 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Policing Strategy for Traffic Violation Prevention
Sep 20, 2019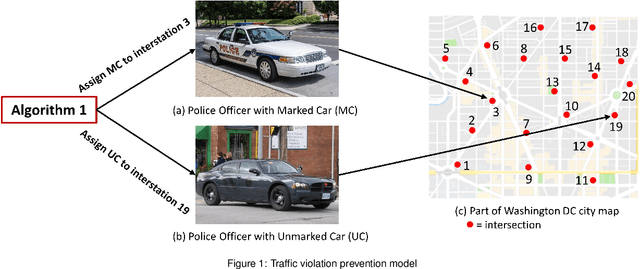


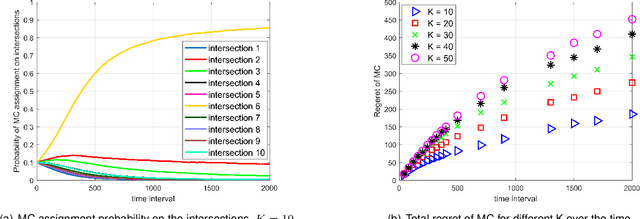
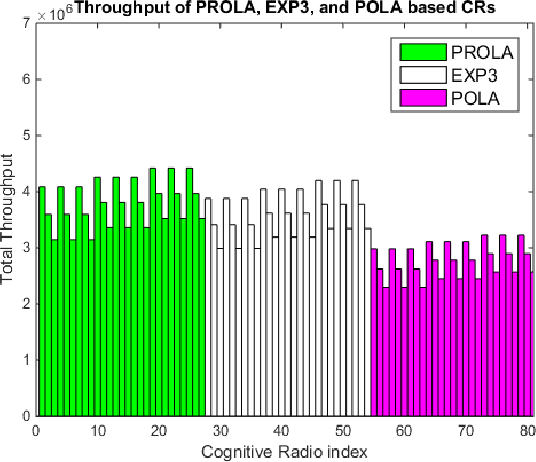
Police officer presence at an intersection discourages a potential traffic violator from violating the law. It also alerts the motorists' consciousness to take precaution and follow the rules. However, due to the abundant intersections and shortage of human resources, it is not possible to assign a police officer to every intersection. In this paper, we propose an intelligent and optimal policing strategy for traffic violation prevention. Our model consists of a specific number of targeted intersections and two police officers with no prior knowledge on the number of the traffic violations in the designated intersections. At each time interval, the proposed strategy, assigns the two police officers to different intersections such that at the end of the time horizon, maximum traffic violation prevention is achieved. Our proposed methodology adapts the PROLA (Play and Random Observe Learning Algorithm) algorithm [1] to achieve an optimal traffic violation prevention strategy. Finally, we conduct a case study to evaluate and demonstrate the performance of the proposed method.
Multi-stage Deep Classifier Cascades for Open World Recognition
Aug 26, 2019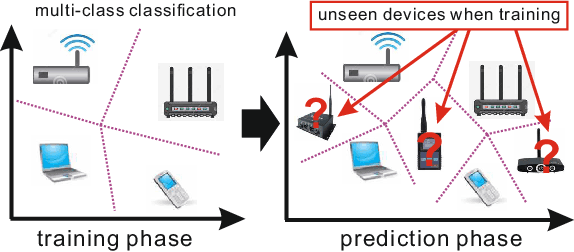

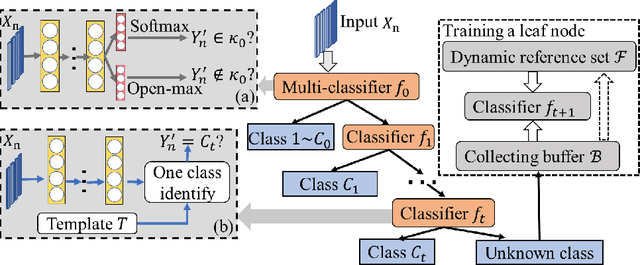

At present, object recognition studies are mostly conducted in a closed lab setting with classes in test phase typically in training phase. However, real-world problem is far more challenging because: i) new classes unseen in the training phase can appear when predicting; ii) discriminative features need to evolve when new classes emerge in real time; and iii) instances in new classes may not follow the "independent and identically distributed" (iid) assumption. Most existing work only aims to detect the unknown classes and is incapable of continuing to learn newer classes. Although a few methods consider both detecting and including new classes, all are based on the predefined handcrafted features that cannot evolve and are out-of-date for characterizing emerging classes. Thus, to address the above challenges, we propose a novel generic end-to-end framework consisting of a dynamic cascade of classifiers that incrementally learn their dynamic and inherent features. The proposed method injects dynamic elements into the system by detecting instances from unknown classes, while at the same time incrementally updating the model to include the new classes. The resulting cascade tree grows by adding a new leaf node classifier once a new class is detected, and the discriminative features are updated via an end-to-end learning strategy. Experiments on two real-world datasets demonstrate that our proposed method outperforms existing state-of-the-art methods.
Who is Smarter? Intelligence Measure of Learning-based Cognitive Radios
Mar 19, 2018
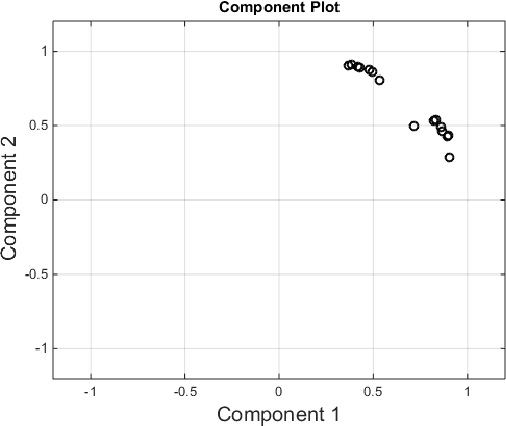

