 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetensorFM: Low-Rank Approximations of Cross-Order Feature Interactions
Feb 16, 2026We address prediction problems on tabular categorical data, where each instance is defined by multiple categorical attributes, each taking values from a finite set. These attributes are often referred to as fields, and their categorical values as features. Such problems frequently arise in practical applications, including click-through rate prediction and social sciences. We introduce and analyze {tensorFM}, a new model that efficiently captures high-order interactions between attributes via a low-rank tensor approximation representing the strength of these interactions. Our model generalizes field-weighted factorization machines. Empirically, tensorFM demonstrates competitive performance with state-of-the-art methods. Additionally, its low latency makes it well-suited for time-sensitive applications, such as online advertising.
LiveRAG: A diverse Q&A dataset with varying difficulty level for RAG evaluation
Nov 18, 2025
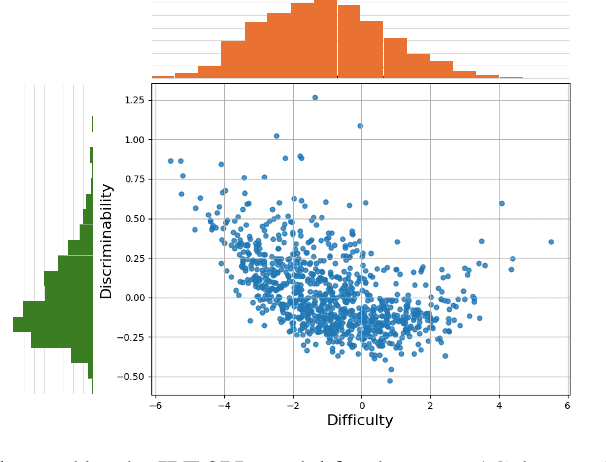
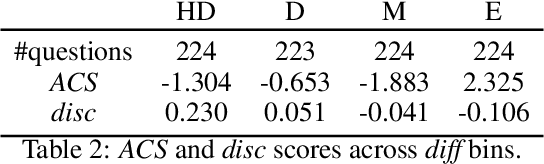
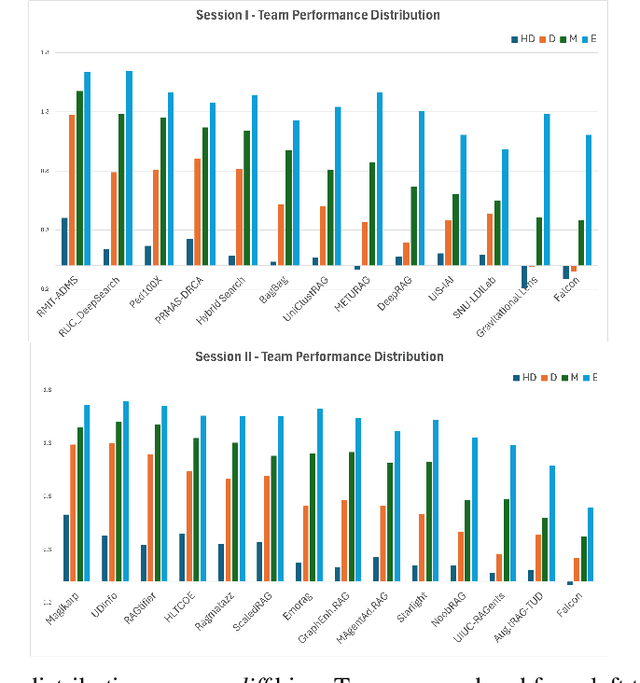
With Retrieval Augmented Generation (RAG) becoming more and more prominent in generative AI solutions, there is an emerging need for systematically evaluating their effectiveness. We introduce the LiveRAG benchmark, a publicly available dataset of 895 synthetic questions and answers designed to support systematic evaluation of RAG-based Q&A systems. This synthetic benchmark is derived from the one used during the SIGIR'2025 LiveRAG Challenge, where competitors were evaluated under strict time constraints. It is augmented with information that was not made available to competitors during the Challenge, such as the ground-truth answers, together with their associated supporting claims which were used for evaluating competitors' answers. In addition, each question is associated with estimated difficulty and discriminability scores, derived from applying an Item Response Theory model to competitors' responses. Our analysis highlights the benchmark's questions diversity, the wide range of their difficulty levels, and their usefulness in differentiating between system capabilities. The LiveRAG benchmark will hopefully help the community advance RAG research, conduct systematic evaluation, and develop more robust Q&A systems.
