 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated structural testing of LLM-based agents: methods, framework, and case studies
Jan 25, 2026LLM-based agents are rapidly being adopted across diverse domains. Since they interact with users without supervision, they must be tested extensively. Current testing approaches focus on acceptance-level evaluation from the user's perspective. While intuitive, these tests require manual evaluation, are difficult to automate, do not facilitate root cause analysis, and incur expensive test environments. In this paper, we present methods to enable structural testing of LLM-based agents. Our approach utilizes traces (based on OpenTelemetry) to capture agent trajectories, employs mocking to enforce reproducible LLM behavior, and adds assertions to automate test verification. This enables testing agent components and interactions at a deeper technical level within automated workflows. We demonstrate how structural testing enables the adaptation of software engineering best practices to agents, including the test automation pyramid, regression testing, test-driven development, and multi-language testing. In representative case studies, we demonstrate automated execution and faster root-cause analysis. Collectively, these methods reduce testing costs and improve agent quality through higher coverage, reusability, and earlier defect detection. We provide an open source reference implementation on GitHub.
Expert Router: Orchestrating Efficient Language Model Inference through Prompt Classification
Apr 22, 2024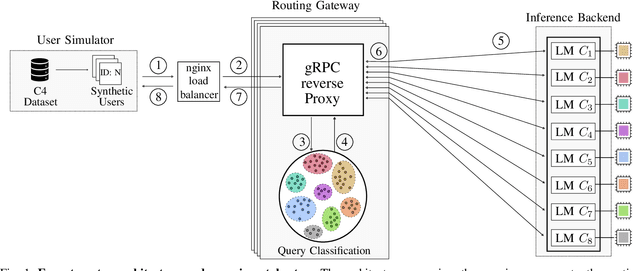
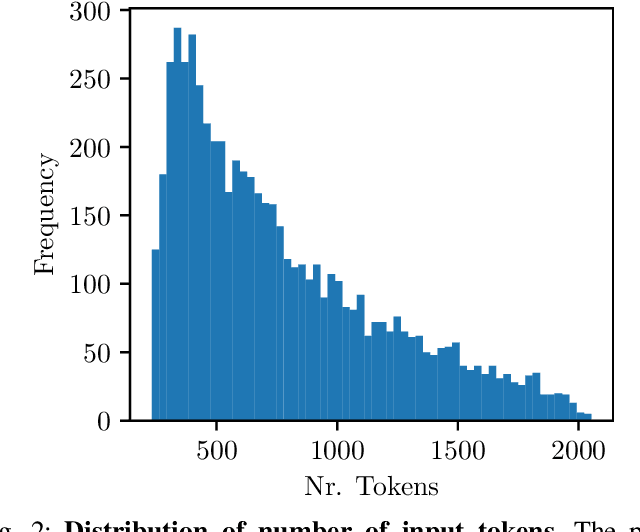
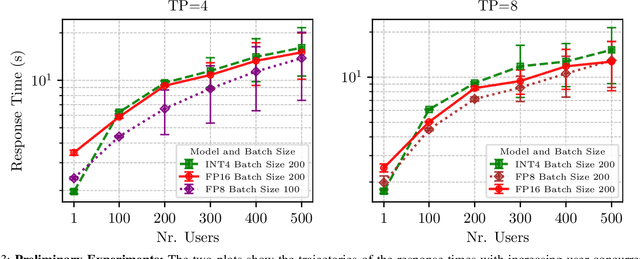
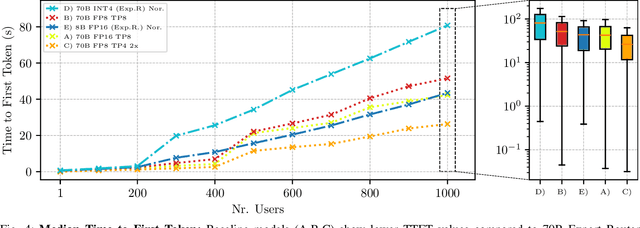
Large Language Models (LLMs) have experienced widespread adoption across scientific and industrial domains due to their versatility and utility for diverse tasks. Nevertheless, deploying and serving these models at scale with optimal throughput and latency remains a significant challenge, primarily because of the high computational and memory demands associated with LLMs. To tackle this limitation, we introduce Expert Router, a system designed to orchestrate multiple expert models efficiently, thereby enhancing scalability. Expert Router is a parallel inference system with a central routing gateway that distributes incoming requests using a clustering method. This approach effectively partitions incoming requests among available LLMs, maximizing overall throughput. Our extensive evaluations encompassed up to 1,000 concurrent users, providing comprehensive insights into the system's behavior from user and infrastructure perspectives. The results demonstrate Expert Router's effectiveness in handling high-load scenarios and achieving higher throughput rates, particularly under many concurrent users.
