 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Quantum Machine Learning without Tricks: High-Resolution and Diverse Image Generation
Feb 27, 2026Quantum generative modeling is a rapidly evolving discipline at the intersection of quantum computing and machine learning. Contemporary quantum machine learning is generally limited to toy examples or heavily restricted datasets with few elements. This is not only due to the current limitations of available quantum hardware but also due to the absence of inductive biases arising from application-agnostic designs. Current quantum solutions must resort to tricks to scale down high-resolution images, such as relying heavily on dimensionality reduction or utilizing multiple quantum models for low-resolution image patches. Building on recent developments in classical image loading to quantum computers, we circumvent these limitations and train quantum Wasserstein GANs on the established classical MNIST and Fashion-MNIST datasets. Using the complete datasets, our system generates full-resolution images across all ten classes and establishes a new state-of-the-art performance with a single end-to-end quantum generator without tricks. As a proof-of-principle, we also demonstrate that our approach can be extended to color images, exemplified on the Street View House Numbers dataset. We analyze how the choice of variational circuit architecture introduces inductive biases, which crucially unlock this performance. Furthermore, enhanced noise input techniques enable highly diverse image generation while maintaining quality. Finally, we show promising results even under quantum shot noise conditions.
Generative-enhanced optimization for knapsack problems: an industry-relevant study
Feb 07, 2025Optimization is a crucial task in various industries such as logistics, aviation, manufacturing, chemical, pharmaceutical, and insurance, where finding the best solution to a problem can result in significant cost savings and increased efficiency. Tensor networks (TNs) have gained prominence in recent years in modeling classical systems with quantum-inspired approaches. More recently, TN generative-enhanced optimization (TN-GEO) has been proposed as a strategy which uses generative modeling to efficiently sample valid solutions with respect to certain constraints of optimization problems. Moreover, it has been shown that symmetric TNs (STNs) can encode certain constraints of optimization problems, thus aiding in their solution process. In this work, we investigate the applicability of TN- and STN-GEO to an industry relevant problem class, a multi-knapsack problem, in which each object must be assigned to an available knapsack. We detail a prescription for practitioners to use the TN-and STN-GEO methodology and study its scaling behavior and dependence on its hyper-parameters. We benchmark 60 different problem instances and find that TN-GEO and STN-GEO produce results of similar quality to simulated annealing.
Application-Oriented Benchmarking of Quantum Generative Learning Using QUARK
Aug 08, 2023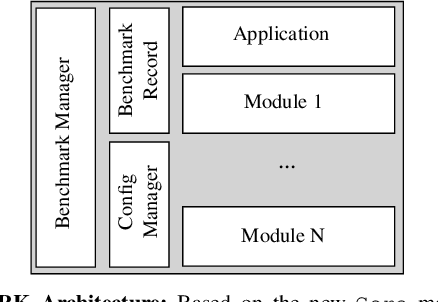
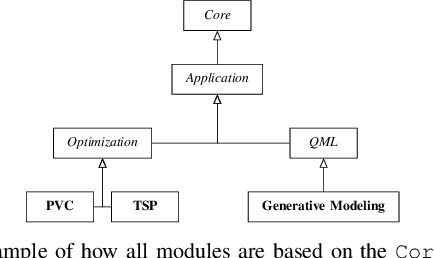
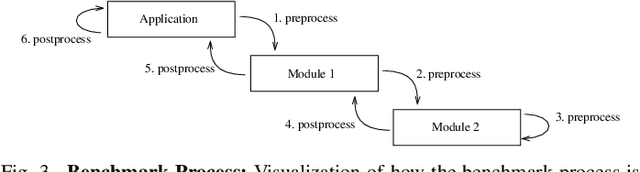
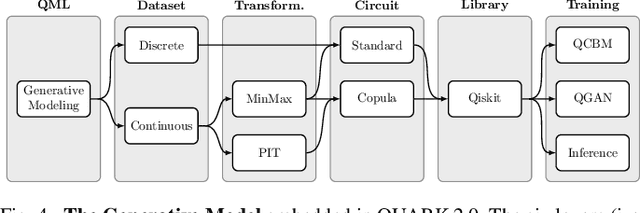
Benchmarking of quantum machine learning (QML) algorithms is challenging due to the complexity and variability of QML systems, e.g., regarding model ansatzes, data sets, training techniques, and hyper-parameters selection. The QUantum computing Application benchmaRK (QUARK) framework simplifies and standardizes benchmarking studies for quantum computing applications. Here, we propose several extensions of QUARK to include the ability to evaluate the training and deployment of quantum generative models. We describe the updated software architecture and illustrate its flexibility through several example applications: (1) We trained different quantum generative models using several circuit ansatzes, data sets, and data transformations. (2) We evaluated our models on GPU and real quantum hardware. (3) We assessed the generalization capabilities of our generative models using a broad set of metrics that capture, e.g., the novelty and validity of the generated data.