Continuous Monitoring via Repeated Significance
Aug 05, 2024Requiring statistical significance at multiple interim analyses to declare a statistically significant result for an AB test allows less stringent requirements for significance at each interim analysis. Repeated repeated significance competes well with methods built on assumptions about the test -- assumptions that may be impossible to evaluate a priori and may require extra data to evaluate empirically. Instead, requiring repeated significance allows the data itself to prove directly that the required results are not due to chance alone. We explain how to apply tests with repeated significance to continuously monitor unbounded tests -- tests that do not have an a priori bound on running time or number of observations. We show that it is impossible to maintain a constant requirement for significance for unbounded tests, but that we can come arbitrarily close to that goal.
Early Stopping Based on Repeated Significance
Aug 01, 2024For a bucket test with a single criterion for success and a fixed number of samples or testing period, requiring a $p$-value less than a specified value of $\alpha$ for the success criterion produces statistical confidence at level $1 - \alpha$. For multiple criteria, a Bonferroni correction that partitions $\alpha$ among the criteria produces statistical confidence, at the cost of requiring lower $p$-values for each criterion. The same concept can be applied to decisions about early stopping, but that can lead to strict requirements for $p$-values. We show how to address that challenge by requiring criteria to be successful at multiple decision points.
Low Rank Field-Weighted Factorization Machines for Low Latency Item Recommendation
Jul 22, 2024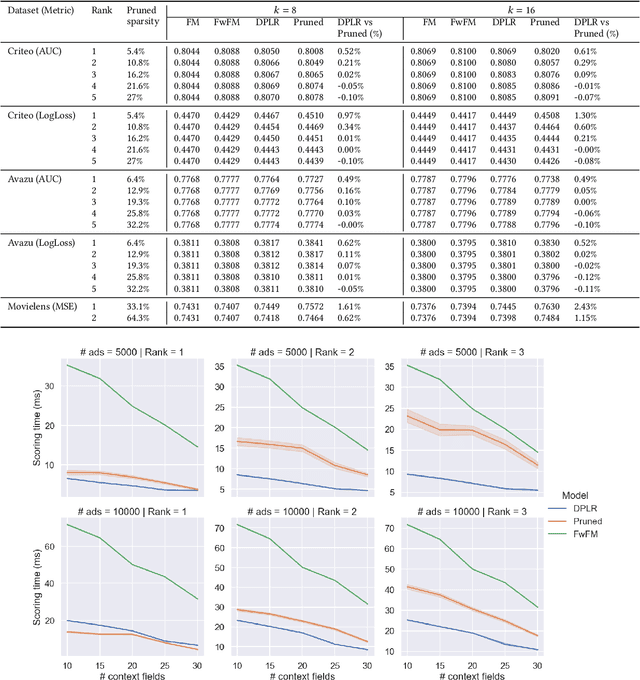
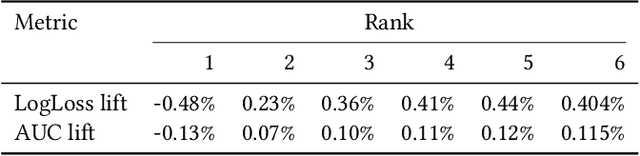
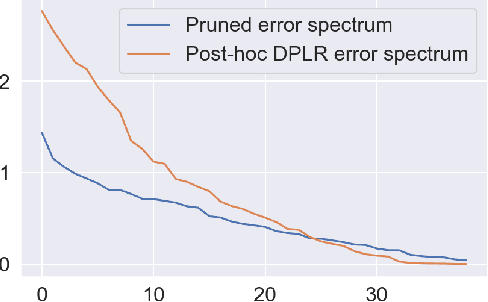

Factorization machine (FM) variants are widely used in recommendation systems that operate under strict throughput and latency requirements, such as online advertising systems. FMs are known both due to their ability to model pairwise feature interactions while being resilient to data sparsity, and their computational graphs that facilitate fast inference and training. Moreover, when items are ranked as a part of a query for each incoming user, these graphs facilitate computing the portion stemming from the user and context fields only once per query. Consequently, in terms of inference cost, the number of user or context fields is practically unlimited. More advanced FM variants, such as FwFM, provide better accuracy by learning a representation of field-wise interactions, but require computing all pairwise interaction terms explicitly. The computational cost during inference is proportional to the square of the number of fields, including user, context, and item. When the number of fields is large, this is prohibitive in systems with strict latency constraints. To mitigate this caveat, heuristic pruning of low intensity field interactions is commonly used to accelerate inference. In this work we propose an alternative to the pruning heuristic in FwFMs using a diagonal plus symmetric low-rank decomposition. Our technique reduces the computational cost of inference, by allowing it to be proportional to the number of item fields only. Using a set of experiments on real-world datasets, we show that aggressive rank reduction outperforms similarly aggressive pruning, both in terms of accuracy and item recommendation speed. We corroborate our claim of faster inference experimentally, both via a synthetic test, and by having deployed our solution to a major online advertising system. The code to reproduce our experimental results is at https://github.com/michaelviderman/pytorch-fm/tree/dev.
