 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Maximization in Partially Observable Domains: A Cognitive Perspective
Mar 10, 2021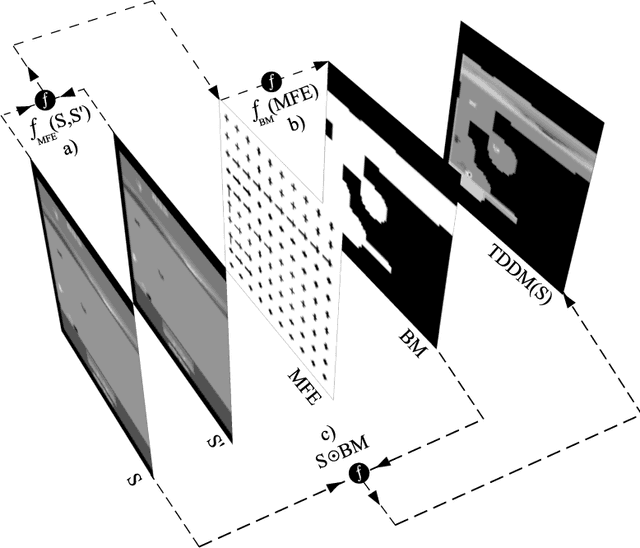
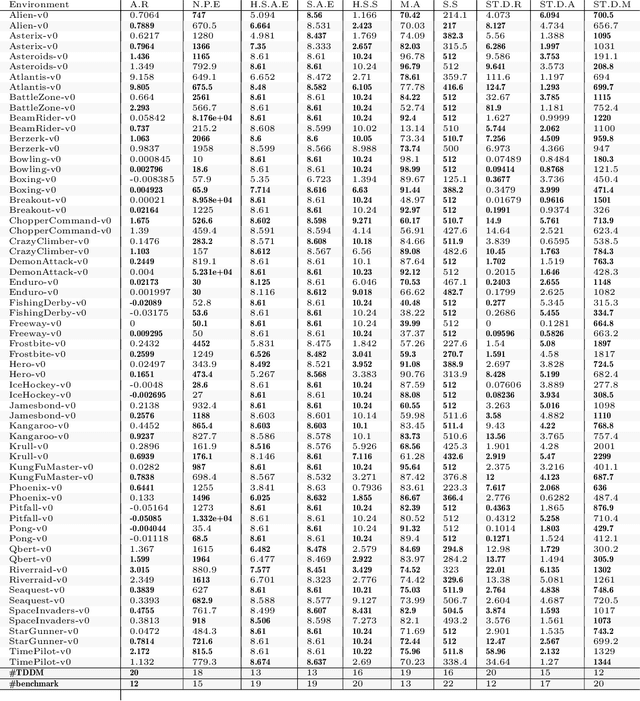

Faced with an ever-increasing complexity of their domains of application, artificial learning agents are now able to scale up in their ability to process an overwhelming amount of information coming from their interaction with an environment. However, this process of scaling does come with a cost of encoding and processing an increasing amount of redundant information that is not necessarily beneficial to the learning process itself. This work exploits the properties of the learning systems defined over partially observable domains by selectively focusing on the specific type of information that is more likely to express the causal interaction among the transitioning states of the environment. Adaptive masking of the observation space based on the $\textit{temporal difference displacement}$ criterion enabled a significant improvement in convergence of temporal difference algorithms defined over a partially observable Markov process.
Augmented Replay Memory in Reinforcement Learning With Continuous Control
Dec 29, 2019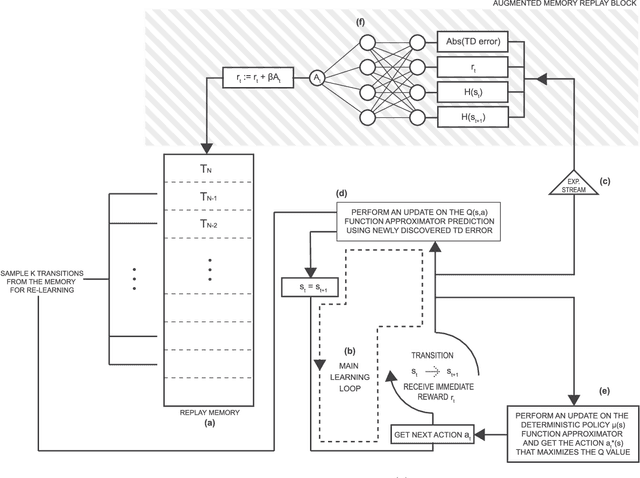
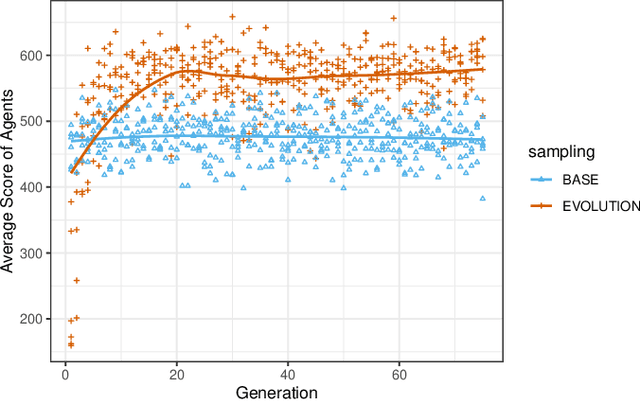
Online reinforcement learning agents are currently able to process an increasing amount of data by converting it into a higher order value functions. This expansion of the information collected from the environment increases the agent's state space enabling it to scale up to a more complex problems but also increases the risk of forgetting by learning on redundant or conflicting data. To improve the approximation of a large amount of data, a random mini-batch of the past experiences that are stored in the replay memory buffer is often replayed at each learning step. The proposed work takes inspiration from a biological mechanism which act as a protective layer of human brain higher cognitive functions: active memory consolidation mitigates the effect of forgetting of previous memories by dynamically processing the new ones. The similar dynamics are implemented by a proposed augmented memory replay AMR capable of optimizing the replay of the experiences from the agent's memory structure by altering or augmenting their relevance. Experimental results show that an evolved AMR augmentation function capable of increasing the significance of the specific memories is able to further increase the stability and convergence speed of the learning algorithms dealing with the complexity of continuous action domains.