Application-Oriented Benchmarking of Quantum Generative Learning Using QUARK
Aug 08, 2023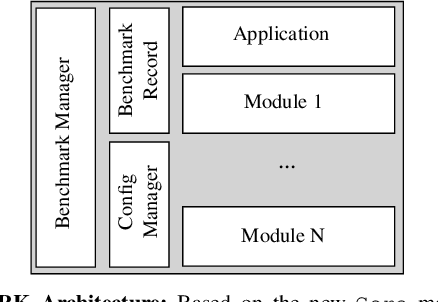
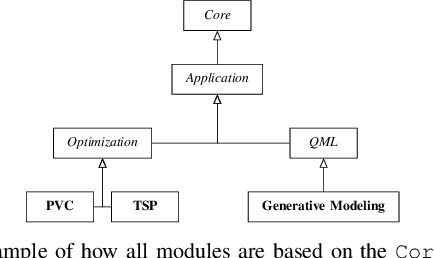
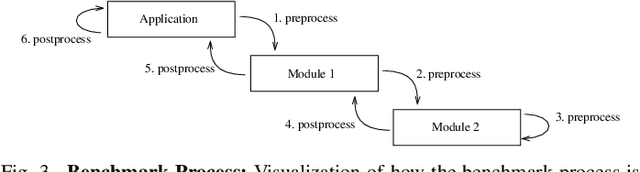
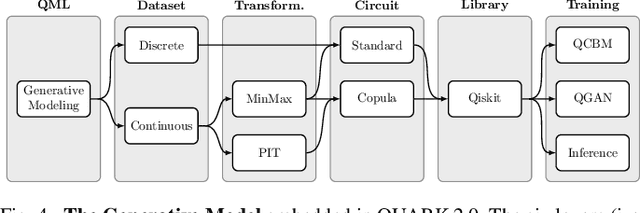
Benchmarking of quantum machine learning (QML) algorithms is challenging due to the complexity and variability of QML systems, e.g., regarding model ansatzes, data sets, training techniques, and hyper-parameters selection. The QUantum computing Application benchmaRK (QUARK) framework simplifies and standardizes benchmarking studies for quantum computing applications. Here, we propose several extensions of QUARK to include the ability to evaluate the training and deployment of quantum generative models. We describe the updated software architecture and illustrate its flexibility through several example applications: (1) We trained different quantum generative models using several circuit ansatzes, data sets, and data transformations. (2) We evaluated our models on GPU and real quantum hardware. (3) We assessed the generalization capabilities of our generative models using a broad set of metrics that capture, e.g., the novelty and validity of the generated data.
Optimization of Robot Trajectory Planning with Nature-Inspired and Hybrid Quantum Algorithms
Jun 08, 2022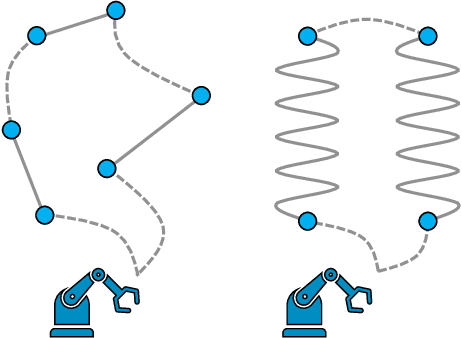
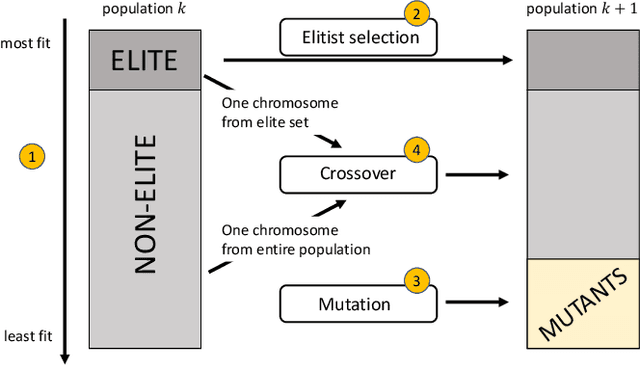
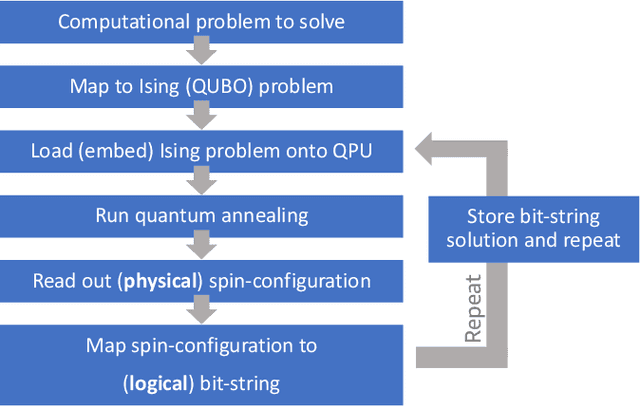
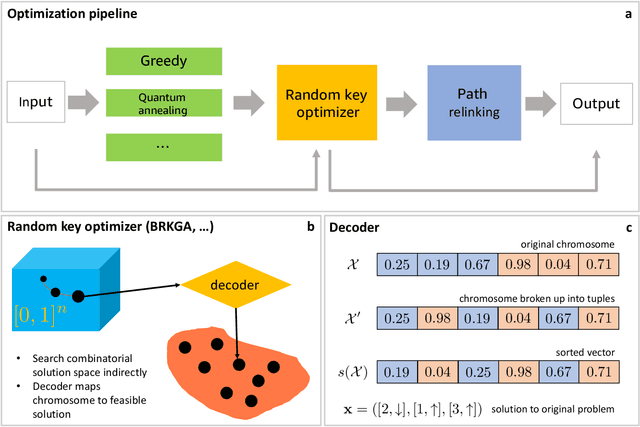
We solve robot trajectory planning problems at industry-relevant scales. Our end-to-end solution integrates highly versatile random-key algorithms with model stacking and ensemble techniques, as well as path relinking for solution refinement. The core optimization module consists of a biased random-key genetic algorithm. Through a distinct separation of problem-independent and problem-dependent modules, we achieve an efficient problem representation, with a native encoding of constraints. We show that generalizations to alternative algorithmic paradigms such as simulated annealing are straightforward. We provide numerical benchmark results for industry-scale data sets. Our approach is found to consistently outperform greedy baseline results. To assess the capabilities of today's quantum hardware, we complement the classical approach with results obtained on quantum annealing hardware, using qbsolv on Amazon Braket. Finally, we show how the latter can be integrated into our larger pipeline, providing a quantum-ready hybrid solution to the problem.
