 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA meta-probabilistic-programming language for bisimulation of probabilistic and non-well-founded type systems
Mar 30, 2022

We introduce a formal meta-language for probabilistic programming, capable of expressing both programs and the type systems in which they are embedded. We are motivated here by the desire to allow an AGI to learn not only relevant knowledge (programs/proofs), but also appropriate ways of reasoning (logics/type systems). We draw on the frameworks of cubical type theory and dependent typed metagraphs to formalize our approach. In doing so, we show that specific constructions within the meta-language can be related via bisimulation (implying path equivalence) to the type systems they correspond. In doing so, our approach provides a convenient means of deriving synthetic denotational semantics for various type systems. Particularly, we derive bisimulations for pure type systems (PTS), and probabilistic dependent type systems (PDTS). We discuss further the relationship of PTS to non-well-founded set theory.
GoodPoint: unsupervised learning of keypoint detection and description
Jun 01, 2020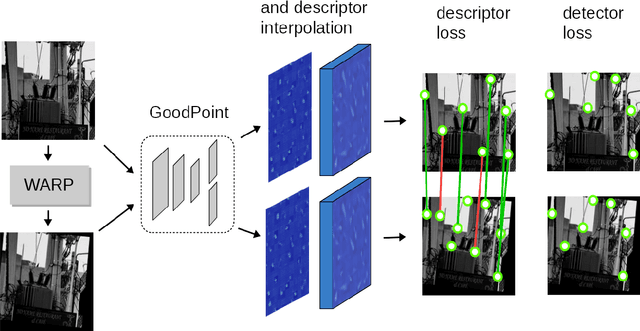
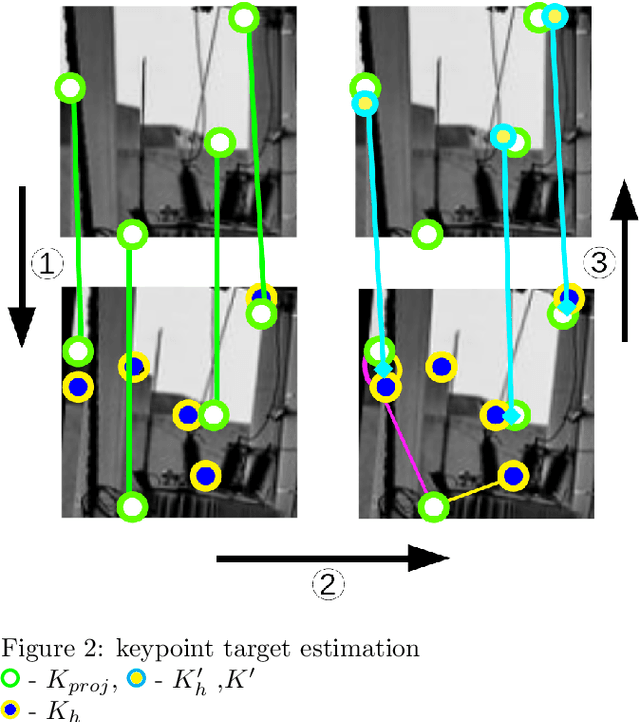
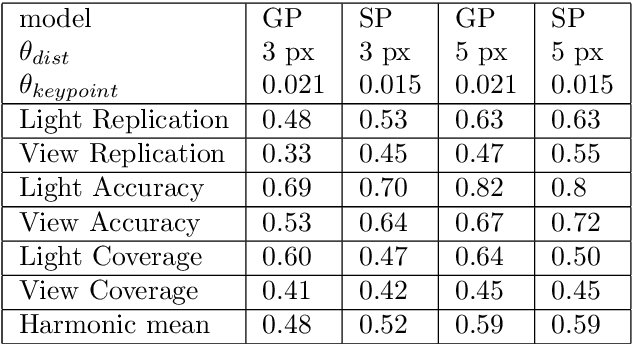
This paper introduces a new algorithm for unsupervised learning of keypoint detectors and descriptors, which demonstrates fast convergence and good performance across different datasets. The training procedure uses homographic transformation of images. The proposed model learns to detect points and generate descriptors on pairs of transformed images, which are easy for it to distinguish and repeatedly detect. The trained model follows SuperPoint architecture for ease of comparison, and demonstrates similar performance on natural images from HPatches dataset, and better performance on retina images from Fundus Image Registration Dataset, which contain low number of corner-like features. For HPatches and other datasets, coverage was also computed to provide better estimation of model quality.
