 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI/ML-Based Automatic Modulation Recognition: Recent Trends and Future Possibilities
Feb 07, 2025



We present a review of high-performance automatic modulation recognition (AMR) models proposed in the literature to classify various Radio Frequency (RF) modulation schemes. We replicated these models and compared their performance in terms of accuracy across a range of signal-to-noise ratios. To ensure a fair comparison, we used the same dataset (RadioML-2016A), the same hardware, and a consistent definition of test accuracy as the evaluation metric, thereby providing a benchmark for future AMR studies. The hyperparameters were selected based on the authors' suggestions in the associated references to achieve results as close as possible to the originals. The replicated models are publicly accessible for further analysis of AMR models. We also present the test accuracies of the selected models versus their number of parameters, indicating their complexities. Building on this comparative analysis, we identify strategies to enhance these models' performance. Finally, we present potential opportunities for improvement, whether through novel architectures, data processing techniques, or training strategies, to further advance the capabilities of AMR models.
Using Federated Machine Learning in Predictive Maintenance of Jet Engines
Feb 07, 2025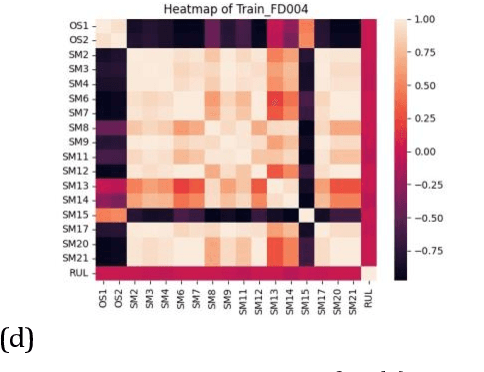
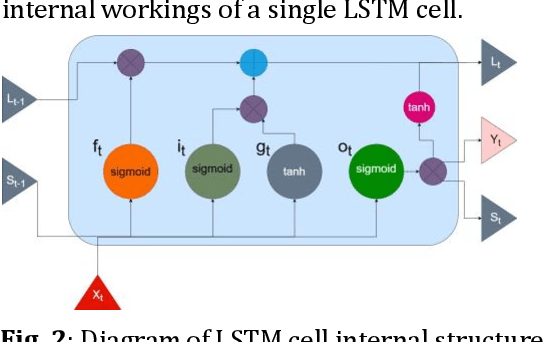

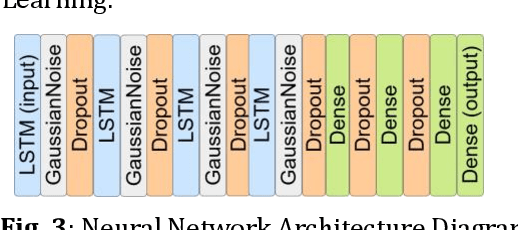
The goal of this paper is to predict the Remaining Useful Life (RUL) of turbine jet engines using a federated machine learning framework. Federated Learning enables multiple edge devices/nodes or servers to collaboratively train a shared model without sharing sensitive data, thus preserving data privacy and security. By implementing a nonlinear model, the system aims to capture complex relationships and patterns in the engine data to enhance the accuracy of RUL predictions. This approach leverages decentralized computation, allowing models to be trained locally at each device before aggregating the learned weights at a central server. By predicting the RUL of jet engines accurately, maintenance schedules can be optimized, downtime reduced, and operational efficiency improved, ultimately leading to cost savings and enhanced performance in the aviation industry. Computational results are provided by using the C-MAPSS dataset which is publicly available on the NASA website and is a valuable resource for studying and analyzing engine degradation behaviors in various operational scenarios.
Exploring Machine Learning Models for Federated Learning: A Review of Approaches, Performance, and Limitations
Nov 17, 2023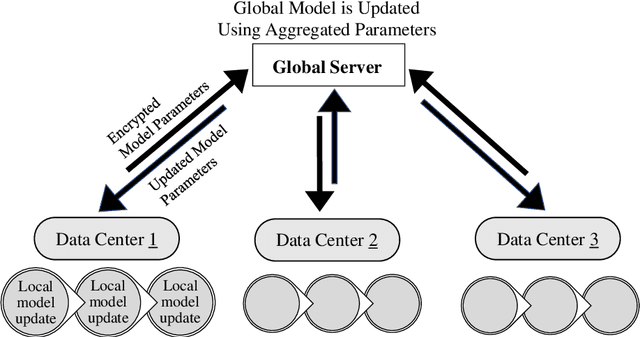

