 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Knowledge in Multi-Task Deep Reinforcement Learning
Jan 17, 2024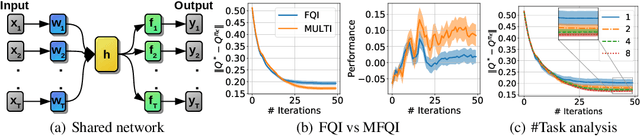



We study the benefit of sharing representations among tasks to enable the effective use of deep neural networks in Multi-Task Reinforcement Learning. We leverage the assumption that learning from different tasks, sharing common properties, is helpful to generalize the knowledge of them resulting in a more effective feature extraction compared to learning a single task. Intuitively, the resulting set of features offers performance benefits when used by Reinforcement Learning algorithms. We prove this by providing theoretical guarantees that highlight the conditions for which is convenient to share representations among tasks, extending the well-known finite-time bounds of Approximate Value-Iteration to the multi-task setting. In addition, we complement our analysis by proposing multi-task extensions of three Reinforcement Learning algorithms that we empirically evaluate on widely used Reinforcement Learning benchmarks showing significant improvements over the single-task counterparts in terms of sample efficiency and performance.
Object Structural Points Representation for Graph-based Semantic Monocular Localization and Mapping
Jun 21, 2022
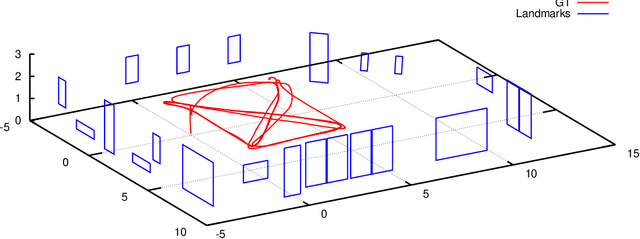
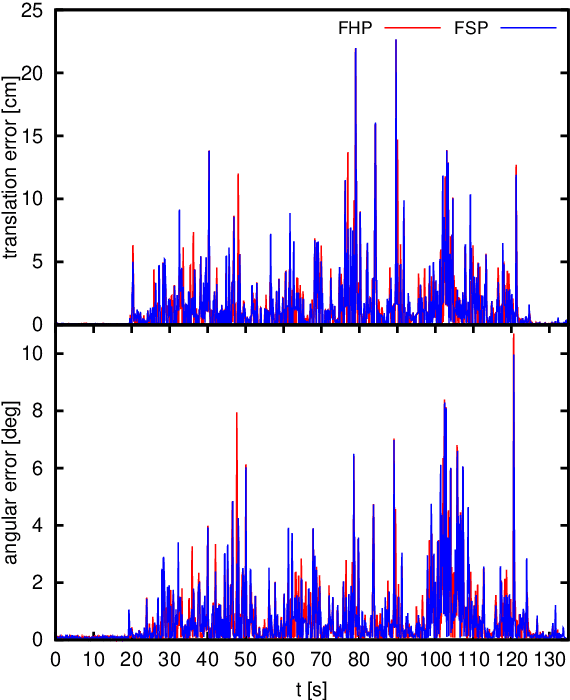

Efficient object level representation for monocular semantic simultaneous localization and mapping (SLAM) still lacks a widely accepted solution. In this paper, we propose the use of an efficient representation, based on structural points, for the geometry of objects to be used as landmarks in a monocular semantic SLAM system based on the pose-graph formulation. In particular, an inverse depth parametrization is proposed for the landmark nodes in the pose-graph to store object position, orientation and size/scale. The proposed formulation is general and it can be applied to different geometries; in this paper we focus on indoor environments where human-made artifacts commonly share a planar rectangular shape, e.g., windows, doors, cabinets, etc. The approach can be easily extended to urban scenarios where similar shapes exists as well. Experiments in simulation show good performance, particularly in object geometry reconstruction.
Uncertainty Maximization in Partially Observable Domains: A Cognitive Perspective
Mar 10, 2021
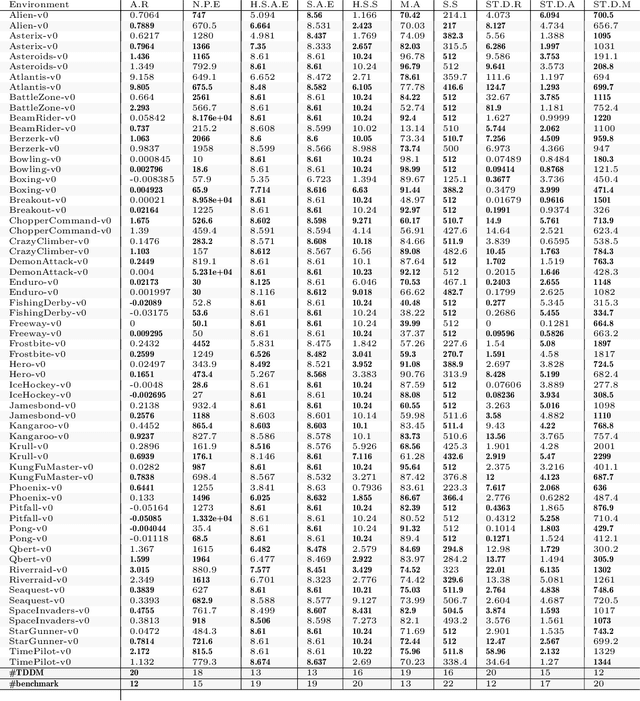