Differentiable Probabilistic Logic Networks
Jul 10, 2019Probabilistic logic reasoning is a central component of such cognitive architectures as OpenCog. However, as an integrative architecture, OpenCog facilitates cognitive synergy via hybridization of different inference methods. In this paper, we introduce a differentiable version of Probabilistic Logic networks, which rules operate over tensor truth values in such a way that a chain of reasoning steps constructs a computation graph over tensors that accepts truth values of premises from the knowledge base as input and produces truth values of conclusions as output. This allows for both learning truth values of premises and formulas for rules (specified in a form with trainable weights) by backpropagation combining subsymbolic optimization and symbolic reasoning.
Improving Deep Models of Person Re-identification for Cross-Dataset Usage
Jul 23, 2018
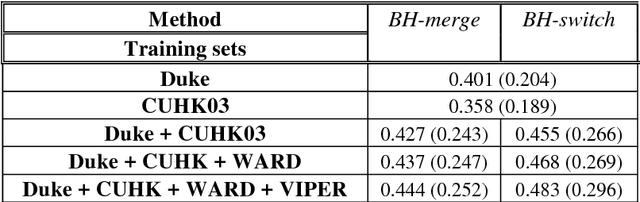
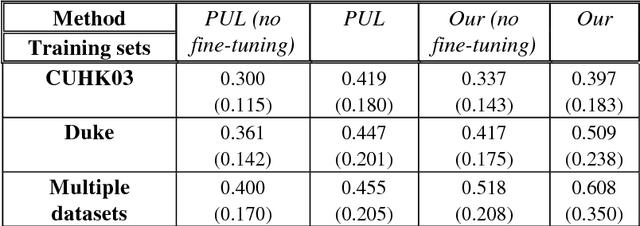
Person re-identification (Re-ID) is the task of matching humans across cameras with non-overlapping views that has important applications in visual surveillance. Like other computer vision tasks, this task has gained much with the utilization of deep learning methods. However, existing solutions based on deep learning are usually trained and tested on samples taken from same datasets, while in practice one need to deploy Re-ID systems for new sets of cameras for which labeled data is unavailable. Here, we mitigate this problem for one state-of-the-art model, namely, metric embedding trained with the use of the triplet loss function, although our results can be extended to other models. The contribution of our work consists in developing a method of training the model on multiple datasets, and a method for its online practically unsupervised fine-tuning. These methods yield up to 19.1% improvement in Rank-1 score in the cross-dataset evaluation.
