 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Image Data for Deep Learning
Dec 12, 2022Realistic synthetic image data rendered from 3D models can be used to augment image sets and train image classification semantic segmentation models. In this work, we explore how high quality physically-based rendering and domain randomization can efficiently create a large synthetic dataset based on production 3D CAD models of a real vehicle. We use this dataset to quantify the effectiveness of synthetic augmentation using U-net and Double-U-net models. We found that, for this domain, synthetic images were an effective technique for augmenting limited sets of real training data. We observed that models trained on purely synthetic images had a very low mean prediction IoU on real validation images. We also observed that adding even very small amounts of real images to a synthetic dataset greatly improved accuracy, and that models trained on datasets augmented with synthetic images were more accurate than those trained on real images alone. Finally, we found that in use cases that benefit from incremental training or model specialization, pretraining a base model on synthetic images provided a sizeable reduction in the training cost of transfer learning, allowing up to 90\% of the model training to be front-loaded.
Algebraic multigrid support vector machines
Nov 24, 2016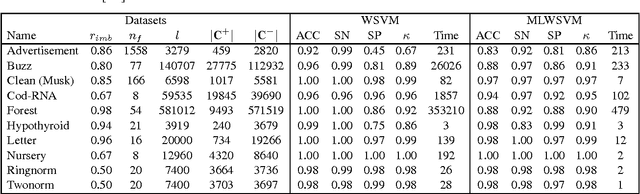
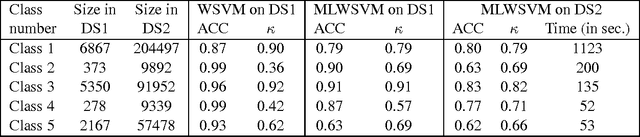
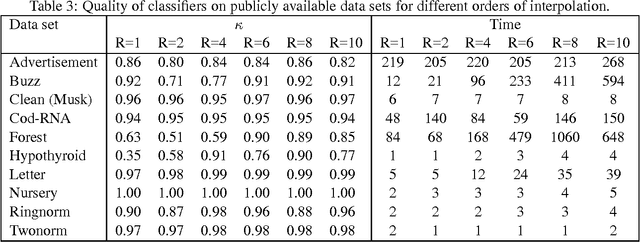
The support vector machine is a flexible optimization-based technique widely used for classification problems. In practice, its training part becomes computationally expensive on large-scale data sets because of such reasons as the complexity and number of iterations in parameter fitting methods, underlying optimization solvers, and nonlinearity of kernels. We introduce a fast multilevel framework for solving support vector machine models that is inspired by the algebraic multigrid. Significant improvement in the running has been achieved without any loss in the quality. The proposed technique is highly beneficial on imbalanced sets. We demonstrate computational results on publicly available and industrial data sets.