 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Models of Person Re-identification for Cross-Dataset Usage
Jul 23, 2018
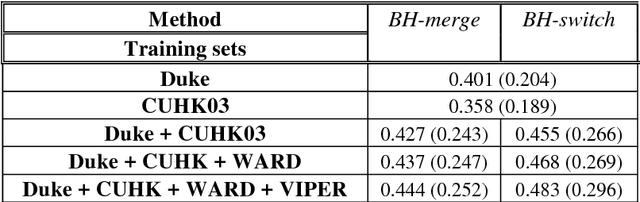
Person re-identification (Re-ID) is the task of matching humans across cameras with non-overlapping views that has important applications in visual surveillance. Like other computer vision tasks, this task has gained much with the utilization of deep learning methods. However, existing solutions based on deep learning are usually trained and tested on samples taken from same datasets, while in practice one need to deploy Re-ID systems for new sets of cameras for which labeled data is unavailable. Here, we mitigate this problem for one state-of-the-art model, namely, metric embedding trained with the use of the triplet loss function, although our results can be extended to other models. The contribution of our work consists in developing a method of training the model on multiple datasets, and a method for its online practically unsupervised fine-tuning. These methods yield up to 19.1% improvement in Rank-1 score in the cross-dataset evaluation.
Metric Embedding Autoencoders for Unsupervised Cross-Dataset Transfer Learning
Jul 18, 2018

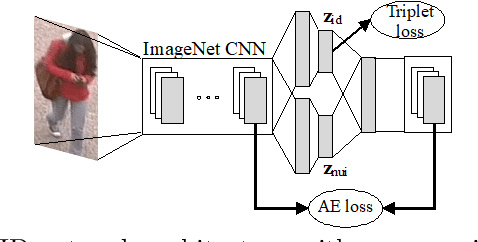
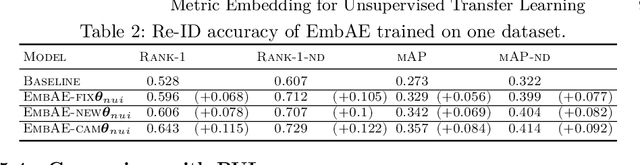
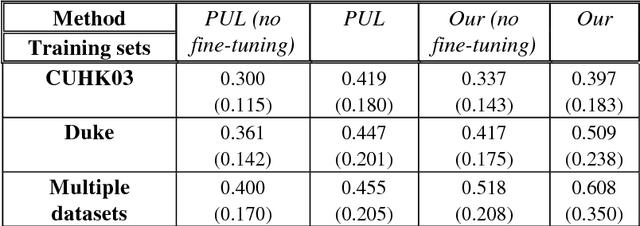
Cross-dataset transfer learning is an important problem in person re-identification (Re-ID). Unfortunately, not too many deep transfer Re-ID models exist for realistic settings of practical Re-ID systems. We propose a purely deep transfer Re-ID model consisting of a deep convolutional neural network and an autoencoder. The latent code is divided into metric embedding and nuisance variables. We then utilize an unsupervised training method that does not rely on co-training with non-deep models. Our experiments show improvements over both the baseline and competitors' transfer learning models.
Semantic Image Retrieval by Uniting Deep Neural Networks and Cognitive Architectures
Jun 14, 2018
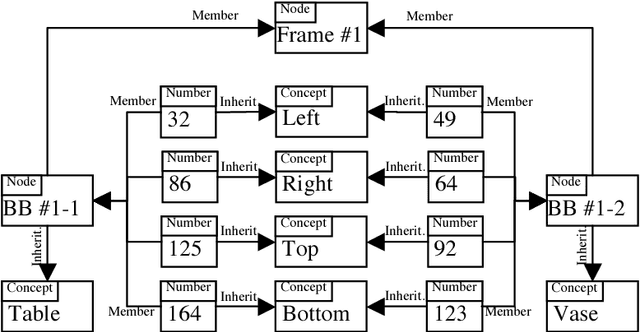
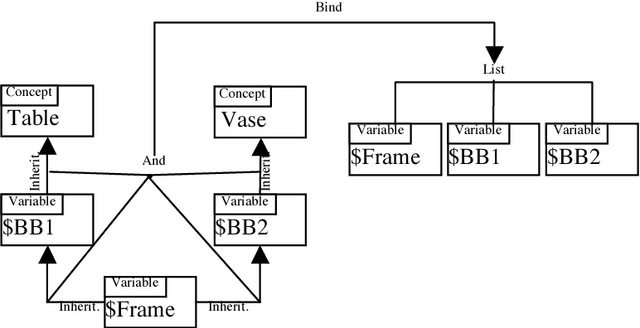

Image and video retrieval by their semantic content has been an important and challenging task for years, because it ultimately requires bridging the symbolic/subsymbolic gap. Recent successes in deep learning enabled detection of objects belonging to many classes greatly outperforming traditional computer vision techniques. However, deep learning solutions capable of executing retrieval queries are still not available. We propose a hybrid solution consisting of a deep neural network for object detection and a cognitive architecture for query execution. Specifically, we use YOLOv2 and OpenCog. Queries allowing the retrieval of video frames containing objects of specified classes and specified spatial arrangement are implemented.