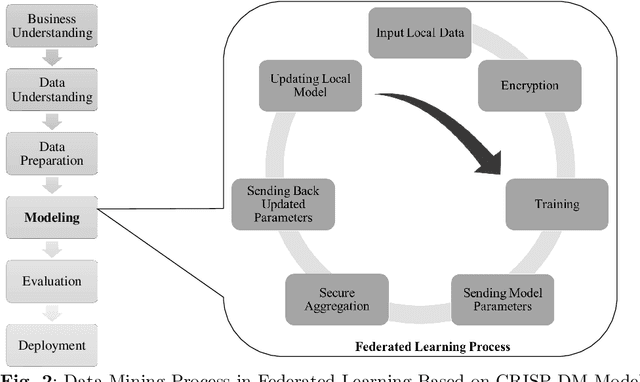
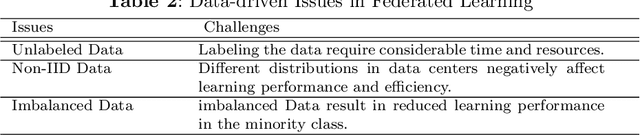
In the growing world of artificial intelligence, federated learning is a distributed learning framework enhanced to preserve the privacy of individuals' data. Federated learning lays the groundwork for collaborative research in areas where the data is sensitive. Federated learning has several implications for real-world problems. In times of crisis, when real-time decision-making is critical, federated learning allows multiple entities to work collectively without sharing sensitive data. This distributed approach enables us to leverage information from multiple sources and gain more diverse insights. This paper is a systematic review of the literature on privacy-preserving machine learning in the last few years based on the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. Specifically, we have presented an extensive review of supervised/unsupervised machine learning algorithms, ensemble methods, meta-heuristic approaches, blockchain technology, and reinforcement learning used in the framework of federated learning, in addition to an overview of federated learning applications. This paper reviews the literature on the components of federated learning and its applications in the last few years. The main purpose of this work is to provide researchers and practitioners with a comprehensive overview of federated learning from the machine learning point of view. A discussion of some open problems and future research directions in federated learning is also provided.
The Paradox of Noise: An Empirical Study of Noise-Infusion Mechanisms to Improve Generalization, Stability, and Privacy in Federated Learning
Nov 09, 2023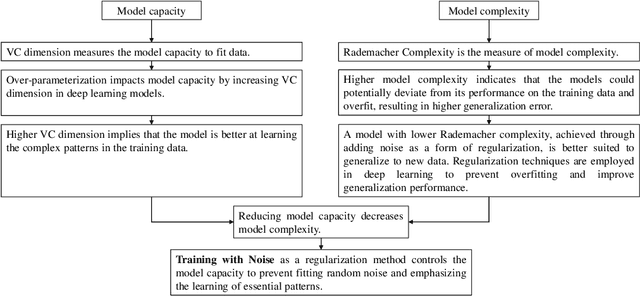

