 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Router: Orchestrating Efficient Language Model Inference through Prompt Classification
Paper and Code
Apr 22, 2024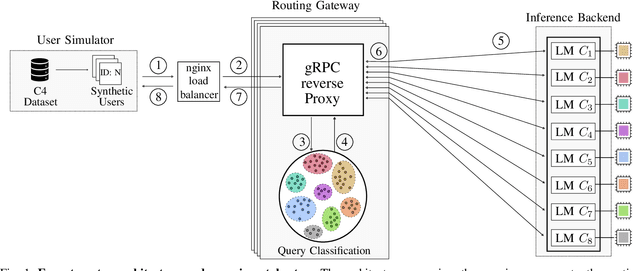
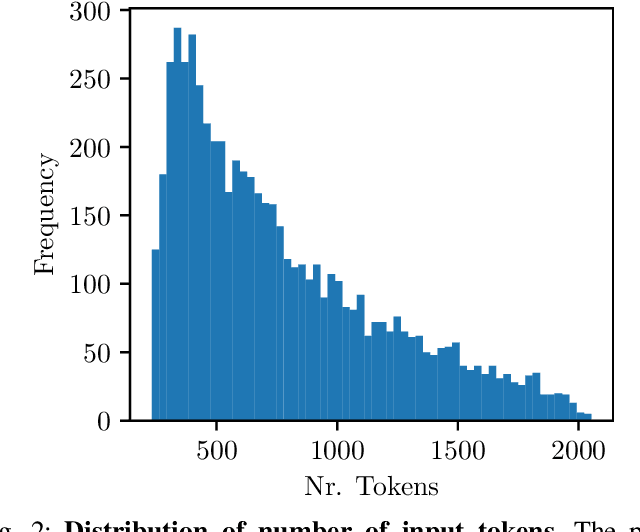
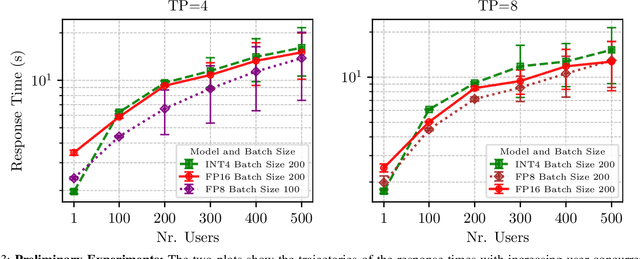
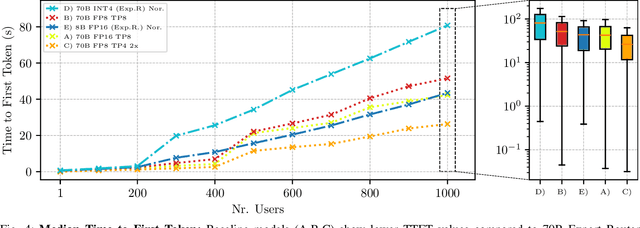
Large Language Models (LLMs) have experienced widespread adoption across scientific and industrial domains due to their versatility and utility for diverse tasks. Nevertheless, deploying and serving these models at scale with optimal throughput and latency remains a significant challenge, primarily because of the high computational and memory demands associated with LLMs. To tackle this limitation, we introduce Expert Router, a system designed to orchestrate multiple expert models efficiently, thereby enhancing scalability. Expert Router is a parallel inference system with a central routing gateway that distributes incoming requests using a clustering method. This approach effectively partitions incoming requests among available LLMs, maximizing overall throughput. Our extensive evaluations encompassed up to 1,000 concurrent users, providing comprehensive insights into the system's behavior from user and infrastructure perspectives. The results demonstrate Expert Router's effectiveness in handling high-load scenarios and achieving higher throughput rates, particularly under many concurrent users.