Genetic algorithms with DNN-based trainable crossover as an example of partial specialization of general search
Jul 18, 2018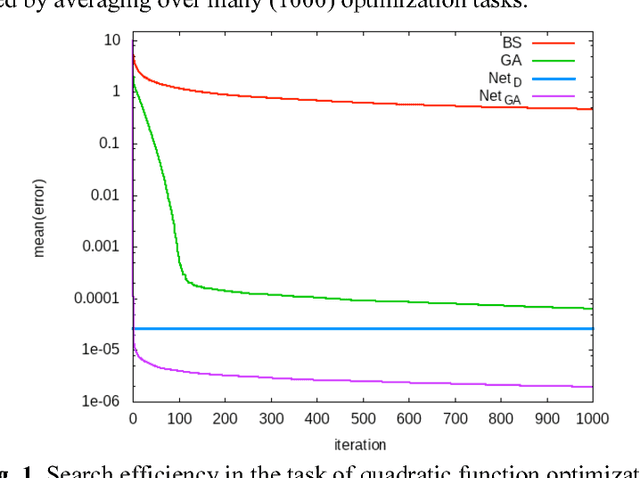
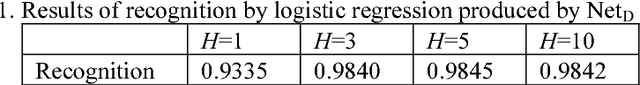

Universal induction relies on some general search procedure that is doomed to be inefficient. One possibility to achieve both generality and efficiency is to specialize this procedure w.r.t. any given narrow task. However, complete specialization that implies direct mapping from the task parameters to solutions (discriminative models) without search is not always possible. In this paper, partial specialization of general search is considered in the form of genetic algorithms (GAs) with a specialized crossover operator. We perform a feasibility study of this idea implementing such an operator in the form of a deep feedforward neural network. GAs with trainable crossover operators are compared with the result of complete specialization, which is also represented as a deep neural network. Experimental results show that specialized GAs can be more efficient than both general GAs and discriminative models.
Metric Embedding Autoencoders for Unsupervised Cross-Dataset Transfer Learning
Jul 18, 2018

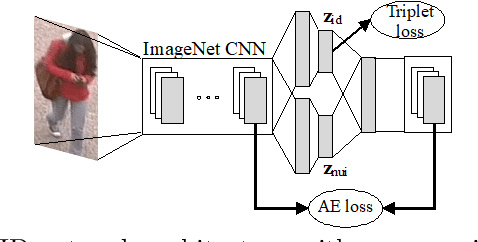
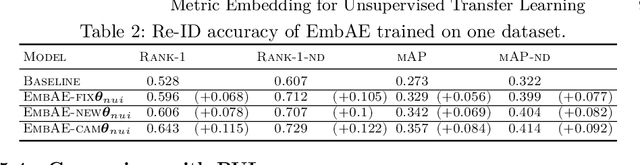
Cross-dataset transfer learning is an important problem in person re-identification (Re-ID). Unfortunately, not too many deep transfer Re-ID models exist for realistic settings of practical Re-ID systems. We propose a purely deep transfer Re-ID model consisting of a deep convolutional neural network and an autoencoder. The latent code is divided into metric embedding and nuisance variables. We then utilize an unsupervised training method that does not rely on co-training with non-deep models. Our experiments show improvements over both the baseline and competitors' transfer learning models.
HyperNets and their application to learning spatial transformations
Jul 12, 2018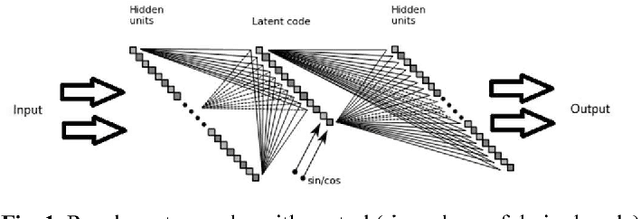

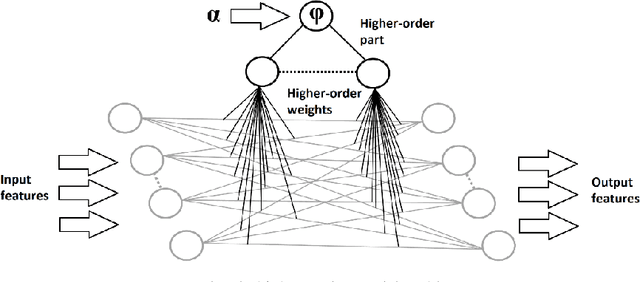
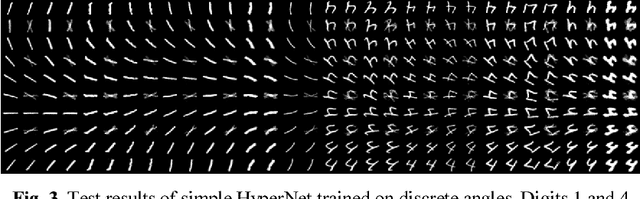
In this paper we propose a conceptual framework for higher-order artificial neural networks. The idea of higher-order networks arises naturally when a model is required to learn some group of transformations, every element of which is well-approximated by a traditional feedforward network. Thus the group as a whole can be represented as a hyper network. One of typical examples of such groups is spatial transformations. We show that the proposed framework, which we call HyperNets, is able to deal with at least two basic spatial transformations of images: rotation and affine transformation. We show that HyperNets are able not only to generalize rotation and affine transformation, but also to compensate the rotation of images bringing them into canonical forms.