Deep Learning in the Automotive Industry: Applications and Tools
Apr 30, 2017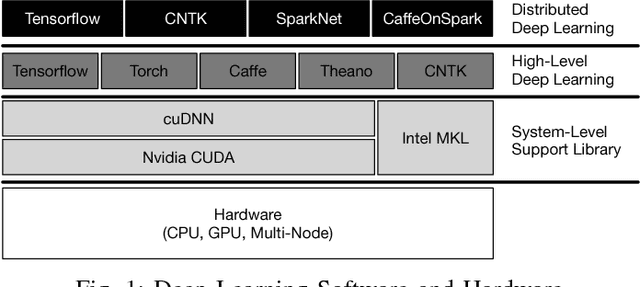
Deep Learning refers to a set of machine learning techniques that utilize neural networks with many hidden layers for tasks, such as image classification, speech recognition, language understanding. Deep learning has been proven to be very effective in these domains and is pervasively used by many Internet services. In this paper, we describe different automotive uses cases for deep learning in particular in the domain of computer vision. We surveys the current state-of-the-art in libraries, tools and infrastructures (e.\,g.\ GPUs and clouds) for implementing, training and deploying deep neural networks. We particularly focus on convolutional neural networks and computer vision use cases, such as the visual inspection process in manufacturing plants and the analysis of social media data. To train neural networks, curated and labeled datasets are essential. In particular, both the availability and scope of such datasets is typically very limited. A main contribution of this paper is the creation of an automotive dataset, that allows us to learn and automatically recognize different vehicle properties. We describe an end-to-end deep learning application utilizing a mobile app for data collection and process support, and an Amazon-based cloud backend for storage and training. For training we evaluate the use of cloud and on-premises infrastructures (including multiple GPUs) in conjunction with different neural network architectures and frameworks. We assess both the training times as well as the accuracy of the classifier. Finally, we demonstrate the effectiveness of the trained classifier in a real world setting during manufacturing process.
Algebraic multigrid support vector machines
Nov 24, 2016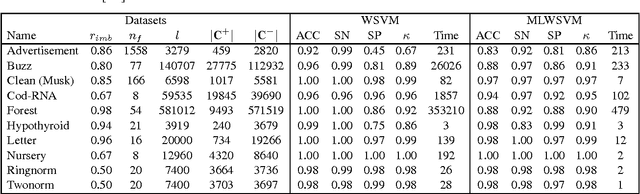
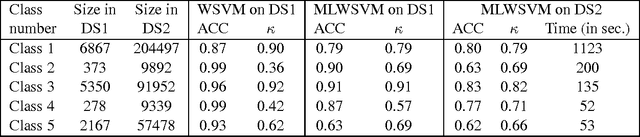
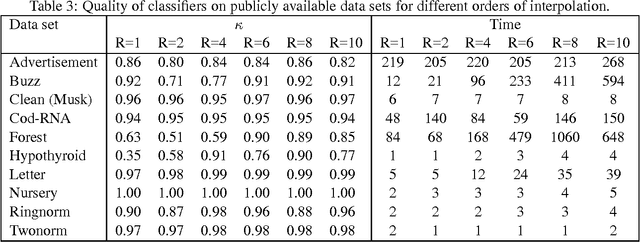
The support vector machine is a flexible optimization-based technique widely used for classification problems. In practice, its training part becomes computationally expensive on large-scale data sets because of such reasons as the complexity and number of iterations in parameter fitting methods, underlying optimization solvers, and nonlinearity of kernels. We introduce a fast multilevel framework for solving support vector machine models that is inspired by the algebraic multigrid. Significant improvement in the running has been achieved without any loss in the quality. The proposed technique is highly beneficial on imbalanced sets. We demonstrate computational results on publicly available and industrial data sets.