Improving conversion rate prediction via self-supervised pre-training in online advertising
Jan 25, 2024The task of predicting conversion rates (CVR) lies at the heart of online advertising systems aiming to optimize bids to meet advertiser performance requirements. Even with the recent rise of deep neural networks, these predictions are often made by factorization machines (FM), especially in commercial settings where inference latency is key. These models are trained using the logistic regression framework on labeled tabular data formed from past user activity that is relevant to the task at hand. Many advertisers only care about click-attributed conversions. A major challenge in training models that predict conversions-given-clicks comes from data sparsity - clicks are rare, conversions attributed to clicks are even rarer. However, mitigating sparsity by adding conversions that are not click-attributed to the training set impairs model calibration. Since calibration is critical to achieving advertiser goals, this is infeasible. In this work we use the well-known idea of self-supervised pre-training, and use an auxiliary auto-encoder model trained on all conversion events, both click-attributed and not, as a feature extractor to enrich the main CVR prediction model. Since the main model does not train on non click-attributed conversions, this does not impair calibration. We adapt the basic self-supervised pre-training idea to our online advertising setup by using a loss function designed for tabular data, facilitating continual learning by ensuring auto-encoder stability, and incorporating a neural network into a large-scale real-time ad auction that ranks tens of thousands of ads, under strict latency constraints, and without incurring a major engineering cost. We show improvements both offline, during training, and in an online A/B test. Following its success in A/B tests, our solution is now fully deployed to the Yahoo native advertising system.
Unbiased Filtering Of Accidental Clicks in Verizon Media Native Advertising
Dec 08, 2023Verizon Media (VZM) native advertising is one of VZM largest and fastest growing businesses, reaching a run-rate of several hundred million USDs in the past year. Driving the VZM native models that are used to predict event probabilities, such as click and conversion probabilities, is OFFSET - a feature enhanced collaborative-filtering based event-prediction algorithm. In this work we focus on the challenge of predicting click-through rates (CTR) when we are aware that some of the clicks have short dwell-time and are defined as accidental clicks. An accidental click implies little affinity between the user and the ad, so predicting that similar users will click on the ad is inaccurate. Therefore, it may be beneficial to remove clicks with dwell-time lower than a predefined threshold from the training set. However, we cannot ignore these positive events, as filtering these will cause the model to under predict. Previous approaches have tried to apply filtering and then adding corrective biases to the CTR predictions, but did not yield revenue lifts and therefore were not adopted. In this work, we present a new approach where the positive weight of the accidental clicks is distributed among all of the negative events (skips), based on their likelihood of causing accidental clicks, as predicted by an auxiliary model. These likelihoods are taken as the correct labels of the negative events, shifting our training from using only binary labels and adopting a binary cross-entropy loss function in our training process. After showing offline performance improvements, the modified model was tested online serving VZM native users, and provided 1.18% revenue lift over the production model which is agnostic to accidental clicks.
