 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Machine Learning Models for Federated Learning: A Review of Approaches, Performance, and Limitations
Nov 17, 2023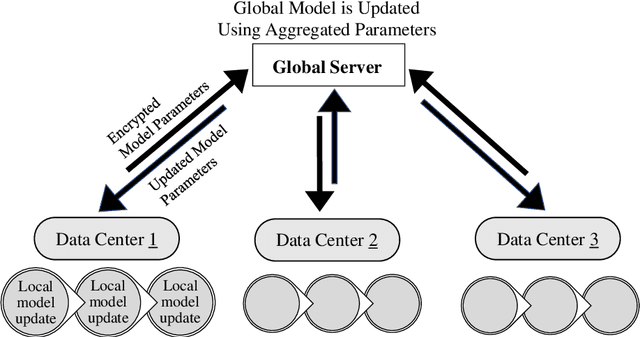

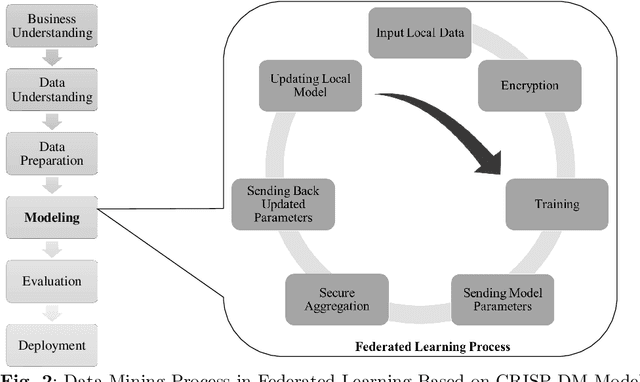
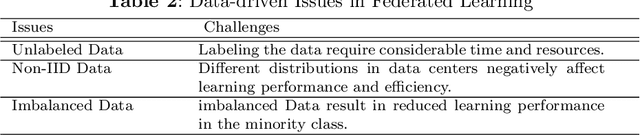
In the growing world of artificial intelligence, federated learning is a distributed learning framework enhanced to preserve the privacy of individuals' data. Federated learning lays the groundwork for collaborative research in areas where the data is sensitive. Federated learning has several implications for real-world problems. In times of crisis, when real-time decision-making is critical, federated learning allows multiple entities to work collectively without sharing sensitive data. This distributed approach enables us to leverage information from multiple sources and gain more diverse insights. This paper is a systematic review of the literature on privacy-preserving machine learning in the last few years based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Specifically, we have presented an extensive review of supervised/unsupervised machine learning algorithms, ensemble methods, meta-heuristic approaches, blockchain technology, and reinforcement learning used in the framework of federated learning, in addition to an overview of federated learning applications. This paper reviews the literature on the components of federated learning and its applications in the last few years. The main purpose of this work is to provide researchers and practitioners with a comprehensive overview of federated learning from the machine learning point of view. A discussion of some open problems and future research directions in federated learning is also provided.
Personalized Colorectal Cancer Survivability Prediction with Machine Learning Methods
Jan 12, 2019
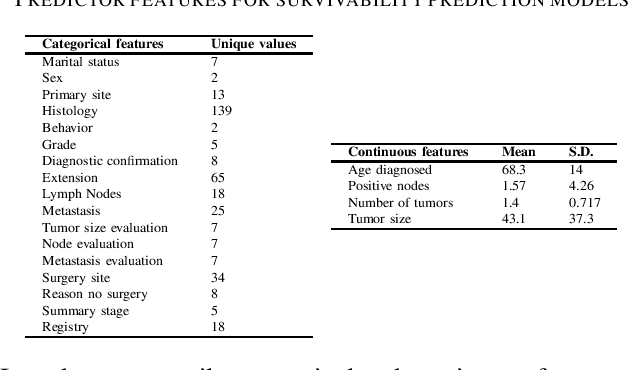