Faced with an ever-increasing complexity of their domains of application, artificial learning agents are now able to scale up in their ability to process an overwhelming amount of information coming from their interaction with an environment. However, this process of scaling does come with a cost of encoding and processing an increasing amount of redundant information that is not necessarily beneficial to the learning process itself. This work exploits the properties of the learning systems defined over partially observable domains by selectively focusing on the specific type of information that is more likely to express the causal interaction among the transitioning states of the environment. Adaptive masking of the observation space based on the $\textit{temporal difference displacement}$ criterion enabled a significant improvement in convergence of temporal difference algorithms defined over a partially observable Markov process.
MushroomRL: Simplifying Reinforcement Learning Research
Jan 09, 2020

MushroomRL is an open-source Python library developed to simplify the process of implementing and running Reinforcement Learning (RL) experiments. Compared to other available libraries, MushroomRL has been created with the purpose of providing a comprehensive and flexible framework to minimize the effort in implementing and testing novel RL methodologies. Indeed, the architecture of MushroomRL is built in such a way that every component of an RL problem is already provided, and most of the time users can only focus on the implementation of their own algorithms and experiments. The result is a library from which RL researchers can significantly benefit in the critical phase of the empirical analysis of their works. MushroomRL stable code, tutorials and documentation can be found at https://github.com/MushroomRL/mushroom-rl.
Augmented Replay Memory in Reinforcement Learning With Continuous Control
Dec 29, 2019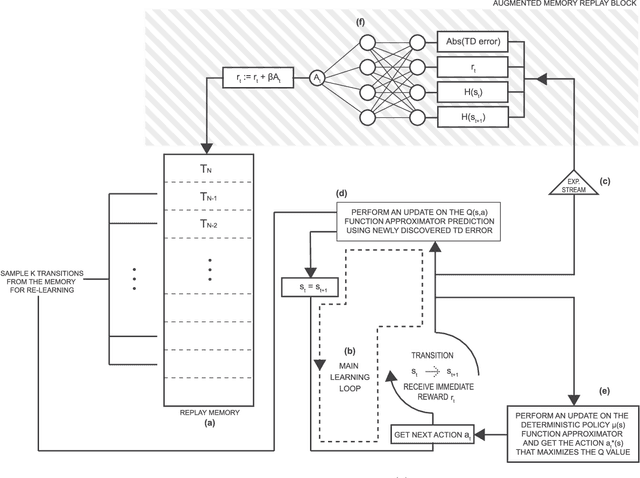
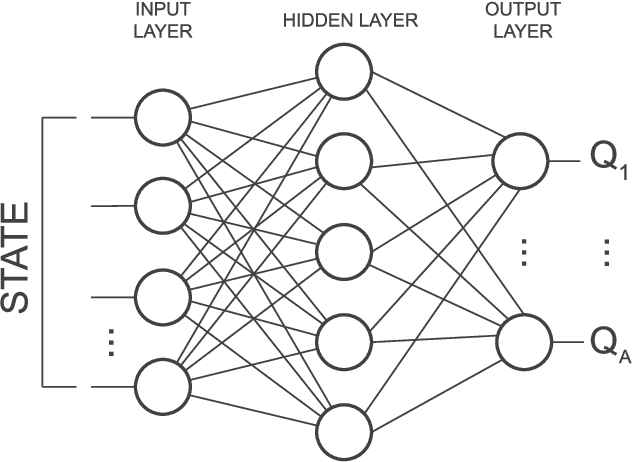
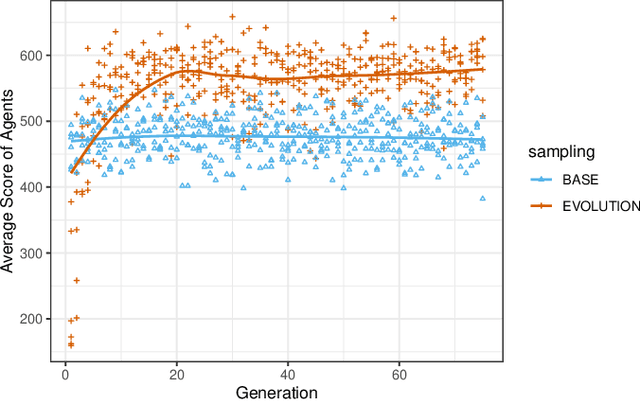
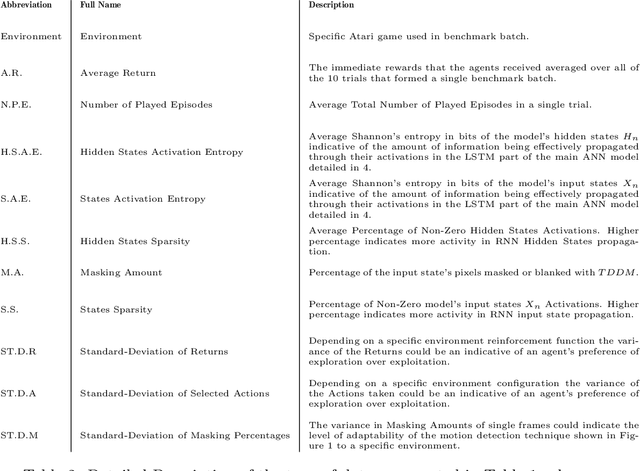
Online reinforcement learning agents are currently able to process an increasing amount of data by converting it into a higher order value functions. This expansion of the information collected from the environment increases the agent's state space enabling it to scale up to a more complex problems but also increases the risk of forgetting by learning on redundant or conflicting data. To improve the approximation of a large amount of data, a random mini-batch of the