 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodPoint: unsupervised learning of keypoint detection and description
Paper and Code
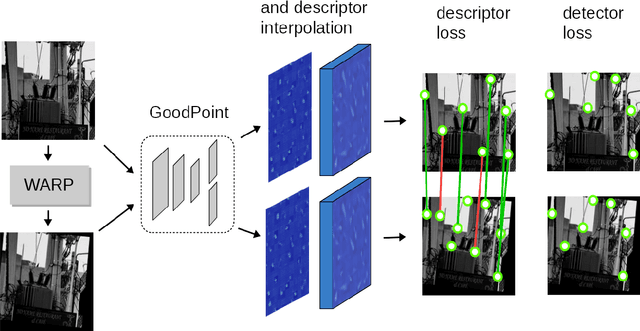
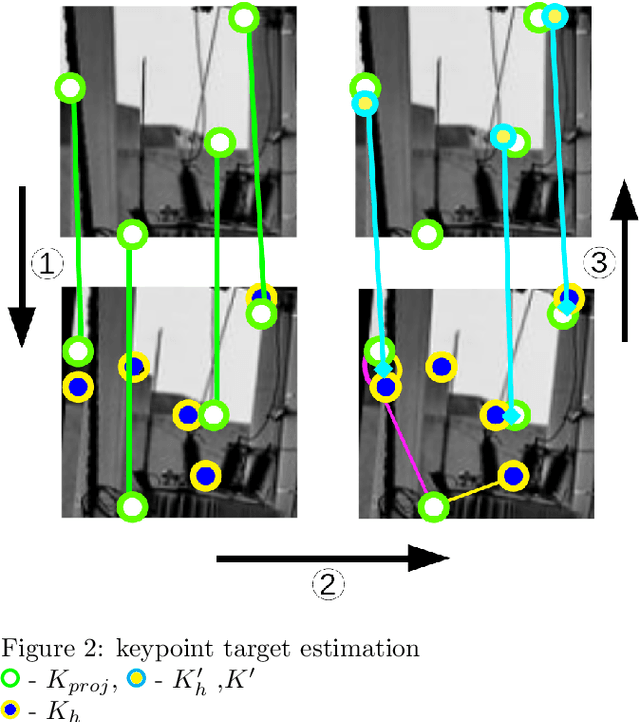
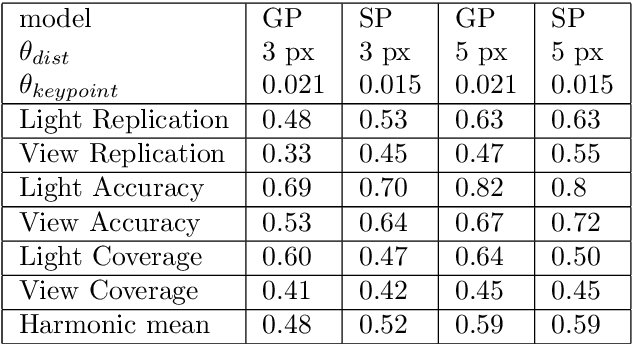
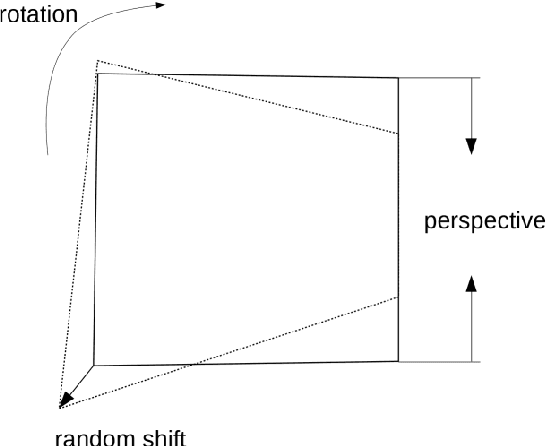
This paper introduces a new algorithm for unsupervised learning of keypoint detectors and descriptors, which demonstrates fast convergence and good performance across different datasets. The training procedure uses homographic transformation of images. The proposed model learns to detect points and generate descriptors on pairs of transformed images, which are easy for it to distinguish and repeatedly detect. The trained model follows SuperPoint architecture for ease of comparison, and demonstrates similar performance on natural images from HPatches dataset, and better performance on retina images from Fundus Image Registration Dataset, which contain low number of corner-like features. For HPatches and other datasets, coverage was also computed to provide better estimation of model quality.