Cognitive radio (CR) is considered as a key enabling technology for dynamic spectrum access to improve spectrum efficiency. Although the CR concept was invented with the core idea of realizing cognition, the research on measuring CR cognitive capabilities and intelligence is largely open. Deriving the intelligence measure of CR not only can lead to the development of new CR technologies, but also makes it possible to better configure the networks by integrating CRs with different cognitive capabilities. In this paper, for the first time, we propose a data-driven methodology to quantitatively measure the intelligence factors of the CR with learning capabilities. The basic idea of our methodology is to run various tests on the CR in different spectrum environments under different settings and obtain various performance data on different metrics. Then we apply factor analysis on the performance data to identify and quantize the intelligence factors and cognitive capabilities of the CR. More specifically, we present a case study consisting of 144 different types of CRs. The CRs are different in terms of learning-based dynamic spectrum access strategies, number of sensors, sensing accuracy, processing speed, and algorithmic complexity. Five intelligence factors are identified for the CRs through our data analysis.We show that these factors comply well with the nature of the tested CRs, which validates the proposed intelligence measure methodology.
Online Learning with Randomized Feedback Graphs for Optimal PUE Attacks in Cognitive Radio Networks
Mar 19, 2018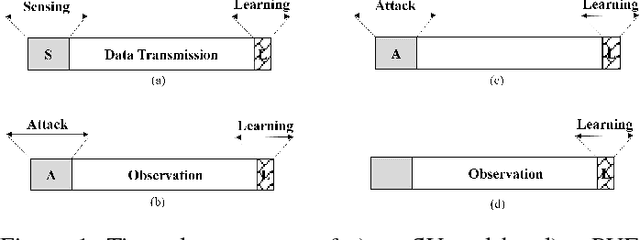
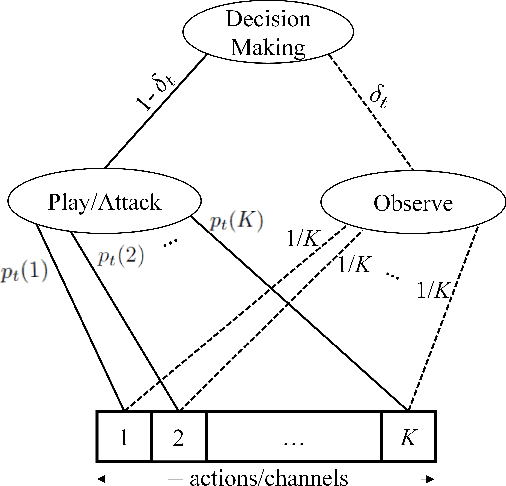
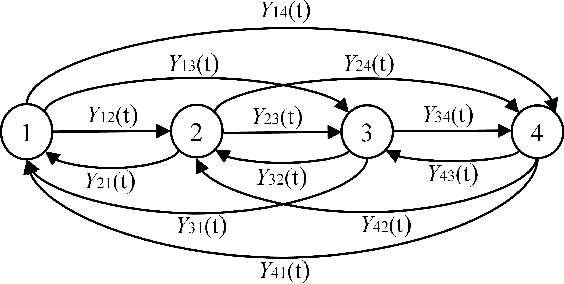
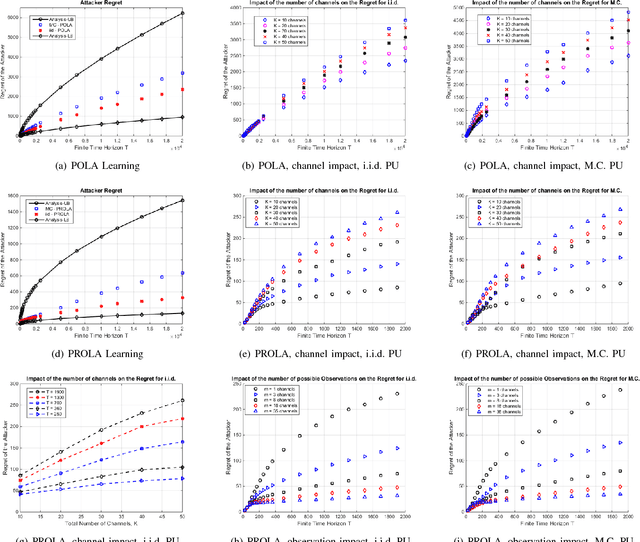
In a cognitive radio network, a secondary user learns the spectrum environment and dynamically accesses the channel where the primary user is inactive. At the same time, a primary user emulation (PUE) attacker can send falsified primary user signals and prevent the secondary user from utilizing the available channel. The best attacking strategies that an attacker can apply have not been well studied. In this paper, for the first time, we study optimal PUE attack strategies by formulating an online learning problem where the attacker needs to dynamically decide the attacking channel in each time slot based on its attacking experience. The challenge in our problem is that since the PUE attack happens in the spectrum sensing phase, the attacker cannot observe the reward on the attacked channel. To address this challenge, we utilize the attacker's observation capability. We propose online learning-based attacking strategies based on the attacker's observation capabilities. Through our analysis, we show that with no observation within the attacking slot, the attacker loses on the regret order, and with the observation of at least one channel, there is a significant improvement on the attacking performance. Observation of multiple channels does not give additional benefit to the attacker (only a constant scaling) though it gives insight on the number of observations required to achieve the minimum constant factor. Our proposed algorithms are optimal in the sense that their regret upper bounds match their corresponding regret lower-bounds. We show consistency between simulation and analytical results under various system parameters.