past experiences that are stored in the replay memory buffer is often replayed at each learning step. The proposed work takes inspiration from a biological mechanism which act as a protective layer of human brain higher cognitive functions: active memory consolidation mitigates the effect of forgetting of previous memories by dynamically processing the new ones. The similar dynamics are implemented by a proposed augmented memory replay AMR capable of optimizing the replay of the experiences from the agent's memory structure by altering or augmenting their relevance. Experimental results show that an evolved AMR augmentation function capable of increasing the significance of the specific memories is able to further increase the stability and convergence speed of the learning algorithms dealing with the complexity of continuous action domains.
Safety experiments for small robots investigating the potential of soft materials in mitigating the harm to the head due to impacts
Apr 21, 2019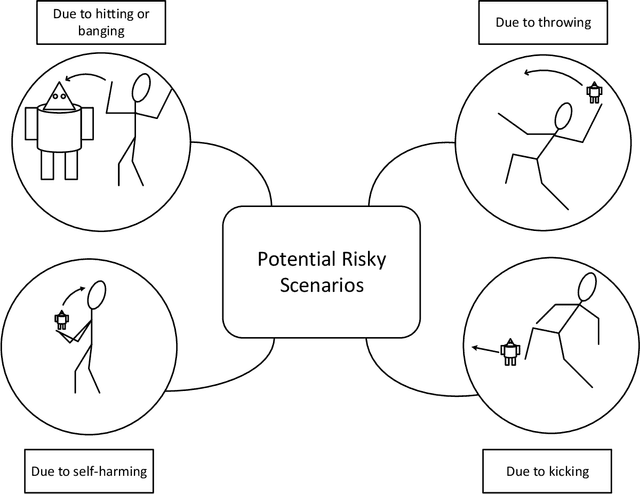
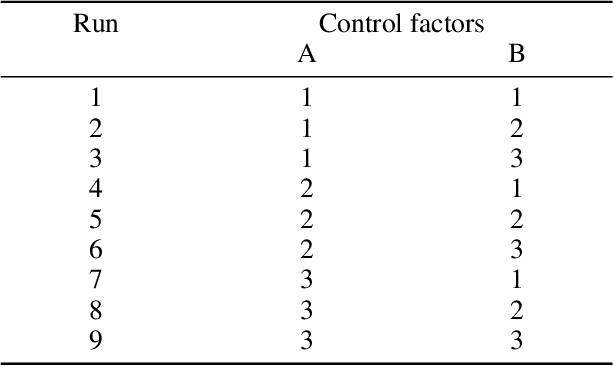
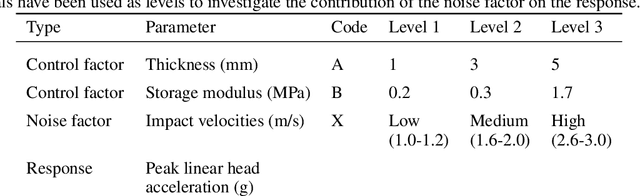

There is a growing interest in social robots to be considered in the therapy of children with autism due to their effectiveness in improving the outcomes. However, children on the spectrum exhibit challenging behaviors that need to be considered when designing robots for them. A child could involuntarily throw a small social robot during meltdown and that could hit another person's head and cause harm (e.g. concussion). In this paper, the application of soft materials is investigated for its potential in attenuating head's linear acceleration upon impact. The thickness and storage modulus of three different soft materials were considered as the control factors while the noise factor was the impact velocity. The design of experiments was based on Taguchi method. A total of 27 experiments were conducted on a developed dummy head setup that reports the linear acceleration of the head. ANOVA tests were performed to analyze the data. The findings showed that the control factors are not statistically significant in attenuating the response. The optimal values of the control factors were identified using the signal-to-noise (S/N) ratio optimization technique. Confirmation runs at the optimal parameters (i.e. thickness of 3 mm and 5 mm) showed a better response as compared to other conditions. Designers of social robots should consider the application of soft materials to their designs as it help in reducing the potential harm to the head.