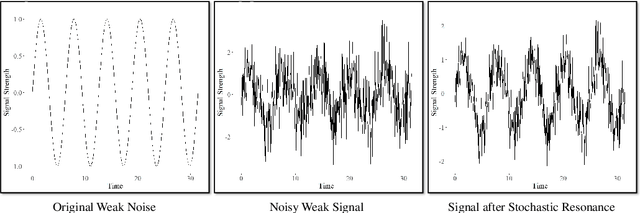

In a data-centric era, concerns regarding privacy and ethical data handling grow as machine learning relies more on personal information. This empirical study investigates the privacy, generalization, and stability of deep learning models in the presence of additive noise in federated learning frameworks. Our main objective is to provide strategies to measure the generalization, stability, and privacy-preserving capabilities of these models and further improve them. To this end, five noise infusion mechanisms at varying noise levels within centralized and federated learning settings are explored. As model complexity is a key component of the generalization and stability of deep learning models during training and evaluation, a comparative analysis of three Convolutional Neural Network (CNN) architectures is provided. The paper introduces Signal-to-Noise Ratio (SNR) as a quantitative measure of the trade-off between privacy and training accuracy of noise-infused models, aiming to find the noise level that yields optimal privacy and accuracy. Moreover, the Price of Stability and Price of Anarchy are defined in the context of privacy-preserving deep learning, contributing to the systematic investigation of the noise infusion strategies to enhance privacy without compromising performance. Our research sheds light on the delicate balance between these critical factors, fostering a deeper understanding of the implications of noise-based regularization in machine learning. By leveraging noise as a tool for regularization and privacy enhancement, we aim to contribute to the development of robust, privacy-aware algorithms, ensuring that AI-driven solutions prioritize both utility and privacy.
A Distributed Approach to Meteorological Predictions: Addressing Data Imbalance in Precipitation Prediction Models through Federated Learning and GANs
Oct 19, 2023The classification of weather data involves categorizing meteorological phenomena into classes, thereby facilitating nuanced analyses and precise predictions for various sectors such as agriculture, aviation, and disaster management. This involves utilizing machine learning models to analyze large, multidimensional weather datasets for patterns and trends. These datasets may include variables such as temperature, humidity, wind speed, and pressure, contributing to meteorological conditions. Furthermore, it's imperative that classification algorithms proficiently navigate challenges such as data imbalances, where certain weather events (e.g., storms or extreme temperatures) might be underrepresented. This empirical study explores data augmentation methods to address imbalanced classes in tabular weather data in centralized and federated settings. Employing data augmentation techniques such as the Synthetic Minority Over-sampling Technique or Generative Adversarial Networks can improve the model's accuracy in classifying rare but critical weather events. Moreover, with advancements in federated learning, machine learning models can be trained across decentralized databases, ensuring privacy and data integrity while mitigating the need for centralized data storage and processing. Thus, the classification of weather data stands as a critical bridge, linking raw meteorological data to actionable insights, enhancing our capacity to anticipate and prepare for diverse weather conditions.
Religious Affiliation in the Twenty-First Century: A Machine Learning Perspective on the World Value Survey
Oct 16, 2023This paper is a quantitative analysis of the data collected globally by the World Value Survey. The data is used to study the trajectories of change in individuals' religious beliefs, values, and behaviors in societies. Utilizing random forest, we aim to identify the key factors of religiosity and classify respondents of the survey as religious and non religious using country level data. We use resampling techniques to balance the data and improve imbalanced learning performance metrics. The results of the variable importance analysis suggest that Age and Income are the most important variables in the majority of countries. The results are discussed with fundamental sociological theories regarding religion and human behavior. This study is an application of machine learning in identifying the underlying patterns in the data of 30 countries participating in the World Value Survey. The results from variable importance analysis and classification of imbalanced data provide valuable insights beneficial to theoreticians and researchers of social sciences.
A Review of Machine Learning Techniques in Imbalanced Data and Future Trends
Oct 11, 2023For over two decades, detecting rare events has been a challenging task among researchers in the data mining and machine learning domain. Real-life problems inspire researchers to navigate and further improve data processing and algorithmic approaches to achieve effective and computationally efficient methods for imbalanced learning. In this paper, we have collected and reviewed 258 peer-reviewed papers from archival journals and conference papers in an attempt to provide an in-depth review of various approaches in imbalanced learning from technical and application perspectives. This work aims to provide a structured review of methods used to address the problem of imbalanced data in various domains and create a general guideline for researchers in academia or industry who want to dive into the broad field of machine learning using large-scale imbalanced data.