Vision System for AGI: Problems and Directions
Jul 10, 2018What frameworks and architectures are necessary to create a vision system for AGI? In this paper, we propose a formal model that states the task of perception within AGI. We show the role of discriminative and generative models in achieving efficient and general solution of this task, thus specifying the task in more detail. We discuss some existing generative and discriminative models and demonstrate their insufficiency for our purposes. Finally, we discuss some architectural dilemmas and open questions.
Semantic Image Retrieval by Uniting Deep Neural Networks and Cognitive Architectures
Jun 14, 2018
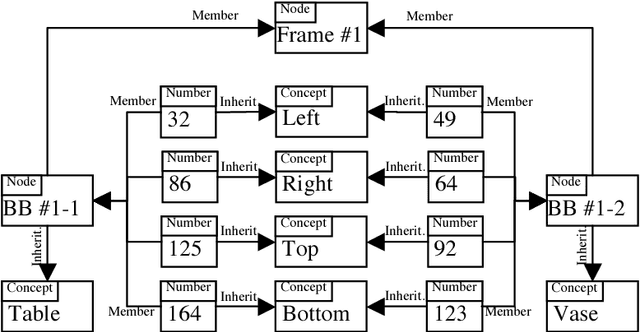
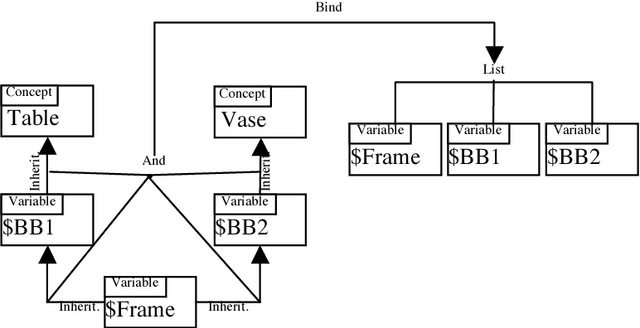

Image and video retrieval by their semantic content has been an important and challenging task for years, because it ultimately requires bridging the symbolic/subsymbolic gap. Recent successes in deep learning enabled detection of objects belonging to many classes greatly outperforming traditional computer vision techniques. However, deep learning solutions capable of executing retrieval queries are still not available. We propose a hybrid solution consisting of a deep neural network for object detection and a cognitive architecture for query execution. Specifically, we use YOLOv2 and OpenCog. Queries allowing the retrieval of video frames containing objects of specified classes and specified spatial arrangement are implemented.
A Step from Probabilistic Programming to Cognitive Architectures
May 04, 2016Probabilistic programming is considered as a framework, in which basic components of cognitive architectures can be represented in unified and elegant fashion. At the same time, necessity of adopting some component of cognitive architectures for extending capabilities of probabilistic programming languages is pointed out. In particular, implicit specification of generative models via declaration of concepts and links between them is proposed, and usefulness of declarative knowledge for achieving efficient inference is briefly discussed.