Basis Function Encoding of Numerical Features in Factorization Machines for Improved Accuracy
May 23, 2023Factorization machine (FM) variants are widely used for large scale real-time content recommendation systems, since they offer an excellent balance between model accuracy and low computational costs for training and inference. These systems are trained on tabular data with both numerical and categorical columns. Incorporating numerical columns poses a challenge, and they are typically incorporated using a scalar transformation or binning, which can be either learned or chosen a-priori. In this work, we provide a systematic and theoretically-justified way to incorporate numerical features into FM variants by encoding them into a vector of function values for a set of functions of one's choice. We view factorization machines as approximators of segmentized functions, namely, functions from a field's value to the real numbers, assuming the remaining fields are assigned some given constants, which we refer to as the segment. From this perspective, we show that our technique yields a model that learns segmentized functions of the numerical feature spanned by the set of functions of one's choice, namely, the spanning coefficients vary between segments. Hence, to improve model accuracy we advocate the use of functions known to have strong approximation power, and offer the B-Spline basis due to its well-known approximation power, availability in software libraries, and efficiency. Our technique preserves fast training and inference, and requires only a small modification of the computational graph of an FM model. Therefore, it is easy to incorporate into an existing system to improve its performance. Finally, we back our claims with a set of experiments, including synthetic, performance evaluation on several data-sets, and an A/B test on a real online advertising system which shows improved performance.
Conversion-Based Dynamic-Creative-Optimization in Native Advertising
Nov 13, 2022Yahoo Gemini native advertising marketplace serves billions of impressions daily, to hundreds millions of unique users, and reaches a yearly revenue of many hundreds of millions USDs. Powering Gemini native models for predicting advertise (ad) event probabilities, such as conversions and clicks, is OFFSET - a feature enhanced collaborative-filtering (CF) based event prediction algorithm. The predicted probabilities are then used in Gemini native auctions to determine which ads to present for every serving event (impression). Dynamic creative optimization (DCO) is a recent Gemini native product that was launched two years ago and is increasingly gaining more attention from advertisers. The DCO product enables advertisers to issue several assets per each native ad attribute, creating multiple combinations for each DCO ad. Since different combinations may appeal to different crowds, it may be beneficial to present certain combinations more frequently than others to maximize revenue while keeping advertisers and users satisfied. The initial DCO offer was to optimize click-through rates (CTR), however as the marketplace shifts more towards conversion based campaigns, advertisers also ask for a {conversion based solution. To accommodate this request, we present a post-auction solution, where DCO ads combinations are favored according to their predicted conversion rate (CVR). The predictions are provided by an auxiliary OFFSET based combination CVR prediction model, and used to generate the combination distributions for DCO ad rendering during serving time. An online evaluation of this explore-exploit solution, via online bucket A/B testing, serving Gemini native DCO traffic, showed a 53.5% CVR lift, when compared to a control bucket serving all combinations uniformly at random.
Efficient implementation of incremental proximal-point methods
May 03, 2022

Model training algorithms which observe a small portion of the training set in each computational step are ubiquitous in practical machine learning, and include both stochastic and online optimization methods. In the vast majority of cases, such algorithms typically observe the training samples via the gradients of the cost functions the samples incur. Thus, these methods exploit are the \emph{slope} of the cost functions via their first-order approximations. To address limitations of gradient-based methods, such as sensitivity to step-size choice in the stochastic setting, or inability to exploit small function variability in the online setting, several streams of research attempt to exploit more information about the cost functions than just their gradients via the well-known proximal framework of optimization. However, implementing such methods in practice poses a challenge, since each iteration step boils down to computing a proximal operator, which may not be easy. In this work we provide efficient algorithms and corresponding implementations of proximal operators in order to make experimentation with incremental proximal optimization algorithms accessible to a larger audience of researchers and practitioners, and in particular to promote additional theoretical research into these methods by closing the gap between their theoretical description in research papers and their use in practice. The corresponding code is published at https://github.com/alexshtf/inc_prox_pt.