used to train depth predictors feeding Pseudo-LiDAR-based methods. Surprisingly, the bias remains also after geographically removing the overlap, revealing the presence of a more structured contamination. This leaves the test set as the only reliable mean of comparison, where published Pseudo-LiDAR-based methods do not excel. Our second contribution brings Pseudo-LiDAR-based methods back up in the ranking with the introduction of a 3D confidence prediction module. Thanks to the proposed architectural changes, our modified Pseudo-LiDAR-based methods exhibit extraordinary gains on the test scores (up to +8% 3D AP).
Single-Stage Monocular 3D Object Detection with Virtual Cameras
Dec 20, 2019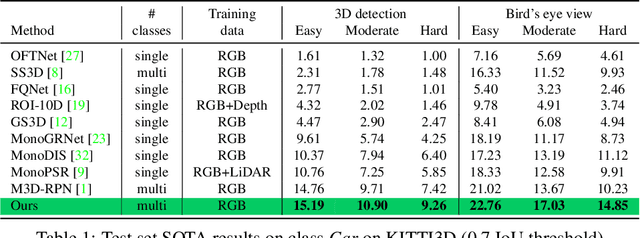
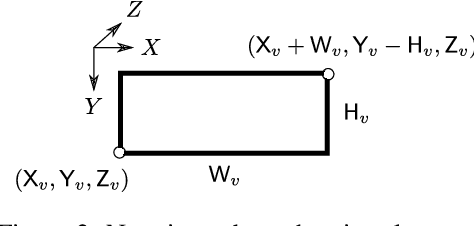

While expensive LiDAR and stereo camera rigs have enabled the development of successful 3D object detection methods, monocular RGB-only approaches still lag significantly behind. Our work advances the state of the art by introducing MoVi-3D, a novel, single-stage deep architecture for monocular 3D object detection. At its core, MoVi-3D leverages geometrical information to generate synthetic views from virtual cameras at both, training and test time, resulting in normalized object appearance with respect to distance. Our synthetically generated views facilitate the detection task as they cut down the variability in visual appearance associated to objects placed at different distances from the camera. As a consequence, the deep model is relieved from learning depth-specific representations and its complexity can be significantly reduced. In particular we show that our proposed concept of exploiting virtual cameras enables us to set new state-of-the-art results on the popular KITTI3D benchmark using just a lightweight, single-stage architecture.
Disentangling Monocular 3D Object Detection
May 29, 2019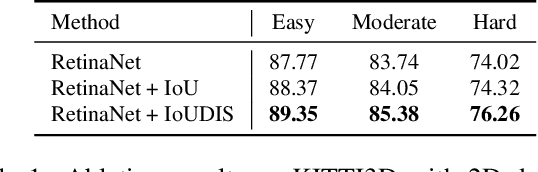
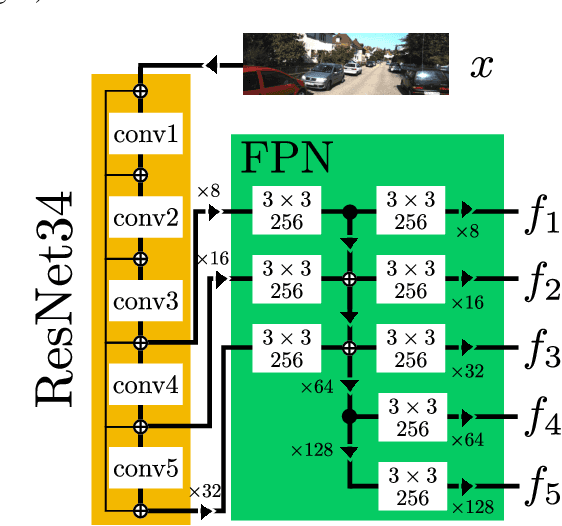
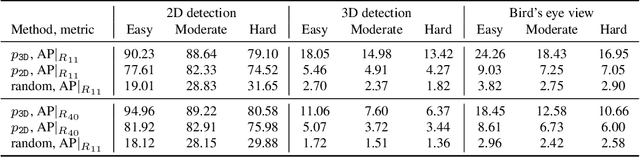
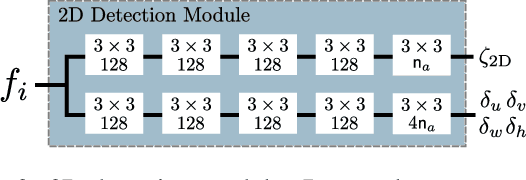
In this paper we propose an approach for monocular 3D object detection from a single RGB image, which leverages a novel disentangling transformation for 2D and 3D detection losses and a novel, self-supervised confidence score for 3D bounding boxes. Our proposed loss disentanglement has the twofold advantage of simplifying the training dynamics in the presence of losses with complex interactions of parameters, and sidestepping the issue of balancing independent regression terms. Our solution overcomes these issues by isolating the contribution made by groups of parameters to a given loss, without changing its nature. We further apply loss disentanglement to another novel, signed Intersection-over-Union criterion-driven loss for improving 2D detection results. Besides our methodological innovations, we critically review the AP metric used in KITTI3D, which emerged as the most important dataset for comparing 3D detection results. We identify and resolve a flaw in the 11-point interpolated AP metric, affecting all previously published detection results and particularly biases the results of monocular 3D detection. We provide extensive experimental evaluations and ablation studies on the KITTI3D and nuScenes datasets, setting new state-of-the-art results on object category car by large margins.