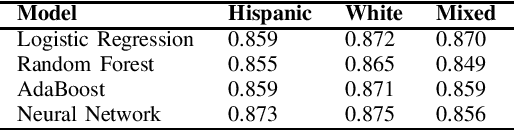
In this work, we investigate the importance of ethnicity in colorectal cancer survivability prediction using machine learning techniques and the SEER cancer incidence database. We compare model performances for 2-year survivability prediction and feature importance rankings between Hispanic, White, and mixed patient populations. Our models consistently perform better on single-ethnicity populations and provide different feature importance rankings when trained in different populations. Additionally, we show our models achieve higher Area Under Curve (AUC) score than the best reported in the literature. We also apply imbalanced classification techniques to improve classification performance when the number of patients who have survived from colorectal cancer is much larger than who have not. These results provide evidence in favor for increased consideration of patient ethnicity in cancer survivability prediction, and for more personalized medicine in general.
Algebraic multigrid support vector machines
Nov 24, 2016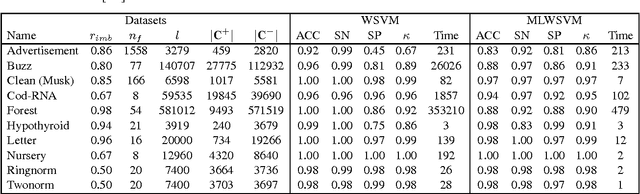
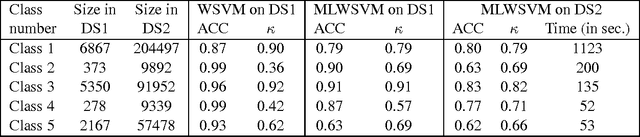
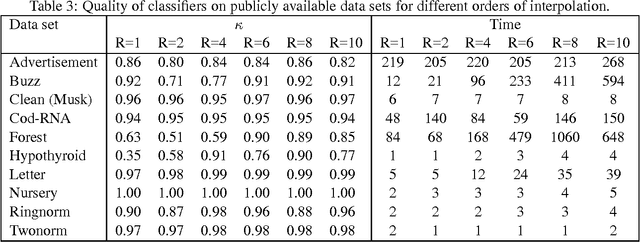
The support vector machine is a flexible optimization-based technique widely used for classification problems. In practice, its training part becomes computationally expensive on large-scale data sets because of such reasons as the complexity and number of iterations in parameter fitting methods, underlying optimization solvers, and nonlinearity of kernels. We introduce a fast multilevel framework for solving support vector machine models that is inspired by the algebraic multigrid. Significant improvement in the running has been achieved without any loss in the quality. The proposed technique is highly beneficial on imbalanced sets. We demonstrate computational results on publicly available and industrial data sets.
Multilevel Weighted Support Vector Machine for Classification on Healthcare Data with Missing Values
Apr 07, 2016
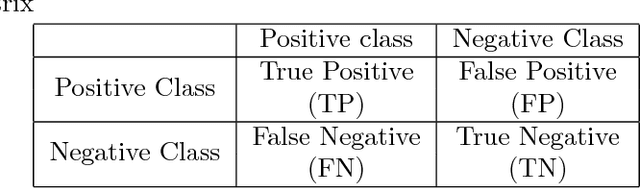


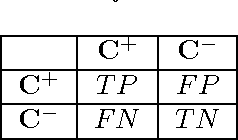
This work is motivated by the needs of predictive analytics on healthcare data as represented by Electronic Medical Records. Such data is invariably problematic: noisy, with missing entries, with imbalance in classes of interests, leading to serious bias in predictive modeling. Since standard data mining methods often produce poor performance measures, we argue for development of specialized techniques of data-preprocessing and classification. In this paper, we propose a new method to simultaneously classify large datasets and reduce the effects of missing values. It is based on a multilevel framework of the cost-sensitive SVM and the expected maximization imputation method for missing values, which relies on iterated regression analyses. We compare classification results of multilevel SVM-based algorithms on public benchmark datasets with imbalanced classes and missing values as well as real data in health applications, and show that our multilevel SVM-based method produces fast, and more accurate and robust classification results.
Fast Imbalanced Classification of Healthcare Data with Missing Values
Mar 21, 2015



In medical domain, data features often contain missing values. This can create serious bias in the predictive modeling. Typical standard data mining methods often produce poor performance measures. In this paper, we propose a new method to simultaneously classify large datasets and reduce the effects of missing values. The proposed method is based on a multilevel framework of the cost-sensitive SVM and the expected maximization imputation method for missing values, which relies on iterated regression analyses. We compare classification results of multilevel SVM-based algorithms on public benchmark datasets with imbalanced classes and missing values as well as real data in health applications, and show that our multilevel SVM-based method produces fast, and more accurate and robust classification results.
Fast Multilevel Support Vector Machines
Oct 13, 2014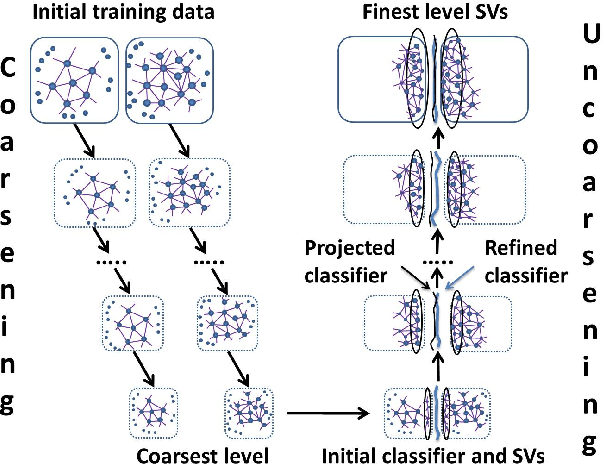
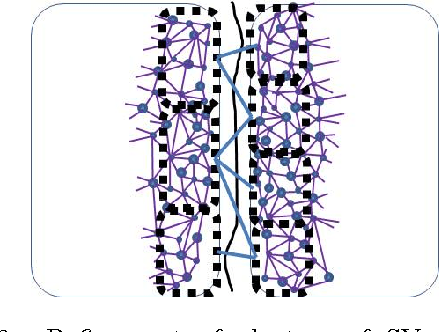
Solving different types of optimization models (including parameters fitting) for support vector machines on large-scale training data is often an expensive computational task. This paper proposes a multilevel algorithmic framework that scales efficiently to very large data sets. Instead of solving the whole training set in one optimization process, the support vectors are obtained and gradually refined at multiple levels of coarseness of the data. The proposed framework includes: (a) construction of hierarchy of large-scale data coarse representations, and (b) a local processing of updating the hyperplane throughout this hierarchy. Our multilevel framework substantially improves the computational time without loosing the quality of classifiers. The algorithms are demonstrated for both regular and weighted support vector machines. Experimental results are presented for balanced and imbalanced classification problems. Quality improvement on several imbalanced data sets has been observed.