 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Weighted Support Vector Machine for Classification on Healthcare Data with Missing Values
Apr 07, 2016
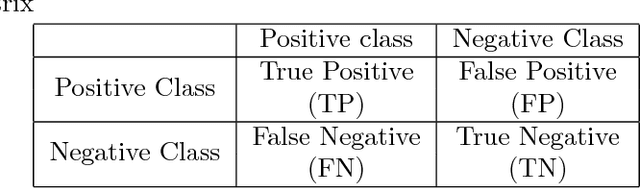


This work is motivated by the needs of predictive analytics on healthcare data as represented by Electronic Medical Records. Such data is invariably problematic: noisy, with missing entries, with imbalance in classes of interests, leading to serious bias in predictive modeling. Since standard data mining methods often produce poor performance measures, we argue for development of specialized techniques of data-preprocessing and classification. In this paper, we propose a new method to simultaneously classify large datasets and reduce the effects of missing values. It is based on a multilevel framework of the cost-sensitive SVM and the expected maximization imputation method for missing values, which relies on iterated regression analyses. We compare classification results of multilevel SVM-based algorithms on public benchmark datasets with imbalanced classes and missing values as well as real data in health applications, and show that our multilevel SVM-based method produces fast, and more accurate and robust classification results.